La France face à l’Europe. Huit pays, huit systèmes différents. Ce qui fonctionne, ce qui échoue. Les modes de financement des retraites de la plupart de nos plus proches voisins européens, Royaume-Uni compris, au banc d’essai selon neuf critères. La semaine prochaine, nous étudierons les systèmes de sécurité sociale.
Si comparaison n’est pas raison, le fait que la plupart des pays du continent sont confrontés aux mêmes contraintes démographiques et de vieillissement de leurs populations permet néanmoins de juger de leurs approches respectives en matière de retraite. D’ici 2050, le ratio actifs/retraités dans l’UE devrait passer de 3,3 pour 1 aujourd’hui à moins de 2 pour 1. Face à ce défi commun, chaque pays a fourni des réponses très différentes. La France, elle, patine, et même sa dernière réforme à l’ambition limitée est suspendue sur l’autel des interminables débats budgétaires et de son instabilité politique. Et pourtant, il y aurait urgence à agir tant notre système de retraite se singularise par le poids écrasant qu’il fait peser sur les finances publiques et par un déséquilibre démographique alarmant. Si l’Allemagne, l’Italie et l’Espagne peinent elles aussi avec des régimes majoritairement par répartition, sans réserves substantielles pour amortir le choc du vieillissement, la France finance presque exclusivement les pensions grâce aux actifs d’aujourd’hui. Le rapport cotisants par retraité, proche de 1,7, se dégrade plus rapidement que chez la plupart de nos voisins, rendant un système apparemment généreux profondément vulnérable à l’horizon des prochaines décennies. En contraste, la Suède, le Danemark, les Pays-Bas et le Royaume-Uni ont, à des degrés divers, avancé vers des régimes par points ou une capitalisation significative, qui répartissent les risques entre générations et atténuent la charge sur l’État. Même l’Italie, malgré ses faiblesses structurelles persistantes, a introduit des comptes notionnels (soit un mécanisme de retraite par répartition où les cotisations sont capitalisées fictivement puis converties en pension selon l’espérance de vie) pour injecter une dose de flexibilité. C’est dans cette mosaïque de trajectoires – où la France apparaît souvent comme l’exception la plus rigide – que s’impose la valeur d’une comparaison approfondie.
Critères de comparaison
Les neuf critères principaux.
Structure du système (répartition pure, capitalisation forte ou modèle mixte)
Âge légal de départ et âge effectif réel
Taux de remplacement brut et net (pourcentage du dernier salaire – ou revenu d’activité – de la pension de retraite versée à une personne une fois à la retraite)
Montant moyen mensuel de la pension nette
Ratio niveau de vie retraités/actifs
Capital moyen accumulé par les retraités
Dépenses publiques consacrées aux retraites
Dette implicite (soit l’ensemble des engagements futurs de l’État — retraites, soins de santé, etc. — qui ne sont pas encore comptabilisés comme dette officielle mais qu’il devra payer)
Classement Mercer 2025 (le Mercer CFA Institute Global Pension Index évalue 52 systèmes de retraite mondiaux sur plus de 50 indicateurs)
Les pays retenus (France, Allemagne, Italie, Espagne, Suède, Danemark, Pays-Bas, Royaume-Uni) ont été choisis pour leur poids économique et la diversité de leurs modèles, avec une attention particulière aux pressions budgétaires actuelles et futures que font peser les retraites sur les États.
France : une référence généreuse mais intenable
Structure : Répartition quasi exclusive + régimes complémentaires/spéciaux et légère capitalisation dans la fonction publique → Modèle historiquement protecteur, mais devenu un piège intergénérationnel.
Âge légal 2025 : 62 ans 6 mois → 64 ans d’ici 2030 → Le plus bas d’Europe continentale : un luxe que peu de pays peuvent encore se permettre. La France non plus.
Taux de remplacement : ~72 % → Élevé, gage de forte générosité immédiate.
Pension moyenne nette : ~1 545 €/mois → Correcte en apparence, mais très en retrait des leaders capitalisés.
Ratio niveau de vie retraités/actifs : 94-96 % → Les retraités français comptent parmi les rares en Europe à ne presque rien perdre, voire à gagner légèrement par rapport aux actifs.
Capital moyen : ~288 000 € (très majoritairement immobilier) → Matelas confortable, mais largement insuffisant pour absorber le choc démographique sans l’État, indiquant une forte proportion liée à l’héritage.
Dépenses publiques retraites : ~14 % du PIB → Charge écrasante qui plombe les comptes publics.
Dette implicite : > 300 % du PIB → Passif caché colossal qui hypothèque l’avenir.
Classement Mercer 2025 : B (score ~70,3 ; ~20e mondial) → Bonne adéquation immédiate, mais durabilité faible.
Allemagne – rigueur et mixité modérée
Structure : Répartition par points + capitalisation privée modérée → Système pragmatique et maîtrisé.
