Après plusieurs années de retard, on pourrait se dire qu’on n’est plus à quelques jours près. La capsule habitable Starliner de Boeing qui doit concurrencer Crew Dragon de SpaceX n’a toujours pas décollé. Le lancement est entaché de plusieurs problèmes depuis des années.
C’était au début une vanne sur l’étage supérieur du lanceur (Atlas V), qui a été réparée et testée. Mais dans la foulée, une petite fuite d’hélium a été détectée dans le module de service de la capsule. « L’hélium est utilisé dans les systèmes de propulseurs des engins spatiaux pour permettre aux propulseurs de s’allumer et n’est ni combustible ni toxique », précise Boeing.
« Les équipes visent maintenant une date de lancement au plus tôt à 22h43 le mardi 21 mai, pour effectuer des tests supplémentaires ». Atlas V et Starliner restent pour l’instant en place (à la verticale) dans le lancement spatial-41. Les astronautes sont pour le moment retournés avec leur famille à Houston, ajoute la NASA.
Boeing est actuellement confronté à une série noire avec ses avions, avec une multiplication des incidents. Les retards et les problèmes à répétition de Starliner viennent s’ajouter, sans oublier Elon Musk qui en profite pour tacler allègrement le retard de son concurrent.
Au début de l’année, AMD lançait ses APU Ryzen de la série 8000G, des CPU avec une partie graphique intégrée, contrairement à la série 7000. Voilà qu’AMD a décidé de lancer deux nouvelles références se terminant pas un F. Vous l’aurez certainement compris, il s’agit de processeurs sans partie graphique.
Le Ryzen 5 8400F dispose de 6 cœurs (4,2 GHz, 4,7 GHz en boost) et 12 threads, contre 8 cœurs (4,1 GHz, 5 GHz en boost) et 16 threads pour le Ryzen 7 8700F. Cette fois, AMD ne mélange pas les architectures Zen 4 et 4C puisque tous les cœurs sont des Zen 4. Pour le reste, ils reprennent les caractéristiques techniques de la série 8000, notamment l’impasse sur le PCIe 5.0 pour n’avoir que 16 lignes PCIe 4.0 utilisables.
Seul le Ryzen 7 8700F dispose du moteur Ryzen AI pour les calculs liés à l’intelligence artificielle. Celui-ci n’est disponible que s’il « est associé à une carte graphique Radeon compatible avec accélération AI », précise AMD.
Le Ryzen 5 8400F est vendu aux alentours de 210 euros chez les revendeurs mis en avant par AMD, contre 330 euros pour le Ryzen 7 8700F.
Le Ryzen 5 8400F se place donc en face du Ryzen 5 7600X (fréquence plus rapide, cache L3 plus important et PCIe 5.0) et même au-dessus du Ryzen 5 7600 que l’on trouve à un peu plus de 200 euros.
Nous avons actualisé notre tableau comparatif des processeurs Ryzen avec une architecture Zen 4 pour le grand public (socket AM5) :
Après plusieurs années de retard, on pourrait se dire qu’on n’est plus à quelques jours près. La capsule habitable Starliner de Boeing qui doit concurrencer Crew Dragon de SpaceX n’a toujours pas décollé. Le lancement est entaché de plusieurs problèmes depuis des années.
C’était au début une vanne sur l’étage supérieur du lanceur (Atlas V), qui a été réparée et testée. Mais dans la foulée, une petite fuite d’hélium a été détectée dans le module de service de la capsule. « L’hélium est utilisé dans les systèmes de propulseurs des engins spatiaux pour permettre aux propulseurs de s’allumer et n’est ni combustible ni toxique », précise Boeing.
« Les équipes visent maintenant une date de lancement au plus tôt à 22h43 le mardi 21 mai, pour effectuer des tests supplémentaires ». Atlas V et Starliner restent pour l’instant en place (à la verticale) dans le lancement spatial-41. Les astronautes sont pour le moment retournés avec leur famille à Houston, ajoute la NASA.
Boeing est actuellement confronté à une série noire avec ses avions, avec une multiplication des incidents. Les retards et les problèmes à répétition de Starliner viennent s’ajouter, sans oublier Elon Musk qui en profite pour tacler allègrement le retard de son concurrent.
Au début de l’année, AMD lançait ses APU Ryzen de la série 8000G, des CPU avec une partie graphique intégrée, contrairement à la série 7000. Voilà qu’AMD a décidé de lancer deux nouvelles références se terminant pas un F. Vous l’aurez certainement compris, il s’agit de processeurs sans partie graphique.
Le Ryzen 5 8400F dispose de 6 cœurs (4,2 GHz, 4,7 GHz en boost) et 12 threads, contre 8 cœurs (4,1 GHz, 5 GHz en boost) et 16 threads pour le Ryzen 7 8700F. Cette fois, AMD ne mélange pas les architectures Zen 4 et 4C puisque tous les cœurs sont des Zen 4. Pour le reste, ils reprennent les caractéristiques techniques de la série 8000, notamment l’impasse sur le PCIe 5.0 pour n’avoir que 16 lignes PCIe 4.0 utilisables.
Seul le Ryzen 7 8700F dispose du moteur Ryzen AI pour les calculs liés à l’intelligence artificielle. Celui-ci n’est disponible que s’il « est associé à une carte graphique Radeon compatible avec accélération AI », précise AMD.
Le Ryzen 5 8400F est vendu aux alentours de 210 euros chez les revendeurs mis en avant par AMD, contre 330 euros pour le Ryzen 7 8700F.
Le Ryzen 5 8400F se place donc en face du Ryzen 5 7600X (fréquence plus rapide, cache L3 plus important et PCIe 5.0) et même au-dessus du Ryzen 5 7600 que l’on trouve à un peu plus de 200 euros.
Nous avons actualisé notre tableau comparatif des processeurs Ryzen avec une architecture Zen 4 pour le grand public (socket AM5) :
Les Tensor Processing Unit sont des puces développées par Google pour l’intelligence artificielle, de l’entraînement à l’inférence. La société vient d’annoncer sa sixième génération, qu’elle présente comme 4,7x plus performante que la génération précédente.
