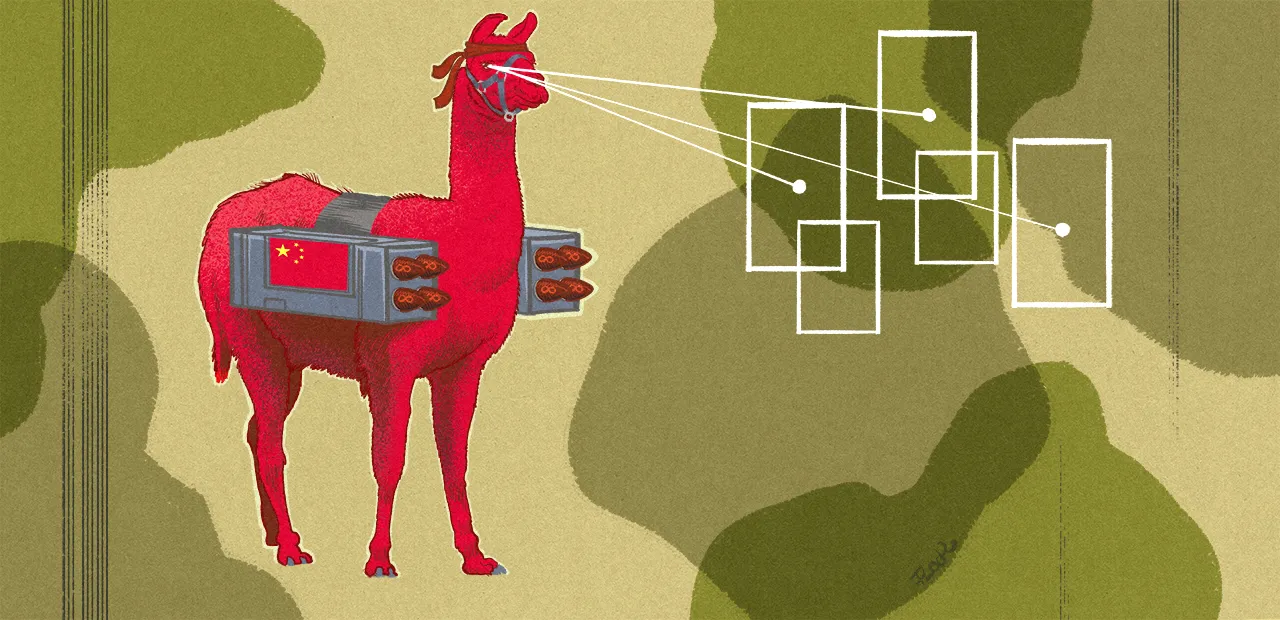
L’un des modèles de langage de la famille Llama de Meta est utilisé par des chercheurs chinois en lien avec l’armée de leur pays et pour de potentielles applications militaires. L’entreprise de Mark Zuckerberg souligne qu’elle n’a pas autorisé cette utilisation et qu’elle est contraire à sa politique d’utilisation de ses modèles.
Dans une enquête publiée ce vendredi 1er novembre, l’agence de presse Reuters explique avoir repéré le travail de chercheurs chinois s’appuyant sur un modèle de langage de la famille Llama créée par Meta. Ils l’ont utilisé pour créer un outil d’IA destiné à des fins militaires et améliorer la prise de décisions opérationnelles de l’armée chinoise.
Il reste 83% de l'article à découvrir. Vous devez être abonné•e pour lire la suite de cet article. Déjà abonné•e ? Générez une clé RSS dans votre profil.
OpenAI a annoncé jeudi 31 octobre la disponibilité de son moteur de recherche boosté à l’IA générative aux clients Plus et Team de ChatGPT.
En juillet, l’entreprise avait mis en place un « prototype temporaire » de moteur de recherche avec accès sur liste d’attente. Le service semble maintenant prêt à être utilisé par une plus grande audience.
OpenAI n’ouvre pas tout de suite toutes les vannes puisqu’elle explique que ses utilisateurs « Enterprise » et « Edu » auront accès à SearchGPT « dans les prochaines semaines » et que le délai devrait être de plusieurs mois avant l’ouverture aux utilisateurs gratuits.
L’entreprise met en avant le fait que son chatbot traite maintenant des données accessibles directement sur Internet. Elle a noué des partenariats avec des sources d’informations pour répondre en temps réel sur des sujets comme la météo, la bourse, le sport, les infos et la localisation sur des cartes.