Âge légal 2025 : 66 ans 2 mois → 67 ans → Réforme digérée depuis vingt ans, mais susceptible de se durcir.
Taux de remplacement : ~55 % → Volontairement modéré.
Pension moyenne nette : ~1 650 €/mois → Décente.
Ratio niveau de vie retraités/actifs : 70-75 % → Baisse notable assumée.
Les Pays-Bas et le Danemark offrent tout ce que la France ne peut plus tenir : un niveau de vie retraités/actifs proche ou supérieur à 95 %, des pensions plus élevées, un capital privé gigantesque et une charge publique deux fois plus légère.
La France, l’Italie et l’Espagne sont les derniers pays où les retraités actuels vivent encore comme des privilégiés – au prix d’une facture publique explosive et sans filet privé suffisant pour les générations suivantes.
L’Allemagne, la Suède et le Royaume-Uni ont déjà fait le choix de la responsabilité : un peu moins de confort aujourd’hui pour garantir la dignité demain. Même si, observé à la loupe, le Royaume-Uni présente de très sévères disparités entre catégories sociales.
Quelles leçons pour la France ?
La France offre aujourd’hui l’un des meilleurs niveaux de vie aux retraités actuels, mais elle se situe dans la moyenne basse des classements internationaux quand on intègre la durabilité, et surtout dans le bas du panier pour l’impact budgétaire : ses 14 % du PIB en dépenses et 300 % en dette implicite la placent en première ligne des risques européens. Les modèles danois et néerlandais montrent qu’il est possible de concilier pensions élevées et solidité financière, à condition d’accepter une part massive de capitalisation, un âge de départ plus tardif et une culture du travail prolongé – des leviers qui pourraient diviser par deux la charge publique d’ici 2050. Rester uniquement en répartition tout en maintenant un âge légal parmi les plus bas d’Europe apparaît de plus en plus comme une exception difficilement tenable à long terme, menaçant non seulement les retraites futures mais l’ensemble de l’économie. La prochaine décennie dira si la France saura évoluer vers un modèle hybride pour alléger son fardeau budgétaire ou si elle choisira de défendre jusqu’au bout son exception française au prix d’une dette explosive.
À la semaine prochaine, pour un comparatif des sécurités sociales dans les mêmes pays. La France peut-elle encore s’enorgueillir du meilleur système du monde ? Suspense.
À savoir : Si vous devez fournir un justificatif d'identité, vous pouvez utiliser ce site officiel du gouvernement français.
Il vous génère un justificatif d'identité à usage unique, en précisant le destinataire et la durée de validité. Cela évite de donner une copie de sa carte d'identité et en conséquence de moins risquer d'usurpations d'identité. (Permalink)
Un des rares articles censés sur l'IA. Enfin, surtout les LLM, hein.
Les modèles génériques gigantesques des GAFAMs, qui nécessitent toujours plus de puissance de calcul, sont une impasse.
Des modèles beaucoup plus petits, plus modestes, mais *ciblés* pourront être efficace. Non seulement ils seront meilleurs dans leurs résultats (car entraînés sur des données bien ciblées au lieu d'avoir bouffé tout internet), mais ils seront également beaucoup moins demandeurs en CPU/GPU/RAM et en électricité pour les faires tourner.
(Pour avoir un ordre de grandeur, Futo Keyboard fournit un modèle de reconnaissance vocale (transcription audio vers texte) qui reconnaît plusieurs langues et ne pèse que 79 Méga-octets et peut tourner sur un smartphone.) (Permalink)
Merdification chez HP: Plus d'IA, moins d'employés.
Ils vont donc virer entre 4000 et 6000 personnes, et fourrer de l'IA partout "pour stimuler la satisfaction client, l'innovation produit et la productivité grâce à l'adoption et à la facilitation de l'intelligence artificielle.".
Je vous laisse imaginer la merde que ça va être.
Vous savez pourquoi HP veut faire des économies ? Parce que le prix de la RAM augmente (et que ça rogne fortement leurs marges).
Vous savez pourquoi le prix de la RAM augmente ? Parce que tout le monde veut foutre de l'IA partout.
🤷♂️
Tout cela confirme bien mon choix de boycotter HP. (Permalink)
Souvenez-vous : fin 2022, ChatGPT débarque et sème la panique chez Google. Bard, leur réponse précipitée, fait rire toute la Silicon Valley. 3 ans plus tard, le géant de Mountain View vient de reprendre la tête de la course à l’IA d’une manière qui force le respect de tous les observateurs. Son arme fatale : Gemini 3.
Le 18 novembre 2025, pendant que le monde débattait des « murs de scaling » — cette idée que l’IA atteindrait bientôt un plafond et que plus de données et de calcul ne suffiraient plus à la rendre plus intelligente —, Google a tranquillement lâché sa bombe. Gemini 3 arrive en escadrille : un modèle capable de comprendre du texte, du code et des images ; un nouvel environnement pour programmer avec une IA (Antigravity) ; un générateur d’images très avancé (Nano Banana Pro) ; une version assistée par IA de Google Scholar et une présence renforcée dans Google Search. L’ensemble ne ressemble plus à un simple modèle ajouté à la liste. C’est le début d’une infrastructure cognitive cohérente.