Hier, lors de la keynote d‘ouverture de la conférence I/O, Google a tiré tous azimuts sur l’intelligence artificielle (nous y reviendrons). La société s’en amuse elle-même avec un décompte officiel : durant son discours, Sundar Pichai y a fait référence pas moins de 121 fois, c’est du moins le décompte fait par… une IA.
Mais pour utiliser des intelligences artificielles, il faut des machines capables de les entrainer et de les faire tourner. Si NVIDIA et ses GPU règnent en maitres sur le haut du panier dans le monde des datacenters, de nombreuses autres sociétés développent leurs propres puces. C’est le cas de Google avec ses Tensor Processing Unit (TPU). Il s’agit d’ASIC (circuits intégrés spécifiques aux applications) conçus « pour accélérer les charges de travail de machine learning ».
La sixième génération a été annoncée hier. Elle devrait logiquement s’appeler TPU v6, mais Google n’utilise pas cette appellation dans son communiqué. L’entreprise se contente d’un nom de code : Trillium. Comme nous l’avions déjà détaillé, la précédente génération comportait deux versions : v5e et v5p. Les premières visent le meilleur rapport performances/prix, tandis que les secondes (lancées plus tard) misent tout sur les performances.
Bien évidemment, Google compare sa sixième génération de TPU aux v5e, pas aux V5p. Il est ainsi question d’un maximum de « 4,7 fois plus » de performances par puce, sans savoir à quoi cela correspond exactement.
Si on se base sur les 197 TFLOP du v5e en blfoat16, on arriverait à un maximum théorique de 926 TFLOP, soit deux fois plus que les performances du v5p. Mais le 4.7x pourrait aussi renvoyer à un cas particulier, impossible donc en l’état d’en savoir plus.
Quoi qu’il en soit, pour arriver à cette hausse des performances, Google explique avoir augmenté la taille de ses unités de multiplication matricielle (MXU) et la fréquence d’horloge de sa puce, sans préciser dans quelles mesures.
Bande passante HBM et ICI doublée
Google annonce aussi avoir « doublé la capacité et la bande passante de la mémoire HBM, ainsi que la bande passante Interchip Interconnect (ICI) par rapport au TPU v5e ». On passerait ainsi à 1 638 Go/s sur la mémoire (en prenant 819 Go/s pour le v5e) , ce qui reste en dessous des 2 765 Go/s du v5p.
La bande passante de l’ICI est de 1 600 Gb/s sur v5e, on doit donc arriver à 3 200 Gb/s sur Trillium (TPU v6), contre 4 800 Gb/s sur v5p.
Pour en terminer avec les chiffres, Google affirme que son TPU Trillium est « plus de 67 % plus économe en énergie que le v5e ». Mais comme l’entreprise ne donne pas de chiffre sur la consommation, impossible d’en savoir plus.
« Trillium est équipé de la troisième génération de SparseCore», un accélérateur permettant « d’accélérer l’intégration de charges de travail lourdes ». Google affirme que ses TPU Trillium « permettent de former plus rapidement la prochaine vague de modèles et de servir les modèles avec une latence réduite et un coût moindre ». Une phrase que l’on peut ressortir à chaque nouvelle génération.
Jusqu’à 256 TPU Trillium par pod
Ces TPU de la génération Trillium peuvent être assemblée par paquet de 256 pour former un pod, exactement comme les v5e. Les v5p peuvent s’agglutiner par paquet de 8 960 pour rappel, contre 4 096 pour les v4 et 1 024 pour les v3. Des centaines de pods peuvent s’interconnecter pour former un système capable de délivrer plusieurs péta-opérations par seconde.
Sundar Pichai a indiqué durant la conférence que Trillium sera disponible pour les clients d’ici à la fin de l’année, tout comme le CPU maison Axion d’ailleurs. Il faudra attendre début 2025 pour les GPU Blackwell de NVIDIA.
Les Tensor Processing Unit sont des puces développées par Google pour l’intelligence artificielle, de l’entraînement à l’inférence. La société vient d’annoncer sa sixième génération, qu’elle présente comme 4,7x plus performante que la génération précédente.
Hier, lors de la keynote d‘ouverture de la conférence I/O, Google a tiré tous azimuts sur l’intelligence artificielle (nous y reviendrons). La société s’en amuse elle-même avec un décompte officiel : durant son discours, Sundar Pichai y a fait référence pas moins de 121 fois, c’est du moins le décompte fait par… une IA.
Mais pour utiliser des intelligences artificielles, il faut des machines capables de les entrainer et de les faire tourner. Si NVIDIA et ses GPU règnent en maitres sur le haut du panier dans le monde des datacenters, de nombreuses autres sociétés développent leurs propres puces. C’est le cas de Google avec ses Tensor Processing Unit (TPU). Il s’agit d’ASIC (circuits intégrés spécifiques aux applications) conçus « pour accélérer les charges de travail de machine learning ».
La sixième génération a été annoncée hier. Elle devrait logiquement s’appeler TPU v6, mais Google n’utilise pas cette appellation dans son communiqué. L’entreprise se contente d’un nom de code : Trillium. Comme nous l’avions déjà détaillé, la précédente génération comportait deux versions : v5e et v5p. Les premières visent le meilleur rapport performances/prix, tandis que les secondes (lancées plus tard) misent tout sur les performances.
Bien évidemment, Google compare sa sixième génération de TPU aux v5e, pas aux V5p. Il est ainsi question d’un maximum de « 4,7 fois plus » de performances par puce, sans savoir à quoi cela correspond exactement.
Si on se base sur les 197 TFLOP du v5e en blfoat16, on arriverait à un maximum théorique de 926 TFLOP, soit deux fois plus que les performances du v5p. Mais le 4.7x pourrait aussi renvoyer à un cas particulier, impossible donc en l’état d’en savoir plus.
Quoi qu’il en soit, pour arriver à cette hausse des performances, Google explique avoir augmenté la taille de ses unités de multiplication matricielle (MXU) et la fréquence d’horloge de sa puce, sans préciser dans quelles mesures.