Selon OpenAI, son chatbot donne des liens vers les sources qu’il utilise. Olivier Martinez a posté sur LinkedIn un exemple de « discussion » sur l’actualité du jour.
OpenAI cite Louis Dreyfus, PDG du groupe le Monde qui a signé un accord avec l’entreprise précédemment : « Nous sommes convaincus que la recherche par IA sera, dans un avenir proche et pour les prochaines générations, un des principaux moyens d’accès à l’information, et le partenariat avec OpenAI positionne Le Monde à l’avant-garde de ce changement. Il nous permet de tester les innovations à un stade précoce tout en préservant les valeurs fondamentales et l’intégrité du journalisme ».
En juillet dernier, Next avait montré que ChatGPT produisait de faux liens vers les médias partenaires d’OpenAI, dont Le Monde et Politico.
Après l’observation des réseaux sociaux, le Service d’information du gouvernement élargit sa veille numérique aux recherches sur les moteurs et aux signaux faibles comme les appels à rassemblements.
Depuis des décennies, l’exécutif français a passé des commandes aux entreprises de sondage pour essayer de connaître l’état de l’« opinion publique » sur tout un tas de sujets plus ou moins politiques, avec en point d’orgue l’affaire politico-financière des sondages de l’Élysée sous Nicolas Sarkozy.
Avec l’utilisation de plus en plus massive des réseaux sociaux, le Service d’information du gouvernement (SIG) a progressivement ajouté aux sondages une surveillance des réactions en ligne des Français à l’action publique et à ces sujets politiques. En 2021, le SIG avait lancé un appel d’offres de trois lots pour que des entreprises lui fournissent des outils pour faire ces analyses à chaud de l’état d’esprit des français.
Nos confrères de l’Informé ont repéré que le SIG a, cette année, élargit cette demande en créant une liste (disponible sur le Bulletin officiel des annonces des marchés publics) de cinq lots pour un montant maximal de 1,26 million d’euros hors taxes par an, soit 5,05 millions d’euros sur quatre ans.
Analyse des réseaux et des recherches en ligne
À l’écoute des réseaux sociaux (social listening, en bon français), le SIG a ajouté celle des recherches en ligne sur les moteurs (search listening) ainsi que des signaux faibles « pour distinguer ceux qui sont le plus susceptible d’impacter l’activité gouvernementale », dont les appels à rassemblement initiés sur le web.
Le premier lot est décrit comme la mesure d’impact en temps réel des contenus publics accessibles en ligne et concerne l’analyse des publications des internautes français sur Internet, aussi bien sur les réseaux sociaux, les plateformes de vidéos que la publication d’articles ou des discussions sur des forums. Les outils utilisent les diverses statistiques d’engagement pour faire remonter ou non les différents sujets au service du gouvernement.
Le lot 2 doit permettre au SIG mais aussi à d’autres services du gouvernement d’avoir des outils de suivi de ces indicateurs.
Mais comme l’ont donc remarqué nos confrères, le SIG a notamment ajouté un lot 3 pour la détection « de signaux faibles qualifiés pour distinguer ceux qui sont le plus susceptible d’impacter l’action publique ». Une fois détectés, ces signaux doivent être intégré à l’outil de reporting. Et le lot 4 est « dédié au search listening, une méthode d’analyse complémentaire de l’écoute sociale, qui permettra d’étudier les mots clés les plus spontanément recherchés (SEO / hashtags utilisés / FAQ / etc.) afin d’orienter les stratégies de communication ».
La demande porte, comme l’explique un des documents de l’appel d’offre (PDF), sur « la fourniture d’outils et d’études de social et search listening, de mesure d’impact sur les conversations en ligne pour détecter, analyser et mesurer les préoccupations et attentes des internautes vis-à-vis de l’action du Gouvernement et de l’actualité en général ». L’appel d’offre demande d’intégrer aux outils les « innovations techniques, avec notamment le déploiement de l’intelligence artificielle qui doit permettre des gains de temps significatifs dans l’exploitation fine de données toujours plus exponentielles, via notamment la proposition de tableaux de bord ou encore la détection qualifiée de signaux faibles, au-delà de l’identification de leur viralité ».
La présidentielle incluse dans la période d’analyse
Comme le souligne l’Informé, le sujet est particulièrement critique puisque plusieurs élections législatives anticipées et le scrutin présidentiel de 2027 sont inclus dans la période couverte par les cinq lots.