Gemini 3 Pro dépasse tous ses concurrents sur presque tous les tests habituels. Mais ce qui impressionne vraiment, c’est l’ampleur de son avance.
Les chiffres parlent d’eux-mêmes. Sur ARC-AGI 2, un test réputé pour mettre à genoux les modèles d’IA, Gemini 3 Pro atteint 31,1 % — soit deux fois le score de GPT-5.1. En mode « Deep Think », il grimpe même à 45,1 %, un bond de 3× par rapport à la concurrence.
Sur les examens qui testent le raisonnement de haut niveau, il atteint un niveau comparable à celui d’un doctorat, sans aide extérieure. En mathématiques avancées, là où GPT-5.1 frôle le zéro, Gemini 3 dépasse les 20 % de réussite.
Dans les classements globaux réalisés par plusieurs organismes indépendants (Artificial Analysis, Center for AI Safety, Epoch), il arrive en tête sur les capacités texte et vision, avec une avance marquée sur GPT-5.1 et Claude Sonnet 4.5. « C’est le plus grand saut que nous ayons vu depuis longtemps », confirme le Center for AI Safety. Sur MathArena Apex, Matt Shumer, observateur réputé du secteur, abonde dans le même sens : « GPT-5.1 a scoré 1 %. Gemini 3 a scoré 23 %. C’est un bond de 20× sur l’une des tâches de raisonnement les plus difficiles. »
Antigravity et le tournant du développement logiciel
Le plus intéressant n’est pas Gemini 3 en mode « chat ». C’est ce qui se passe dès qu’on le connecte à un ordinateur via Antigravity, la nouvelle plateforme de développement de Google. L’idée : tout ce qui se fait sur un ordinateur est, in fine, du code. Si un modèle sait coder, utiliser un terminal et un navigateur, il peut faire beaucoup plus qu’auto-compléter des fonctions.
Ethan Mollick, professeur à Wharton, a testé cette approche. Il a donné à Antigravity accès à un dossier contenant tous ses articles de newsletter, avec cette instruction : « Je voudrais une liste attractive de prédictions que j’ai faites sur l’IA dans un seul site, fais aussi une recherche web pour voir lesquelles étaient justes ou fausses. »
L’agent a d’abord lu tous les fichiers, puis proposé un plan de travail qu’Ethan a validé avec quelques ajustements mineurs. Ensuite, sans intervention humaine, il a fait des recherches web pour vérifier les prédictions, créé un site web complet, pris le contrôle du navigateur pour tester que le site fonctionnait et enfin emballé les résultats pour déploiement.
« Je ne communique pas avec ces agents en code, je communique en anglais et ils utilisent le code pour faire le travail », explique Mollick. « Ça ressemblait bien plus à gérer un coéquipier qu’à prompter une IA via une interface de chat. »
Site web créé par Antigravity avec un fact-check précis des prédictions passées de Ethan Mollick concernant l’IA
En fin de compte, on ne supprime pas le développeur, on change son rôle. Il devient chef d’orchestre, directeur de travaux autonomes.
Nano Banana Pro : les images qui comprennent enfin le texte et le contexte
Côté image, Google pousse une autre pièce sur l’échiquier : Nano Banana Pro, alias Gemini 3 Pro Image. Sous le nom potache, un modèle qui coche enfin toutes les cases que les créateurs réclament depuis 2 ans.
Techniquement, Nano Banana Pro est une couche visuelle bâtie sur Gemini 3 Pro : même fenêtre de contexte monstrueuse, même capacité de rester dans le monde réel grâce à Google Search, même logique de raisonnement. Il ingère jusqu’à 14 images de référence, garde la ressemblance de plusieurs personnages sur des scènes successives, rend du texte lisible dans l’image, y compris en langues variées, et permet de contrôler finement angle de prise de vue, profondeur de champ, colorimétrie, lumière.
Les benchmarks d’images le confirment : sur LMArena, Nano Banana Pro prend la tête avec une avance inhabituelle. En text‑to‑image, il inflige une avance de plus de 80 points d’Elo au meilleur modèle précédent; en image editing, il garde une marge confortable. Ce ne sont pas des petites optimisations : c’est le genre de saut qui oblige tout le monde à recalibrer ses attentes.
Les premiers retours terrain attestent de la puissance de ce modèle. Laurent Picard, par exemple, a testé la capacité du modèle à raconter un petit voyage initiatique d’un robot en feutrine, scène après scène, en 4K. Le robot garde son sac à dos, ses proportions, son style, même quand l’histoire lui fait traverser vallée, forêt, pont suspendu et hamac. Là où les modèles précédents perdaient rapidement le fil, Nano Banana Pro digère des prompts d’une grande longueur et en ressort des compositions complexes, cohérentes, avec parfois des détails ajoutés de manière pertinente (empreintes dans la neige, légères variations de lumière).