Bande passante HBM et ICI doublée
Google annonce aussi avoir « doublé la capacité et la bande passante de la mémoire HBM, ainsi que la bande passante Interchip Interconnect (ICI) par rapport au TPU v5e ». On passerait ainsi à 1 638 Go/s sur la mémoire (en prenant 819 Go/s pour le v5e) , ce qui reste en dessous des 2 765 Go/s du v5p.
La bande passante de l’ICI est de 1 600 Gb/s sur v5e, on doit donc arriver à 3 200 Gb/s sur Trillium (TPU v6), contre 4 800 Gb/s sur v5p.
Pour en terminer avec les chiffres, Google affirme que son TPU Trillium est « plus de 67 % plus économe en énergie que le v5e ». Mais comme l’entreprise ne donne pas de chiffre sur la consommation, impossible d’en savoir plus.
« Trillium est équipé de la troisième génération de SparseCore», un accélérateur permettant « d’accélérer l’intégration de charges de travail lourdes ». Google affirme que ses TPU Trillium « permettent de former plus rapidement la prochaine vague de modèles et de servir les modèles avec une latence réduite et un coût moindre ». Une phrase que l’on peut ressortir à chaque nouvelle génération.
Jusqu’à 256 TPU Trillium par pod
Ces TPU de la génération Trillium peuvent être assemblée par paquet de 256 pour former un pod, exactement comme les v5e. Les v5p peuvent s’agglutiner par paquet de 8 960 pour rappel, contre 4 096 pour les v4 et 1 024 pour les v3. Des centaines de pods peuvent s’interconnecter pour former un système capable de délivrer plusieurs péta-opérations par seconde.
Sundar Pichai a indiqué durant la conférence que Trillium sera disponible pour les clients d’ici à la fin de l’année, tout comme le CPU maison Axion d’ailleurs. Il faudra attendre début 2025 pour les GPU Blackwell de NVIDIA.
Selon Nikkei Asia, la société compterait se lancer dans le développement de puces dédiées pour l’intelligence artificielle l’année prochaine, avec un prototype dès le printemps 2025. Bien évidemment, aucun détail n’est pour le moment donné.
Le développement sera assuré par Arm (avec la participation de son principal actionnaire SoftBank), dans le but ensuite de scinder la branche IA et de la placer sous le contrôle de SoftBank, selon nos confrères. « SoftBank négocie déjà avec Taiwan Semiconductor Manufacturing Corp. [TSMC, ndlr] et d’autres afin de sécuriser la capacité de production ».
Selon Nikkei, Arm disposerait d’une fenêtre intéressante : « NVIDIA est actuellement en tête du domaine mais ne peut pas répondre à la demande croissante. SoftBank y voit une opportunité ». Arm n’est pas le seul en piste, loin de là. De nombreuses sociétés (y compris en France) se sont déjà lancées dans la conception de puces pour l’intelligence artificielle.
Selon Nikkei Asia, la société compterait se lancer dans le développement de puces dédiées pour l’intelligence artificielle l’année prochaine, avec un prototype dès le printemps 2025. Bien évidemment, aucun détail n’est pour le moment donné.
Le développement sera assuré par Arm (avec la participation de son principal actionnaire SoftBank), dans le but ensuite de scinder la branche IA et de la placer sous le contrôle de SoftBank, selon nos confrères. « SoftBank négocie déjà avec Taiwan Semiconductor Manufacturing Corp. [TSMC, ndlr] et d’autres afin de sécuriser la capacité de production ».
Selon Nikkei, Arm disposerait d’une fenêtre intéressante : « NVIDIA est actuellement en tête du domaine mais ne peut pas répondre à la demande croissante. SoftBank y voit une opportunité ». Arm n’est pas le seul en piste, loin de là. De nombreuses sociétés (y compris en France) se sont déjà lancées dans la conception de puces pour l’intelligence artificielle.
SiPearl donne enfin des détails sur son processeur Rhea1 pensé pour les supercalculateurs. On apprend notamment qu’il exploitera 80 cœurs Arm Neoverse V1. Il n’arrivera qu’en 2025, en retard sur ce qui était encore prévu il y a quelques mois.
En septembre dernier, nous avions rencontré les équipes de SiPearl, une société française (basée à Maisons-Laffitte) en charge de développer le processeur européen pour le HPC (calcul haute performance). Il sera notamment dans JUPITER, le premier supercalculateur exascale européen (financé en partie par la Commission européenne) qui sera installé en Allemagne.
Il y a un an, SiPearl bouclait un tour de table de 90 millions d’euros auprès d’Arm, Eviden (Atos), le fonds d’investissement European Innovation Council (EIC) et French Tech Souveraineté. Cette manne lui a permis ainsi de régler ses soucis financiers, de recruter et d’aller de l’avant. Marie-Anne Garigue, directrice de la communication de la société, affirmait que les soucis étaient uniquement financiers, pas techniques.
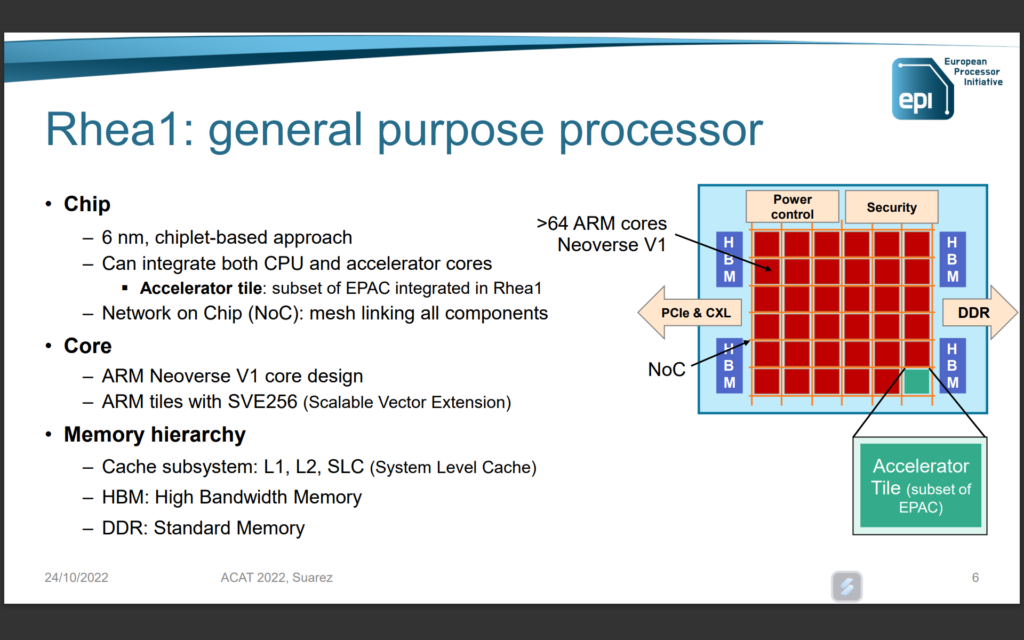
80 cœurs Arm Neoverse V1…
On sait depuis longtemps que le processeur sera articulé autour de cœurs Arm Neoverse v1. On connait désormais leur nombre : 80 cœurs par CPU. Le Neoverse V1 est pour rappel un dérivé du Cortex-X1, mais pensé pour les datacenters. Arm a depuis lancé les Neoverse V2 (dérivés du Cortex-X3) et récemment le Neoverse V3.