Le service du gouvernement justifie ces cinq lots auprès de nos confrères par la nécessité de coller aux évolutions technologiques, ce qui correspond au texte ci-dessus. À nos confrères, ce service explique ne pas avoir jugé utile de saisir la CNIL pour l’utilisation de ces données qui sont accessibles publiquement. « Les données privées dans les groupes Facebook ou comptes Instagram privés ne sont pas accessibles via les outils et ne sont pas traitées », a précisé le SIG à l’Informé.
La date limite de réponse est le mercredi 6 novembre et il faudra attendre mars prochain pour connaître les prestataires choisis.
Pour Halloween, les iconographes et documentalistes du CNRS vous proposent une galerie d’images toutes plus effrayantes les unes que les autres !
De l’embryon de souris au blob se développant sur un jouet en passant par les inévitables araignées et leur toile, les galeries de photos du CNRS regorgent de photos qui vous feront frissonner !
Alors que l’Open Source Initiative (OSI) a publié sa définition de l’IA open source, les services du gouvernement français publient un comparateur d’ouverture de ce genre de modèles pour aider à s’y retrouver et à choisir son modèle en fonction des différents critères d’ouverture.
L’Open Source Initiative (OSI) a récemment proposé sa version 1.0 de ce qu’est une IA open source. Elle reprend notamment quatre « libertés » inspirées de celles définies par la Free Software Foundation concernant le logiciel libre :
Utiliser le système à n’importe quelle fin et sans avoir à demander la permission ;
Étudier le fonctionnement du système et inspecter ses composants ;
Modifier le système dans n’importe quel but, y compris pour en changer les résultats ;
Partager le système pour que d’autres puissent l’utiliser, avec ou sans modifications, dans n’importe quel but.
Si cette définition permet une utilisation très large du modèle, elles ne sont pas toutes nécessaires à chaque projet. Certains peuvent même vouloir par eux-mêmes des restrictions. Les discussions politiques autour de ce terme sont actuellement assez vives en coulisse, alors que les textes juridiques comme l’AI Act s’y intéressent.
Le Pôle d’Expertise de la Régulation Numérique (PEReN) du gouvernement français explique, par exemple, que « [sa] philosophie [le] conduit en général à privilégier les modèles les plus ouverts, mais dont les conditions d’utilisation ne permettent pas les usages non éthiques ».
Un tableau comparatif, évolutif et coopératif
Ce service du gouvernement propose depuis mardi un comparateur de différents modèles selon les critères d’ouverture (14 modèles de générateurs de textes, 6 modèles de générateurs d’images). Quatre grandes catégories sont disponibles et on peut choisir, par exemple, si on veut (oui, non ou sans préférence) que la licence du modèle permette la redistribution, les usages commerciaux, tous les usages ou limite explicitement certains usages non-éthiques.
Le même tableau propose de filtrer selon l’accessibilité des poids, des données ou de la documentation. Le PEReN a aussi introduit dans son tableau les critères de disponibilité du code d’entrainement sous licence compatible OSI, la transparence sur l’infrastructure et le coût de l’entrainement, les articles scientifiques et ou les rapports techniques associés au modèle.
Cet outil permet à un potentiel utilisateur de choisir son modèle, mais aussi de voir que les critères d’ouverture sont multiples.
Par exemple, en un clin d’œil, il peut voir que la licence d’utilisation d’un modèle comme BLOOM, le seul du tableau dont les données sont accessibles publiquement, n’autorise pas tous les usages. À l’inverse, Mistral, pour l’utilisation de son modèle NeMo, permet de faire tout et n’importe quoi avec, mais ne fournit pas de documentation complète sur l’origine de ses données d’entrainement.
Un modèle comme Claire-7B, créé par Linagora, utilise la licence Creative Commons By-NC-SA et ne peut être utilisé à des fins commerciaux.
Le service du gouvernement français permet à tout un chacun de réutiliser « librement » cette page comme source et encourage à le contacter pour ajouter des références ou des corrections. Le tableau « se veut collaboratif et dynamique et sera amené à évoluer ».
Une attention à avoir sur la gouvernance
Le PEReN diffuse aussi un document d’éclairage sur l’Open source et l’IA [PDF]. Daté d’avril 2024 (donc avant la publication de la version 1.0 de la définition de l’OSI), il aborde les synergies possibles, du point de vue de ce service, entre open source et IA.
