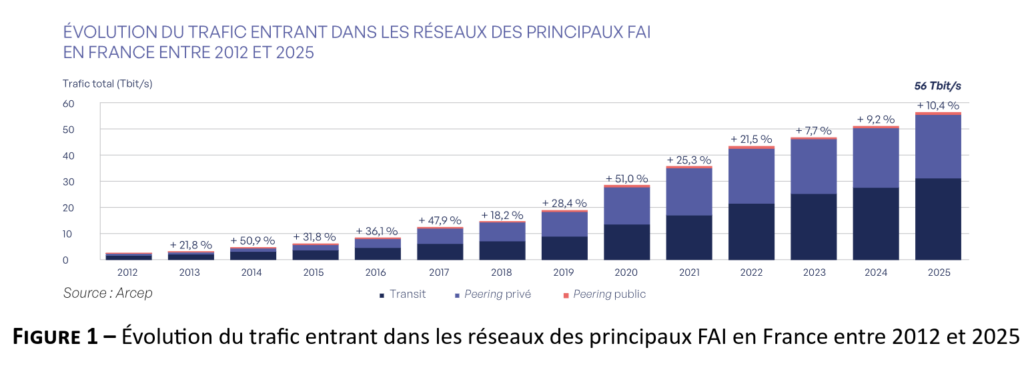
Pour la CJUE, le géoblocage peut être « efficace » même s’il est contournable via un VPN
Le plus efficace possible

La Cour de justice européenne a rendu son arrêt concernant un litige sur l’œuvre d’Anne Frank, qui est entrée dans le domaine public en Belgique mais pas aux Pays-Bas. Un géoblocage à la « pointe de la technologie » suffit à être dans les clous, même si des technologies comme un VPN permettent de le contourner.
Le 9 juillet dernier, la Cour de justice européenne (CJUE) a rendu un arrêt qui clarifie ce qu’il est possible de faire lorsqu’une œuvre est entrée dans le domaine public dans un pays mais pas dans un autre.
Rappelons que le droit d’auteur varie beaucoup selon les pays. Ainsi, par exemple, une partie des œuvres d’Anne Frank est encore protégée aux Pays-Bas jusqu’en 2037 alors qu’elles sont entrées dans le domaine public en Belgique.
Un conflit entre le Fonds Anne Frank et la Fondation Anne Frank
C’est justement ce cas qui était présenté à la CJUE. Les droits d’auteur du journal d’Anne Frank ont fait l’objet de nombreux litiges déjà. Actuellement, c’est le Fonds Anne Frank (Anne Frank Fonds) qui possède les droits sur ces œuvres aux Pays-Bas. L’organisation met en cause la Fondation Anne Frank, l’Académie royale néerlandaise des sciences et une association de valorisation d’écrits historiques pour avoir publié une édition scientifique des manuscrits d’Anne Frank, en langue néerlandaise, sur le site www.annefrankmanuscripten.org (enregistrée en Belgique).
C’est la Cour suprême des Pays-Bas qui doit départager les parties en conflit après un pourvoi du Fonds Anne Frank, mais elle a demandé à la Cour européenne un avis sur la question des moyens mis en place pour bloquer l’accès à l’œuvre dans les pays où elle n’est pas entrée dans le domaine public.
La Cour suprême des Pays-Bas a constaté (comme nous) que l’accès au site en question est restreint par un système de « géoblocage » qui en empêche la consultation avec une IP venant d’un État membre de l’UE dans lequel les manuscrits sont encore protégés par le droit d’auteur.
Ainsi, aux Pays-Bas comme en France d’ailleurs, un message en néerlandais et en anglais apparait à la consultation du site :
Nous sommes désolés… Malheureusement, ce site n'est pas accessible depuis votre pays. L'édition scientifique des manuscrits d'Anne Frank ne peut être mise à disposition dans tous les pays, pour des raisons liées aux droits d'auteur. Cette édition est publiée en ligne par la Vereniging voor Onderzoek en Ontsluiting van Historische Teksten (Association pour la recherche et l'accès aux textes historiques), Avenue Louise 209a / Louizalaan 209a, 1050 Bruxelles (Belgique).
Un géoblocage peut être considéré comme « efficace » même s’il est contournable
Mais elle demande à la CJUE si ce géoblocage suffit, sachant qu’il est contournable via un VPN dont l’adresse IP vient d’un pays où l’œuvre est dans le domaine public.
La CJUE explique que la mesure de blocage géographique peut être considérée comme « efficace », au regard de la directive européenne sur l’harmonisation de certains aspects du droit d’auteur de 2001, « dès lors qu’elle est à la « pointe de la technologie » », et ce même si des internautes« peuvent la contourner en ayant recours à un VPN ou à un service similaire ».
Ainsi, le droit européen ne demande pas d’installer en de pareilles circonstances un géoblocage à toute épreuve, mais il doit être au niveau de l’état de l’art.
La CJUE éclaircit aussi le fait que les fournisseurs de VPN ne peuvent être incriminés dans ce genre d’histoires : « le fournisseur de VPN ou de services similaires utilisés pour contourner une mesure de blocage géographique inefficace et constituant des outils techniques licites auxquels les utilisateurs peuvent légitimement recourir, ne saurait être considéré comme ayant lui aussi communiqué l’œuvre au public ».