NVIDIA utilise par exemple 72 cœurs Arm Neoverse V2 pour la partie CPU de sa puce GH200 Grace Hopper Superchip et de sa nouvelle GB200 Grace Blackwell Superchip. Même chose chez Amazon avec son SoC Graviton4 et chez Google avec l’Axion.
…avec des extensions vectorielles évolutives
Revenons à SiPearl et son Rhea1. Chacun des 80 cœurs Neoverse V1 sera accompagné de « deux unités SVE [Scalable Vector Extension ou extension vectorielle évolutive, ndlr] de 256 bits », comme c‘est le cas par défaut avec les cœurs Neoverse V1.
Ces deux unités sont d’ailleurs une différence importante avec les Cortex-X1. Selon SiPearl, elles permettent « des calculs vectoriels rapides tout en optimisant l’espace et l’énergie utilisée ».
Arm ajoute qu’elles proposent « de meilleures performances HPC et IA/ML ». L’entreprise est un peu plus loquace et ajoute que « SVE a été inventé en collaboration avec Fujitsu pour le projet Fugaku [un supercalculateur qui a pendant un temps occupé la première place du Top500, ndlr] et permet une programmation agnostique en largeur vectorielle. SVE permet l’exécution de code de vecteurs allant de 128b à 2048b de large sur Neoverse V1 sans nécessiter de recompilation ».
HBM, DDR5,104 lignes PCIe 5.0 et CMN-700
Côté mémoire, Rhea1 dispose de « quatre piles HBM » (dans d’autres documents, il est précisé HBM2e) et de « quatre interfaces DDR5 », prenant en charge deux DIMM par canal. On retrouve aussi 104 lignes PCIe Gen 5 avec une répartition 6x 16 lignes + 2x 4 lignes (soit 104 lignes au total, le compte est bon).
SiPearl précise qu’un « réseau maillé cohérent sur puce (NoC) haute performance arm Neoverse CMN-700 [CMN pour Coherent Mesh Network, ndlr] pour interconnecter les éléments de calcul et d'entrée/sortie » est aussi de la partie. Là encore, c’est dans le package proposé par Arm avec sa plateforme Neoverse V1. Le CMN-700 peut gérer jusqu’à 256 cœurs par die, selon Arm.
Côté programmation, le CPU Rhea1 « sera supporté par une large gamme de compilateurs, de bibliothèques et d'outils, allant des langages de programmation traditionnels tels que C/C++, Go et Rust aux structures d'intelligence artificielle modernes comme TensorFlow ou PyTorch ».
Rhea1 n’arrivera finalement qu’en 2025
On apprend par contre que le processeur aura encore du retard puisque « les premiers échantillons de Rhea1 seront disponibles en 2025 ». En effet, en septembre dernier, SiPearl nous expliquait que la commercialisation se ferait dans le « courant de l’année » 2024. En avril 2023, après la levée de fonds, l’entreprise annonçait « une commercialisation début 2024 ».
Le supercalculateur européen JUPITER devra donc lui aussi attendre, puisqu’il est prévu qu’il intègre les processeurs Rhea1. La Commission européenne expliquait il y a peu que « le supercalculateur JUPITER devrait être accessible à un large éventail d’utilisateurs européens à partir de la fin de 2024 ».
Rhea2 était prévu pour 2025 aux dernières nouvelles, avec une technologie « dual chiplet » permettant d’intégrer plus de cœurs sur une même puce. La société ne précise pas si le calendrier de la seconde génération glisse lui aussi.
SiPearl donne enfin des détails sur son processeur Rhea1 pensé pour les supercalculateurs. On apprend notamment qu’il exploitera 80 cœurs Arm Neoverse V1. Il n’arrivera qu’en 2025, en retard sur ce qui était encore prévu il y a quelques mois.
En septembre dernier, nous avions rencontré les équipes de SiPearl, une société française (basée à Maisons-Laffitte) en charge de développer le processeur européen pour le HPC (calcul haute performance). Il sera notamment dans JUPITER, le premier supercalculateur exascale européen (financé en partie par la Commission européenne) qui sera installé en Allemagne.
Il y a un an, SiPearl bouclait un tour de table de 90 millions d’euros auprès d’Arm, Eviden (Atos), le fonds d’investissement European Innovation Council (EIC) et French Tech Souveraineté. Cette manne lui a permis ainsi de régler ses soucis financiers, de recruter et d’aller de l’avant. Marie-Anne Garigue, directrice de la communication de la société, affirmait que les soucis étaient uniquement financiers, pas techniques.
80 cœurs Arm Neoverse V1…
On sait depuis longtemps que le processeur sera articulé autour de cœurs Arm Neoverse v1. On connait désormais leur nombre : 80 cœurs par CPU. Le Neoverse V1 est pour rappel un dérivé du Cortex-X1, mais pensé pour les datacenters. Arm a depuis lancé les Neoverse V2 (dérivés du Cortex-X3) et récemment le Neoverse V3.