Il aborde notamment la diversité des gouvernances possibles dans cet écosystème et pointe les difficultés. Il prend appui sur l’exemple du système d’exploitation open source Android (via AOSP), « emblématique selon Google de l’open source » mais qui « est de facto sous le contrôle de cette entreprise, qui a pu s’assurer la maîtrise complète de l’écosystème, au point d’avoir été sanctionnée pour pratiques anticoncurrentielles par la Commission Européenne ».
« La qualité d’open source n’apparaissant pas suffisante pour prémunir de dérives, il semble nécessaire de rester particulièrement vigilant à la forme de gouvernance qui peut sous-tendre les projets open source dans le domaine de l’IAG », ajoute le PEReN.
En octobre, Matt Mullenweg a proposé deux offres de départ aux salariés de son entreprise Automattic, dans le cadre du conflit juridique et commercial qu’il a engendré contre son concurrent WP Engine, qualifiant celui-ci de « cancer de WordPress ». Lors d’une conférence organisée par TechCrunch ce mercredi, le co-créateur du logiciel WordPress a avoué que son entreprise était maintenant « très en manque de personnel ».
Matt Mullenweg n’a pas révélé le nombre de départs lors de la seconde offre. Néanmoins, il avait annoncé que 159 salariés avaient sauté sur l’occasion de la première. Il a confirmé lors de cette conférence que son entreprise était passée d’environ 1 900 salariés à environ 1 700 depuis le début de ce conflit ouvert, tout en embauchant 26 personnes.
Cette déclaration d’un manque de personnel vient confirmer que les deux offres visaient à trouver les sources internes des informations sur ce qu’il se passait au sein d’Automattic pendant le conflit. Lors de l’annonce de la seconde offre, Matt Mullenweg avait affirmé avoir « les moyens d’identifier les sources des fuites » et que la proposition était une « opportunité de se retirer de façon élégante ».
Au cours de cette conférence, en réponse à une question sur la création d’un éventuel fork de WordPress suite à l’ouverture de ce conflit, le co-créateur du logiciel a encouragé l’idée : « je pense que ce serait fantastique pour que les gens puissent avoir une autre gouvernance ou une autre approche ». Matt Mullenweg a affirmé que le logiciel avait déjà été « forké » plusieurs fois et a ajouté que « c’est l’une des grandes qualités de l’open source : un fork peut être créé ».
Selon le Wall Street Journal, l’entreprise de gestion de paiement planifie de restructurer ses activités internationales et de supprimer 1 400 postes (employés ou sous-traitants) avant la fin de l’année.
Les salariés ont appris la nouvelle la semaine dernière via une annonce interne. Plus d’un tiers des postes (environ 1 000) devraient concerner des emplois du secteur technologique, le reste devrait être réparti sur le service commercial et celui des partenariats numériques internationaux. Les licenciements ont déjà commencé la semaine dernière.
Le journal américain rappelle que Visa a plus de 30 000 employés dans le monde.
Interrogé par le Wall Street Journal, Visa a déclaré qu’elle évoluait en permanence pour servir au mieux ses clients et soutenir sa croissance, « ce qui peut entraîner la suppression de certaines fonctions ». Elle affirme s’attendre à embaucher davantage les prochaines années.
Depuis un an, les entreprises d’IA générative promettent d’ajouter des filigranes à leurs contenus. Google propose désormais son système nommé SynthID. Les chercheurs de Google DeepMind ont notamment décrit dans un article dans la revue Nature et publié sous licence libre la partie concernant les textes générés automatiquement.
Dans les divers problèmes liés aux contenus générés par l’IA, le fait de pouvoir les différencier de ceux créés autrement a été rapidement repéré comme le nez au milieu d’un visage. Les détecteurs d’IA générative sont pointés du doigt pour leurs faux positifs, ce qui engendre des tensions entre étudiants et enseignants.
Depuis l’avènement dans l’espace public de ces systèmes, l’ajout à ces contenus de filigranes est régulièrement évoqué pour qu’une sorte de tampon « made by AI » leur soit clairement assigné. OpenAI, Alphabet, Meta, Anthropic, Inflection, Amazon et Microsoft ont d’ailleurs promis à la Maison-Blanche l’an dernier de mettre en place ce système. En Europe, l’AI Act exige que cette disposition soit mise en place à partir du 2 aout 2026.
En aout, on apprenait qu’OpenAI avait mis en place un système permettant de tatouer les textes générés par ses IA. Mais l’entreprise hésitait à le mettre en place. En effet, cette technologie serait « efficace à 99,9 % », mais elle serait aussi relativement simple à supprimer.