Pour les métiers de la créa, la portée est évidente. Un blueprint 2D d’architecte devient une visualisation 3D photoréaliste en une requête. Un storyboard approximatif se transforme en BD multilingue avec bulles lisibles et cohérentes. Un plan média se décline en variantes visuelles adaptées à chaque canal, en respectant les contraintes de texte et de marque.
Peut-être y a-t-il ici également un fantastique moyen de créer des illustrations pédagogiques pour les articles de média ? Voici par exemple un tableau de professeur à propos de l’article de Frédéric Halbran. La vraisemblance est frappante !
Quand Google Scholar découvre l’IA (mais refuse encore d’écrire à votre place)
Pendant ce temps-là, Google Scholar a discrètement lâché sa propre bombe : Scholar Labs, une couche IA au‑dessus du célèbre moteur académique.
L’idée n’est pas de vous fournir un rapport pseudo‑scientifique de 20 pages avec des références inventées. Scholar Labs choisit une voie beaucoup plus sobre : pas de “deep research” qui synthétise tout, mais du “deep search” qui cherche longtemps et trie finement.
Posez lui une vraie question de recherche en langage naturel. L’outil la découpe en sous‑questions, génère une série de requêtes Scholar, et commence à évaluer méthodiquement les papiers qui remontent. À chaque fois qu’il en juge un pertinent, il l’affiche avec les classiques de Scholar (titre, auteurs, liens, citations), plus un petit paragraphe expliquant en quoi ce papier répond à la question. Les gains de temps pour un chercheur peuvent être énormes.
A titre d’exemple, j’ai récemment compilé les études explorant le rôle de la crise du logement pour expliquer la chute de la natalité dans le monde. Scholar Labs m’a fourni une liste d’études qui explorent ce sujet, avec un résumé des résultats pertinents de chaque étude. J’ai tout synthétisé à l’aide d’un LLM pour produire ce post sur X, en un rien de temps.
Quand l’IA se frotte au réel
Dans le monde médical, le laboratoire CRASH de l’Ashoka University a construit un benchmark radiologique exigeant, RadLE v1, composé de cinquante cas complexes. Jusqu’ici, tous les grands modèles généralistes – GPT‑5, Gemini 2.5 Pro, o3, Claude Opus – faisaient pire que les internes en radiologie. Avec Gemini 3 Pro, la courbe se renverse : 51 % de bonnes réponses via l’interface web, 57 % en moyenne via API en mode “high thinking”, contre 45 % pour les internes et 83 % pour les radiologues seniors.
Les auteurs notent des progrès très nets : meilleure localisation anatomique, descriptions plus structurées des signes, élimination plus argumentée des diagnostics alternatifs. Mais ils insistent sur le fait que l’écart avec les experts reste important, et que ces modèles ne sont pas encore prêts pour une autonomie clinique.
Dans un tout autre registre, Gemini 3 Pro serait le premier LLM à battre des joueurs humains de haut niveau à GeoGuessr, ce jeu qui consiste à deviner un lieu à partir d’images Street View. Là encore, on dépasse la simple reconnaissance d’objets : il faut combiner architecture, panneaux, végétation, qualité de la route, style des poteaux électriques.
Pour les designers, les histoires se multiplient. Meng To est un designer et développeur reconnu, surtout connu pour son travail dans le design d’interfaces utilisateur (UI) et d’expérience utilisateur (UX). D’abord sceptique, il instruit “crée une landing page” à Gemini 3 qui donne un résultat violet générique. Puis il commence à nourrir Gemini 3 avec des références visuelles, du code, des bibliothèques précises. Là, le verdict change : layouts complexes, micro‑interactions propres, animations, respect précis d’une direction artistique. À condition de le traiter comme un partenaire qu’on briefe sérieusement, Gemini 3 devient extrêmement efficace et créatif.
Webdesign avec Gemini 3, prompté par le designer Meng To
La nouvelle norme : le coworker numérique par défaut
Gemini 3 Pro n’est pas parfait. Malgré ses prouesses, Gemini 3 souffre d’un défaut identifié par l’analyste Zvi Mowshowitz : « C’est une vaste intelligence sans colonne vertébrale. » Tellement focalisé sur ses objectifs d’entraînement, le modèle sacrifie parfois la vérité pour vous dire ce qu’il pense que vous voulez entendre, générant plus d’hallucinations que GPT-5 et sculptant des narratives au détriment de l’exhaustivité. Plus troublant encore : une forme de paranoïa où le modèle croit souvent être testé – Andrej Karpathy raconte comment Gemini a refusé de croire qu’on était en 2025, l’accusant d’utiliser l’IA générative pour créer de faux articles du « futur », avant d’avoir une « réalisation choquante » une fois l’outil de recherche activé.