NVIDIA utilise par exemple 72 cœurs Arm Neoverse V2 pour la partie CPU de sa puce GH200 Grace Hopper Superchip et de sa nouvelle GB200 Grace Blackwell Superchip. Même chose chez Amazon avec son SoC Graviton4 et chez Google avec l’Axion.
…avec des extensions vectorielles évolutives
Revenons à SiPearl et son Rhea1. Chacun des 80 cœurs Neoverse V1 sera accompagné de « deux unités SVE [Scalable Vector Extension ou extension vectorielle évolutive, ndlr] de 256 bits », comme c‘est le cas par défaut avec les cœurs Neoverse V1.
Ces deux unités sont d’ailleurs une différence importante avec les Cortex-X1. Selon SiPearl, elles permettent « des calculs vectoriels rapides tout en optimisant l’espace et l’énergie utilisée ».
Arm ajoute qu’elles proposent « de meilleures performances HPC et IA/ML ». L’entreprise est un peu plus loquace et ajoute que « SVE a été inventé en collaboration avec Fujitsu pour le projet Fugaku [un supercalculateur qui a pendant un temps occupé la première place du Top500, ndlr] et permet une programmation agnostique en largeur vectorielle. SVE permet l’exécution de code de vecteurs allant de 128b à 2048b de large sur Neoverse V1 sans nécessiter de recompilation ».
HBM, DDR5,104 lignes PCIe 5.0 et CMN-700
Côté mémoire, Rhea1 dispose de « quatre piles HBM » (dans d’autres documents, il est précisé HBM2e) et de « quatre interfaces DDR5 », prenant en charge deux DIMM par canal. On retrouve aussi 104 lignes PCIe Gen 5 avec une répartition 6x 16 lignes + 2x 4 lignes (soit 104 lignes au total, le compte est bon).
SiPearl précise qu’un « réseau maillé cohérent sur puce (NoC) haute performance arm Neoverse CMN-700 [CMN pour Coherent Mesh Network, ndlr] pour interconnecter les éléments de calcul et d'entrée/sortie » est aussi de la partie. Là encore, c’est dans le package proposé par Arm avec sa plateforme Neoverse V1. Le CMN-700 peut gérer jusqu’à 256 cœurs par die, selon Arm.
Côté programmation, le CPU Rhea1 « sera supporté par une large gamme de compilateurs, de bibliothèques et d'outils, allant des langages de programmation traditionnels tels que C/C++, Go et Rust aux structures d'intelligence artificielle modernes comme TensorFlow ou PyTorch ».
Rhea1 n’arrivera finalement qu’en 2025
On apprend par contre que le processeur aura encore du retard puisque « les premiers échantillons de Rhea1 seront disponibles en 2025 ». En effet, en septembre dernier, SiPearl nous expliquait que la commercialisation se ferait dans le « courant de l’année » 2024. En avril 2023, après la levée de fonds, l’entreprise annonçait « une commercialisation début 2024 ».
Le supercalculateur européen JUPITER devra donc lui aussi attendre, puisqu’il est prévu qu’il intègre les processeurs Rhea1. La Commission européenne expliquait il y a peu que « le supercalculateur JUPITER devrait être accessible à un large éventail d’utilisateurs européens à partir de la fin de 2024 ».
Rhea2 était prévu pour 2025 aux dernières nouvelles, avec une technologie « dual chiplet » permettant d’intégrer plus de cœurs sur une même puce. La société ne précise pas si le calendrier de la seconde génération glisse lui aussi.
La semaine dernière, Apple a présenté comme prévu sa nouvelle gamme de tablette iPad Pro, avec une nouvelle puce maison : M4. Cette quatrième génération prend donc la relève du SoC M3. Nous avons regroupé les principales caractéristiques techniques des M1 à M4 dans un tableau, avec une mise en perspective des performances annoncées par Apple.
Comme à son habitude, Apple ne tarit pas d’éloges lorsqu’il s’agit de présenter un nouveau produit, quel qu’il soit. Avec la puce M4, on a eu droit à une débauche de chiffres et de promesses – « performances exceptionnelles », « révolutionnaire »… – , mais parfois avec des non-dits très importants.
Dans son communiqué, Apple annonce « jusqu’à 10 cœurs » pour la partie CPU, ce qui veut évidemment dire qu’il existe au moins une version plus légère. Et, en effet, la nouvelle puce M4 intègre 9 ou 10 cœurs avec 3 ou 4 cœurs performances (P) et 6 cœurs efficaces (E). Les générations précédentes étaient à 8 cœurs pour le CPU (4P et 4E).
Il faut se rendre sur la page de l’iPad Pro pour trouver le détail des configurations : « Les modèles d’iPad Pro avec 256 Go ou 512 Go de stockage sont équipés de la puce Apple M4 avec CPU 9 cœurs. Les modèles d’iPad Pro avec 1 To ou 2 To de stockage sont équipés de la puce Apple M4 avec CPU 10 cœurs ».
Le stockage détermine les cœurs CPU et la mémoire
Seuls les modèles les plus chers peuvent donc profiter des 10 cœurs du SoC M4. Les iPad Pro de 256 et 512 Go n’ont en effet droit qu’à trois cœurs P, soit un de moins que la puce M3, mais avec deux cœurs E de plus. Apple insiste d’ailleurs beaucoup sur le gain en efficacité énergétique de son SoC.
Ce n’est d’ailleurs pas le seul changement : les iPad Pro de 256 et 512 Go ont 8 Go de mémoire seulement, quand les versions de 1 et 2 To ont 16 Go. Ces différences ne sont pas mises en avant par Apple dans sa boutique en ligne. Il faut cliquer sur « Vous ne savez pas pour quel espace de stockage opter ? Voici quelques conseils pour déterminer l’espace qu’il vous faut » pour avoir le détail.
Le SoC M4 intègre 10 cœurs GPU
Sur la partie GPU, il y a toujours 10 cœurs avec la puce M4 (dans sa version pour les iPad Pro en tout cas), alors que cela varie de 8 à 10 sur les M3 et M2.
Apple explique que « le nouveau GPU 10 cœurs de la puce M4 fait évoluer l’architecture graphique de nouvelle génération de la famille des puces M3. Il intègre la mise en cache dynamique, une innovation Apple qui alloue la mémoire locale de façon dynamique dans le matériel et en temps réel afin d’accroître l’utilisation moyenne du GPU ».
Cette technologie n’est pas une nouveauté du M4, car elle était déjà mise en avant sur le SoC M3. Il semble que les nouveaux cœurs GPU n’aient pas grand-chose de nouveau par rapport à ceux de la génération précédente, mais cela reste à confirmer.
Pour les performances, Apple annonce des « rendus pro jusqu’à 4x plus rapides qu’avec la M2 » et des « performances du CPU jusqu’à 1,5x plus rapides qu’avec la M2 ». Problème, il s’agit de comparer une puce avec deux générations d’écart et un nombre de cœurs CPU différent : 10 pour la version M4, 8 pour la M2.
Pour le GPU, c’est encore pire. Le « 4x » est donné pour Octane X 2024.1 (a4) 4-09-2024, version « testée à l’aide d’une scène comprenant 780 000 maillages (meshes) et 27 millions de primitives uniques, en utilisant le ray tracing à accélération matérielle sur les systèmes équipés de la M4 et le ray tracing basé sur le logiciel sur toutes les autres unités ».
Le GPU de la puce M2 ne prend pour rappel pas en charge le ray tracing, qui est une nouveauté du M3. Forcément, la puce M4 fait bien mieux puisqu’elle dispose d’une accélération matérielle. De manière générale, Apple se garde bien de comparer son M4 au M3. Pourtant, lors de l’annonce de la famille M3, les performances des cœurs P et E étaient comparées à celle des générations précédentes.
Si la communication d’Apple s’axe beaucoup sur la comparaison M2 et M4, c’est que le nouvel iPad Pro saute une génération de puce. Le SoC M3 est en effet pour le moment réservé à certains MacBook et iMac.
38 TOPS… qui ne veulent pas dire grand-chose en l’état
Passons à une autre « astuce » d’Apple, sur le Neural Engine cette fois-ci. La société met en avant des performances de 38 TOPS, bien au-delà des 18 TOPS de la puce M3 (qui a aussi 16 cœurs NPU). Mais comme Apple ne donne aucune information sur la précision (entier, virgule flottante, nombre de bits…), impossible de savoir ce qu’il en est.
En tout état de cause, impossible d’affirmer pour le moment que les performances sont plus que doublées (de 18 à 38 TOPS). En effet, si le M3 est mesuré en INT16 à 18 TOPS et que le M4 est en INT8 à 38 TOPS, alors cela donnerait 18 et 19 TOPS (INT16) ou 36 et 38 TOPS (INT8) en base comparable pour les M3 et M4 respectivement, soit un gain de 5 % seulement.
Une « astuce » déjà utilisée par NVIDIA lors de l’annonce de Blackwell. Le constructeur a mis deux GPU sur une seule puce et affiche des performances en FP4, deux fois supérieures à celle en FP8. NVIDIA pouvait ainsi passer de 4 000 à 20 000 TFLOPS, alors que le gain sur le GPU en base comparable n’est « que » de 25 % entre Hopper et Blackwell.
Seule certitude, la bande passante de la mémoire grimpe de 20 % (certainement via une hausse de la fréquence) et passe ainsi de 100 à 120 Go/s. La finesse de gravure est toujours en 3 nm (comme pour les M3), mais passe à la seconde génération. Un nouveau contrôleur vidéo Tandem OLED est de la partie.
Apple n’a pas précisé la quantité de mémoire unifiée maximum sur la puce M4, mais on peut supposer qu’elle devrait être identique à celle de la M3, avec jusqu’à 24 Go. Autre « nouveauté » de la puce M4 mise en avant par Apple : le décodage vidéo AV1 sur iPad. Les Mac équipés de M3 pouvaient déjà le faire.
Le fabricant n’a pas encore annoncé les versions Pro et Max de sa puce M4. Il faudra également attendre de voir si un SoC M4 Ultra verra le jour. Les précédentes versions Ultra étaient pour rappel deux puces M1 ou M2 Max assemblées pour doubler les performances.
Tableau récapitulatif des puces M1 à M4
Voici pour finir notre tableau comparatif des caractéristiques des différentes variantes de puces Mx d’Apple (sauf les versions Ultra).
Matter (anciennement CHIP) est un protocole domotique, dont la version finale a été mise en ligne fin 2022. Il est développé par la Connectivity Standards Alliance (CSA), anciennement Zigbee Alliance.
La nouvelle version 1.3 du protocole propose une gestion de l’énergie. « Cela permet à tout type d’appareil d’inclure la possibilité de rapporter des mesures réelles et estimées, y compris la puissance instantanée, la tension, le courant et d’autres données en temps réel, ainsi que sa consommation ou sa production d’énergie au fil du temps ».
Les bornes de recharge sont aussi de la partie. Elles peuvent utiliser le protocole pour proposer un démarrage/arrêt de la charge, modifier la puissance, préciser l’autonomie souhaitée avant de partir, gérer la charge en fonction des tarifs de l’électricité, etc.
Enfin, pour l’eau, Matter prend en charge « les détecteurs de fuite et de gel, les capteurs de pluie et les vannes d’eau contrôlables ».
De nombreux nouveaux types d’appareils sont intégrés dans Matter 1.3 pour simplifier la vie des fabricants qui voudraient sauter le pas : fours, fours à micro-onde, table de cuisson, hottes et sèche-linge. Les frigos, climatisations, lave-vaisselle, lave-linge, aspirateurs, ventilateurs, détecteurs de fumée et de qualité de l’air avaient été ajoutés dans la version 1.2 en octobre dernier. Il faut bien évidemment que le fabricant intègre le protocole Matter pour que l’appareil soit compatible.
Niveau fonctionnalités, on trouve aussi les scènes. De plus, « un contrôleur Matter peut désormais regrouper plusieurs commandes en un seul message lors de la communication avec des périphériques Matter afin de minimiser le délai entre l’exécution de ces commandes ».
Matter (anciennement CHIP) est un protocole domotique, dont la version finale a été mise en ligne fin 2022. Il est développé par la Connectivity Standards Alliance (CSA), anciennement Zigbee Alliance.