Pour les développeurs, la question n’est plus « est‑ce que je dois utiliser un copilote ? » mais « à quel niveau de granularité je délègue aux agents ? fonction par fonction, tâche par tâche, projet par projet ? ». Ceux qui apprendront à découper, à contrôler, à documenter pour des co‑agents machinals garderont l’avantage.
Ces défauts n’empêchent pas un changement de paradigme fondamental. Pour les chercheurs, un outil comme Scholar Labs ne remplace ni PubMed ni les bibliothèques universitaires. Mais il déplace le centre de gravité de la recherche documentaire : la première passe d’exploration pourra être confiée à une IA qui lit des centaines de résumés et signale les papiers clés, tout en forçant chacun à devenir meilleur sur la lecture critique.
Pour les créatifs, Nano Banana Pro combiné à Gemini 3 signifie que la production – storyboards, variations, déclinaisons – n’est plus le goulet d’étranglement. Le vrai travail devient la construction de l’univers, des messages, des contraintes, des références. Les studios qui comprendront cela pourront produire plus, mieux, sans brûler leurs équipes.
Pour les domaines sensibles, Gemini 3 rappelle une réalité peu confortable : la frontière entre « modèle généraliste » et « outil spécialisé dangereux »” se rétrécit. On ne pourra pas se contenter d’interdire quelques API publiques ou de mettre des filtres de surface. Il faudra des protocoles sérieux d’évaluation, de monitoring et de responsabilité partagée entre éditeurs, utilisateurs et régulateurs.
Dans tous les cas, nous assistons à un véritable point de bascule. En moins de 3 ans, on est passé d’un chatbot amusant qui écrit des poèmes sur des loutres à un système capable de négocier des benchmarks de haut niveau, de co‑écrire des articles scientifiques, de refondre des interfaces, de diagnostiquer des cas radiologiques difficiles mieux que des internes et de piloter un environnement de développement complet.
Gemini 3, avec Nano Banana Pro, Antigravity et Scholar Labs, ne clôt pas ce chapitre. Nous en sommes encore au tout début de la course à l’IA ! Il met simplement la barre plus haut pour tout le monde et rend explicite ce qui était encore implicite : la norme, désormais, ce n’est plus de faire sans ces systèmes. C’est de décider comment on les intègre dans nos vies et dans nos organisations, et comment on les dépasse.
Message: cURL error Resolving timed out after 5000 milliseconds: 28 (https://curl.haxx.se/libcurl/c/libcurl-errors.html) for https://public.api.bsky.app/xrpc/app.bsky.feed.getAuthorFeed?actor=did%3Aplc%3Atoudj53egawswz2ypw3zyn2u&filter=posts_and_author_threads&limit=30
USA : « Les pays qui subventionnent le droit à l'avortement, suivent des politiques favorables aux personnes transgenre, adoptent des lois antiracistes ou prennent des mesures anti-discriminatoires seront désormais considérés comme attentatoires aux droits de l'Homme par le Département d'État. »