La nouvelle version 1.3 du protocole propose une gestion de l’énergie. « Cela permet à tout type d’appareil d’inclure la possibilité de rapporter des mesures réelles et estimées, y compris la puissance instantanée, la tension, le courant et d’autres données en temps réel, ainsi que sa consommation ou sa production d’énergie au fil du temps ».
Les bornes de recharge sont aussi de la partie. Elles peuvent utiliser le protocole pour proposer un démarrage/arrêt de la charge, modifier la puissance, préciser l’autonomie souhaitée avant de partir, gérer la charge en fonction des tarifs de l’électricité, etc.
Enfin, pour l’eau, Matter prend en charge « les détecteurs de fuite et de gel, les capteurs de pluie et les vannes d’eau contrôlables ».
De nombreux nouveaux types d’appareils sont intégrés dans Matter 1.3 pour simplifier la vie des fabricants qui voudraient sauter le pas : fours, fours à micro-onde, table de cuisson, hottes et sèche-linge. Les frigos, climatisations, lave-vaisselle, lave-linge, aspirateurs, ventilateurs, détecteurs de fumée et de qualité de l’air avaient été ajoutés dans la version 1.2 en octobre dernier. Il faut bien évidemment que le fabricant intègre le protocole Matter pour que l’appareil soit compatible.
Niveau fonctionnalités, on trouve aussi les scènes. De plus, « un contrôleur Matter peut désormais regrouper plusieurs commandes en un seul message lors de la communication avec des périphériques Matter afin de minimiser le délai entre l’exécution de ces commandes ».
La semaine dernière était un peu particulière : les 8 et 9 mai étaient fériés et beaucoup ont fait le pont vendredi. Résultat des courses, un week-end prolongé pour certains dès mardi soir. Combiné avec un temps des plus agréables, cela donne de nombreux déplacements, et donc des centaines de kilomètres de bouchons au départ mercredi et au retour dimanche.
Nombreux étaient les conducteurs avec Waze pour essayer de trouver le trajet le plus rapide, en limitant autant que possible les bouchons. Mais l’application a fait face à une importante vague de faux signalements en tout genre : contrôles de police, voitures arrêtées, alertes météo, mais également routes enneigées et verglacées. Sur l’A6 et l’A10 par exemple, ils se comptaient par dizaines.
Waze permet pour rappel à tout un chacun de « contribuer à l’amélioration de la carte » en signalant la présence de la police, un accident, un danger, du mauvais temps, une route bloquée, etc. L’application demande alors aux autres usagers si le « danger » est toujours présent ou non.
« Les signalements s’affichent sur la carte pendant un certain temps. Cette durée varie en fonction du nombre de Wazers qui réagissent à un signalement. Si un signalement n’est plus exact, appuyez sur Plus là. Cela permet de réduire la durée d’affichage du signalement », explique Google. Hier, c’était un peu le jeu du chat et de la souris avec des faux signalements qui apparaissaient et disparaissaient.
L’application a des protections contre les signalements abusifs et excessifs : « Si vous avez effectué un nombre excessif de signalements dans votre compte, vous ne pourrez plus en effectuer pendant un certain temps. Si votre compte a été signalé plusieurs fois pour ce même motif, ce délai augmentera » : 24h pour le premier avertissement, 7 jours pour le second et 30 jours pour le troisième.
Nous avons demandé à Waze si le service avait plus de précision sur ce qu’il s’est passé ce week-end. Et vous, avez-vous remarqué une recrudescence des faux signalements sur Waze durant ce week-end prolongé ?
La semaine dernière était un peu particulière : les 8 et 9 mai étaient fériés et beaucoup ont fait le pont vendredi. Résultat des courses, un week-end prolongé pour certains dès mardi soir. Combiné avec un temps des plus agréables, cela donne de nombreux déplacements, et donc des centaines de kilomètres de bouchons au départ mercredi et au retour dimanche.
Nombreux étaient les conducteurs avec Waze pour essayer de trouver le trajet le plus rapide, en limitant autant que possible les bouchons. Mais l’application a fait face à une importante vague de faux signalements en tout genre : contrôles de police, voitures arrêtées, alertes météo, mais également routes enneigées et verglacées. Sur l’A6 et l’A10 par exemple, ils se comptaient par dizaines.
Waze permet pour rappel à tout un chacun de « contribuer à l’amélioration de la carte » en signalant la présence de la police, un accident, un danger, du mauvais temps, une route bloquée, etc. L’application demande alors aux autres usagers si le « danger » est toujours présent ou non.
« Les signalements s’affichent sur la carte pendant un certain temps. Cette durée varie en fonction du nombre de Wazers qui réagissent à un signalement. Si un signalement n’est plus exact, appuyez sur Plus là. Cela permet de réduire la durée d’affichage du signalement », explique Google. Hier, c’était un peu le jeu du chat et de la souris avec des faux signalements qui apparaissaient et disparaissaient.
L’application a des protections contre les signalements abusifs et excessifs : « Si vous avez effectué un nombre excessif de signalements dans votre compte, vous ne pourrez plus en effectuer pendant un certain temps. Si votre compte a été signalé plusieurs fois pour ce même motif, ce délai augmentera » : 24h pour le premier avertissement, 7 jours pour le second et 30 jours pour le troisième.
Nous avons demandé à Waze si le service avait plus de précision sur ce qu’il s’est passé ce week-end. Et vous, avez-vous remarqué une recrudescence des faux signalements sur Waze durant ce week-end prolongé ?
Le BASIC est un langage de programmation que les moins jeunes connaissent certainement, voire qu’ils ont étudié à l’école pour certains (j’en fais partie, cela ne me rajeunit pas…). Ce projet universitaire, qui réunit à la fois un langage de programmation et la notion de temps partagé, vient de fêter ses 60 ans. On remonte donc soixante ans en arrière…
Il y a quelques jours, le BASIC fêtait ses 60 ans : « à 4 heures du matin, le 1er mai 1964, dans le sous-sol du College Hall, le professeur John G. Kemeny et un étudiant programmeur [Thomas E. Kurtz, ndlr] tapaient simultanément RUN sur les terminaux voisins », explique le Dartmouth College, une université privée du nord-est des États-Unis, où s’est déroulé cette première.