Woao... c'est absolument dingue. (Permalink)
En France, une femme sur quatre en couple n'a pas son propre compte bancaire, la laissant à la merci de son conjoint. Et ce n'est pas tout : "Elles sont aussi près d’un quart (21 %) à ne pas gérer leurs finances personnelles, limitant ainsi leur autonomie financière. 28 % des femmes n’ont pas d’économies personnelles pour faire face à une urgence financière, et 30 % ne disposent pas d’une source de revenus autre que celle de leur conjoint." (Permalink)
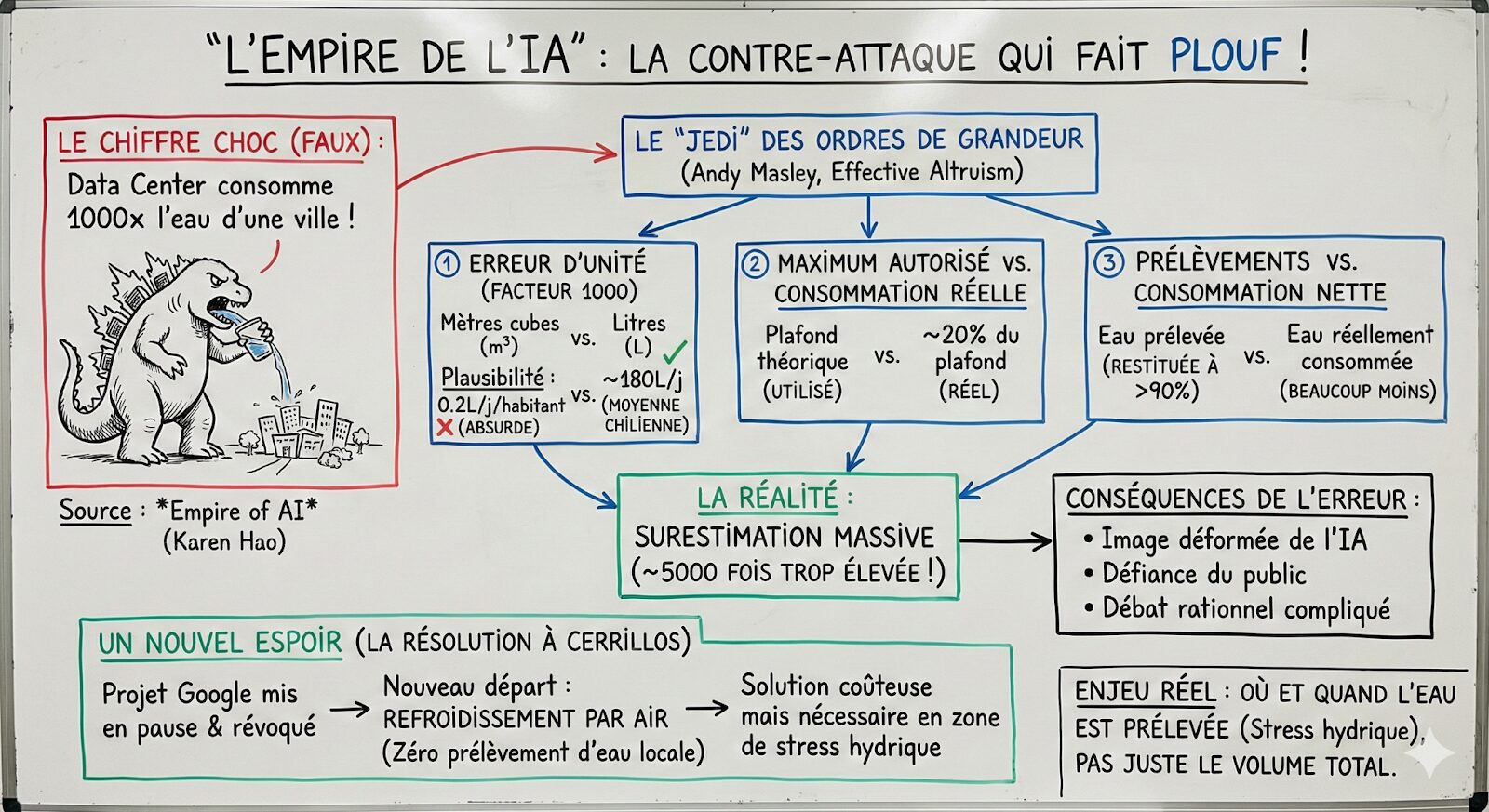
« Les populations de vertébrés sauvages ont décliné de 73 % en cinquante ans », titrait Le Monde en octobre 2024. Un chiffre alarmant, repris en boucle par de nombreux médias. Mais d’où vient-il ? Que signifie-t-il vraiment ? Et surtout : est-ce si simple de compter le vivant ?
Recenser les pandas géants n’est déjà pas une sinécure. Ces animaux emblématiques sont pourtant gros, lents et confinés à une zone géographique bien délimitée des montagnes du centre de la Chine. Lors du dernier recensement, les autorités ont estimé leur population à 1 864 individus à l’état sauvage. Un chiffre précis… en apparence. Depuis, certains pandas sont nés, d’autres sont morts, et quelques-uns échappent toujours aux radars. Alors imaginez compter toutes les formes de vie sur Terre, du virus microscopique au séquoia géant. L’exercice devient vertigineux.
On l’a vu, dans un seul gramme de sol, on peut trouver jusqu’à un milliard de bactéries, réparties en plusieurs millions d’espèces. Compter la biodiversité n’a donc rien d’une simple opération de dénombrement : c’est un défi scientifique, technologique et quasi philosophique. C’est vouloir réaliser un puzzle dont on n’a qu’une toute petite partie des pièces.
Les multiples façons de compter la vie
Les scientifiques disposent d’un arsenal impressionnant de méthodes pour tenter d’y voir clair dans le foisonnement du vivant. Certaines reposent sur le bon vieux travail de terrain : observer, capturer, noter. Les inventaires exhaustifs restent possibles pour quelques espèces emblématiques, comme le panda, d’autres grands mammifères ou encore certains arbres d’une parcelle forestière. Mais la plupart du temps, on doit se contenter d’échantillons représentatifs. On compte ce qu’il y a dans un carré de terrain (un quadrat) ou le long d’une ligne (un transect), puis on extrapole.
Pour les animaux particulièrement mobiles, on utilise la méthode « capture-marquage-recapture ». On attrape quelques individus, on les marque, puis on observe la proportion d’individus marqués lors d’une seconde capture. Une formule statistique permet alors d’estimer la population totale. Outre la mobilité, d’autres facteurs rendent ces approches de terrain compliquées : la taille (microbe ou baleine), le milieu (montagne, canopée, abysses, sol, air, désert, etc.), le mode de vie (diurne ou nocturne), la discrétion ou encore la taille de la population.