Pour vous resituer un peu, c’est aussi dans les années 60 que Douglas Engelbart a inventé la souris. Internet n’existait pas, et ARPANET n’est arrivé que cinq ans plus tard, en octobre 1969, avec le premier paquet de données qui transitait entre une université et une entreprise.
Alors qu’Apple occupait une bonne partie de l’espace médiatique avec ses nouveaux iPad et sa puce M4 (nous y reviendrons), Google a lancé son nouveau smartphone « d’entrée de gamme » : le Pixel 8a. Comptez 549 euros tout de même.
Google indique que « son nouvel écran [6,1 pouces, OLED, 1080 x 2400, ndlr] Actua est 40 % plus lumineux que celui du Pixel 7a » et profite d’un taux de rafraichissement de 120 Hz. Le smartphone dispose d’un capteur photo de 64 Mpx et d’un objectif ultra grand-angle de 13 Mpx.
Comme les Pixel 8 et 8 Pro, le Pixel 8a est équipé d’une puce Tensor G3 de Google. 8 Go de LPDDR5x et 128 ou 256 Go de stockage sont de la partie. On retrouve du Wi-Fi 6E, du Bluetooth 5.3, de la 5G, du NFC… Toutes les caractéristiques techniques sont disponibles par ici.
Le fabricant met en avant les « outils fondés sur l’IA pour tirer le meilleur parti de vos photos et vidéos ». Il y a notamment la « retouche magique », la « gomme magique audio », la fonction « entourer pour chercher ». Il y a aussi les « audiomoj » pour vos conversations audio.
Le Pixel 8a sera disponible à partir du 14 mai, pour 549 euros. Google annonce « sept ans de support logiciel, y compris les mises à jour de sécurité et les mises à jour Android ».
Alors qu’Apple occupait une bonne partie de l’espace médiatique avec ses nouveaux iPad et sa puce M4 (nous y reviendrons), Google a lancé son nouveau smartphone « d’entrée de gamme » : le Pixel 8a. Comptez 549 euros tout de même.
Google indique que « son nouvel écran [6,1 pouces, OLED, 1080 x 2400, ndlr] Actua est 40 % plus lumineux que celui du Pixel 7a » et profite d’un taux de rafraichissement de 120 Hz. Le smartphone dispose d’un capteur photo de 64 Mpx et d’un objectif ultra grand-angle de 13 Mpx.
Comme les Pixel 8 et 8 Pro, le Pixel 8a est équipé d’une puce Tensor G3 de Google. 8 Go de LPDDR5x et 128 ou 256 Go de stockage sont de la partie. On retrouve du Wi-Fi 6E, du Bluetooth 5.3, de la 5G, du NFC… Toutes les caractéristiques techniques sont disponibles par ici.
Le fabricant met en avant les « outils fondés sur l’IA pour tirer le meilleur parti de vos photos et vidéos ». Il y a notamment la « retouche magique », la « gomme magique audio », la fonction « entourer pour chercher ». Il y a aussi les « audiomoj » pour vos conversations audio.
Le Pixel 8a sera disponible à partir du 14 mai, pour 549 euros. Google annonce « sept ans de support logiciel, y compris les mises à jour de sécurité et les mises à jour Android ».
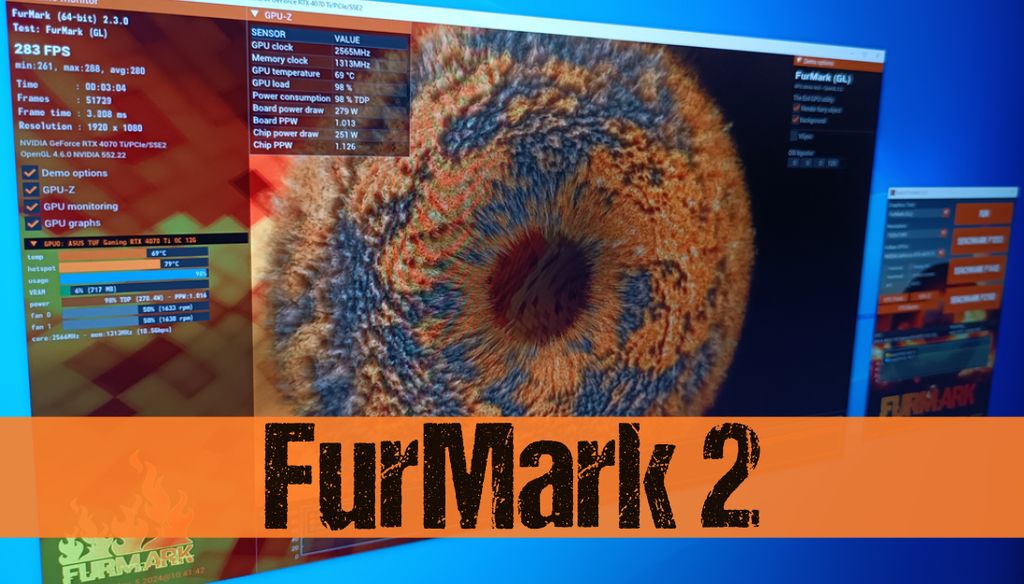
En février, JeGX publiait la version 2.0 de son application pour analyser les performances et la stabilité de votre GPU (avec un stress intense). La version 2.3 a été mise en ligne hier.
Les notes de version parlent de petits changements comme l’ajout de la vitesse du ventilateur dans la section GPU monitoring. Il y a bien évidemment aussi les traditionnelles corrections de bugs.
Mais on retrouve surtout la prise en charge d’un nouveau système : Raspberry Pi OS (64-bit, arm64/aarch64). Cette version a été compilée sur Debian 11 avec GLIBC 2.31.
JeGX en profite pour donner deux résultats : « Sur le Raspberry Pi 4, FurMark 2 fonctionne à 1 FPS (résolution : 1024×640). Le nouveau matériel du Raspberry Pi 5 est beaucoup plus rapide : on atteint 4 FPS (toujours à 1024×640) ».
« J’ai essayé de supprimer les dépendances de Raspberry Pi et j’espère que cette version fonctionnera sur d’autres plates-formes arm64/aarch64 », ajoute-t-il.