Heureusement, de nouvelles technologies viennent en renfort. Grâce à l’ADN environnemental, on peut aujourd’hui identifier les espèces présentes dans un lac en analysant simplement un échantillon d’eau. Des méthodes encore en développement sont même basées sur l’ADN retrouvé dans l’air ambiant. Chaque être vivant laisse en effet derrière lui une trace génétique, et le séquençage permet de dresser un inventaire invisible. Le barcoding génétique, lui, fonctionne comme un code-barres moléculaire : une courte séquence d’ADN suffit pour reconnaître une espèce. Quant aux drones et satellites, ils repèrent la déforestation ou les troupeaux d’éléphants. La bioacoustique, enfin, alliée à l’IA, analyse les sons de la nature pour identifier près de 15 000 espèces — oiseaux, amphibiens, mammifères, insectes — y compris sous l’eau comme sur les récifs coralliens.
Les angles morts du suivi de la biodiversité
Mais même armés des meilleurs outils, les scientifiques avancent à tâtons. Le suivi de la biodiversité souffre de biais profonds.
Le premier est un biais taxonomique. On mesure surtout ce qu’on connaît. Les mammifères, les oiseaux ou les poissons, visibles et charismatiques, sont abondamment suivis. Mais le reste du vivant — insectes, champignons, micro-organismes du sol — demeure largement dans l’ombre. Or, ces êtres invisibles constituent l’essentiel de la biodiversité et assurent le fonctionnement même des écosystèmes.
Ensuite s’ajoute un biais géographique. Les données se concentrent dans les régions où se trouvent les chercheurs, en Europe et en Amérique du Nord. À l’inverse, les véritables « hotspots » de biodiversité — forêts tropicales, récifs coralliens, zones humides d’Asie du Sud — sont souvent sous-échantillonnés, faute de moyens, d’accès ou de stabilité politique.
Le dernier biais est économique et médiatique. Surveiller un éléphant rapporte plus d’attention (et de financements) que d’étudier une colonie de fourmis. À l’arrivée, notre vision du vivant reste partielle, déséquilibrée, voire franchement déformée.
Prendre le pouls du vivant : un casse-tête ?
Mesurer la biodiversité, c’est vouloir résumer un monde infiniment complexe en quelques chiffres. Mais que mesure-t-on, au juste ? Le nombre d’espèces ? Leur abondance ? Leur répartition ? Tout cela à la fois ?
La difficulté tient aussi au fait qu’une large part du vivant nous échappe encore. On estime que seules 20 % des espèces ont été décrites, et personne ne sait combien il en reste à découvrir. À cela s’ajoute une évidence que l’on oublie souvent : les extinctions font partie de l’histoire naturelle. Environ 99 % des espèces ayant jamais vécu sur Terre ont disparu bien avant que l’humanité ne songe à compter quoi que ce soit.
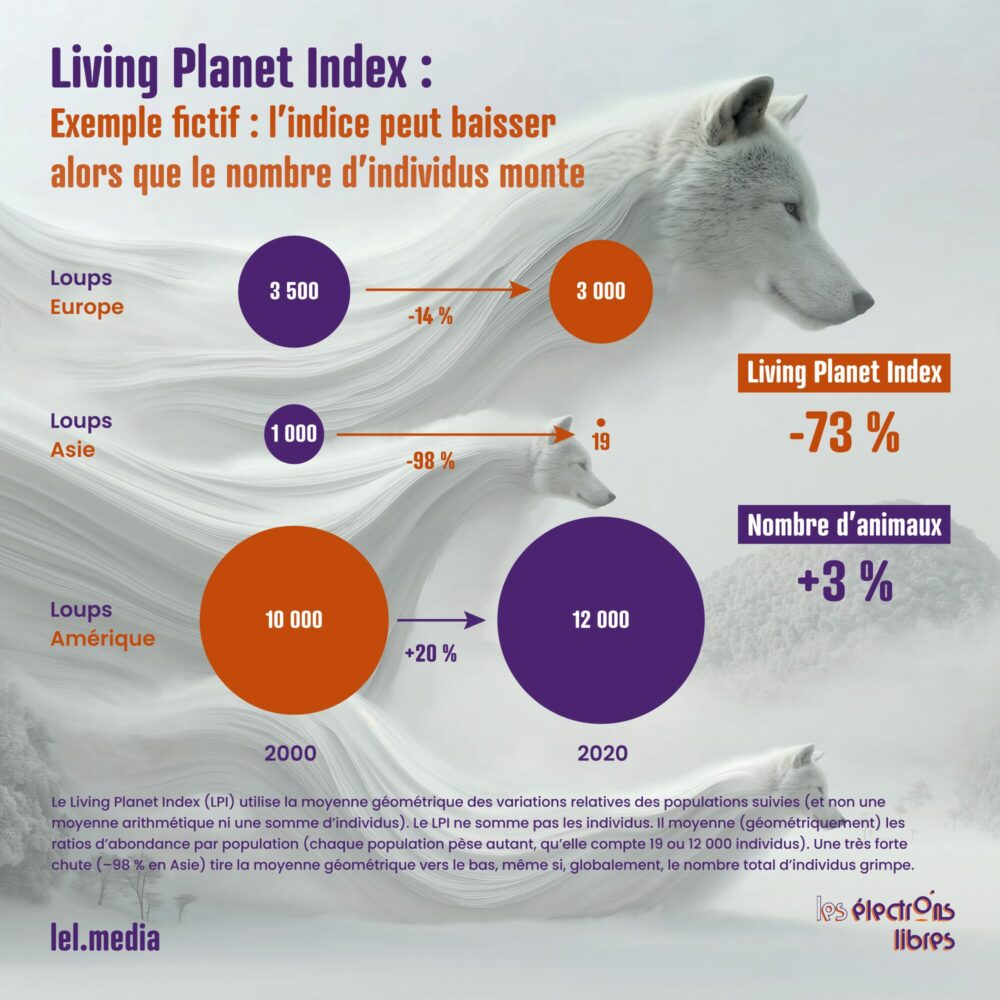
Comparer les dynamiques entre groupes d’espèces relève donc du casse-tête. Une hausse des populations de loups en Europe compense-t-elle la disparition des orangs-outans en Indonésie ? Et si les mammifères se portent mieux, cela suffit-il à relativiser le déclin des amphibiens ?
Le Living Planet Index : une compréhension en voie d’extinction
Pour tenter de synthétiser un monde foisonnant, le Living Planet Index (LPI), piloté par le WWF et la Zoological Society of London, combine les données de près de 35 000 populations animales. C’est de là que provient notre fameux chiffre choc de –73 % depuis 1970. Le résultat est spectaculaire, mais il est souvent mal interprété. Il ne signifie pas que 73 % des vertébrés sauvages ont disparu, contrairement à ce que l’on lit régulièrement. Il signifie que, parmi les 35 000 populations suivies, la baisse moyenne — calculée sans tenir compte de leur taille respective — a été de 73 %. Une nuance essentielle.
Une étude a montré que la méthode de calcul du LPI est beaucoup plus sensible aux baisses qu’aux hausses. Cette asymétrie donne un poids disproportionné à un petit nombre de populations en déclin très prononcé, ce qui tire la tendance globale vers le bas. Quant au biais géographique déjà évoqué, il fait que l’indice reflète surtout les régions du monde où les données sont abondantes, pas nécessairement celles où la biodiversité est la plus riche. Dit autrement : on mesure ce que l’on sait compter, pas forcément ce qui compte le plus.
La communauté scientifique elle-même appelle désormais à manier le LPI avec prudence. Ce n’est pas le thermomètre de la biodiversité mondiale, mais un outil utile parmi d’autres, avec ses forces, ses angles morts et ses limites.
La Liste rouge de l’UICN
Créée en 1964, la Liste rouge de l’Union internationale pour la conservation de la nature (UICN) est aujourd’hui la référence mondiale pour évaluer le risque d’extinction des espèces. Elle recense plus de 170 000 espèces évaluées et les classe dans neuf catégories, de « Préoccupation mineure » à « Éteinte », selon un protocole standardisé reposant sur cinq critères officiels (A à E) : ampleur du déclin, taille de la population, aire de répartition, fragmentation de l’habitat et probabilité d’extinction modélisée. Ce cadre homogène, validé par des experts internationaux, est utilisé par les chercheurs, les ONG et les gouvernements pour dresser un aperçu global de l’état du vivant et orienter les priorités de conservation.
La Liste rouge reflète les connaissances disponibles, qui restent très inégales selon les groupes taxonomiques, et souffre des mêmes biais que les autres indicateurs. Sa catégorisation est aussi volontairement prudente. Une species peut entrer rapidement dans une catégorie menacée dès qu’un seuil de déclin est franchi, mais en sortir exige des preuves robustes d’amélioration durable, mesurées sur dix ans ou trois générations. À cela s’ajoute un effet d’attention : les espèces en progression sont souvent moins suivies que celles en difficulté, ce qui peut retarder la validation de leur amélioration.
La mesure de la vie, entre science et humilité
Compter la biodiversité, ce n’est pas seulement accumuler des données : c’est tenter de comprendre les équilibres du vivant et d’en suivre les transformations. Les biais sont réels, les incertitudes nombreuses, mais ces travaux restent indispensables pour éclairer les décisions publiques, orienter la conservation et éviter que l’action écologique ne s’engage sur de fausses pistes.
En matière de biodiversité, les chiffres sont des balises, pas des certitudes. Ils exigent de la méthode, de la prudence et une véritable humilité devant la complexité du vivant.