Google vient, elle, de sauter le pas avec son système nommé « SynthID » développé par sa filiale DeepMind. L’entreprise indique que cet outil embarque « des filigranes numériques directement dans les images, le son, le texte ou la vidéo générés par l’IA ».
Bien sûr, le système de tatouage des divers contenus est différent selon le média. Il n’est pas possible, par exemple, d’utiliser un système de tatouage graphique pour identifier un texte. Et, à moins de trouver un très bon filigrane universel, le risque est d’harmoniser vers le bas l’utilisation de ces marques pour tous les types de médias.
Google a donc mis au point différents systèmes de filigranes dont elle présente des exemples.
Un outil libre de filigranes pour la génération de textes
Pour son système dédié aux filigranes de textes générés par IA, Google DeepMind a publié le travail de ses 24 chercheurs dans la revue scientifique Nature la semaine dernière. L’idée est de créer une « signature statistique » dans le texte généré en modifiant légèrement la procédure de génération de chaque « prochain jeton ». Cette modification ne dépend pas d’une simple variable statique, mais se fait en fonction du contexte de génération.
« L’un des principaux avantages de cette approche est que le processus de détection ne nécessite pas la réalisation d’opérations coûteuses en termes de calcul, ni même l’accès au LLM sous-jacent (qui est souvent propriétaire) », expliquent-ils.
La détection se fait avec un outil probabiliste qui prend en entrée le texte à vérifier et une clé de filigrane spécifique.
L’entreprise a publié sur GitHub sous licence libre (Apache 2.0) cet outil et propose une documentation détaillée pour les développeurs d’IA génératives qui voudraient l’utiliser. Dans celle-ci , elle explique que SynthID Text propose plusieurs options pour la vérification : full-private qui « ne libère ni n’expose le détecteur d’aucune manière », semi-private qui « ne libère pas le détecteur, mais expose via une API » et public qui « permet de libérer le détecteur pour que d’autres utilisateurs puissent le télécharger et l’utiliser ».
Elle assure que « les filigranes de texte SynthID résistent à certaines transformations, c’est-à-dire les recadrages de texte, en modifiant quelques mots ou en paraphrasant légèrement ». Mais Google admet que sa méthode, comme celle d’OpenAI, a des limites qui permettent de facilement contourner son système :
« L’application de filigranes est moins efficace sur les réponses factuelles, car il y a moins de possibilités d’augmenter la génération sans réduire la précision.
Les scores de confiance du détecteur peuvent être considérablement réduits lorsqu’un texte généré par IA est entièrement réécrit ou traduit dans une autre langue ».
Google se garde l’exclusivité de ses outils de filigrane d’audio et d’images
Toutefois, concernant les filigranes d’audio, d’images et de vidéos, l’entreprise se contente de présenter succinctement des exemples d’utilisation qui, bien évidemment, ne montrent aucune différence entre le contenu sans filigrane et avec. Mais l’entreprise ne communique ni sur le fonctionnement des systèmes mis en place ni sur leurs limites.
Elle ajoute que ces filigranes sont disponibles pour les clients de Vertex AI qui utilisent les modèles de conversion de texte en image Imagen (version 2 et 3), pour les utilisateurs de son outil de génération d’images ImageFX et pour les quelques créateurs qui ont accès à son modèle de génération de vidéos Veo.
Selon l’agence de presse Reuters, OpenAI cherche à minimiser le coût des puces dont elle a besoin pour développer ses systèmes d’intelligence artificielle générative.
Après avoir imaginé des plans ambitieux pour devenir son propre fondeur, l’entreprise les aurait abandonnés pour leur coût trop élevé et un temps de développement trop long. Elle se serait alors rapprochée de Broadcom et de TSMC. Elle se rabattrait donc plutôt sur un design maison de ses puces.
OpenAI cherche aussi à diversifier son approvisionnement actuel en GPU et devrait plus se tourner vers les puces MI300X d’AMD.
Comme le rappelle Reuters, l’entrainement des modèles d’IA générative sur ces puces est particulièrement coûteux. OpenAI prévoit pour cette année 5 milliards de dollars de perte pour un chiffre d’affaires de 3,7 milliards de dollars.
Le PDG de l’entreprise de sécurité pour le cloud computing Wiz, Assaf Rappaport, a expliqué lors d’une conférence organisée par TechCrunch que son entreprise a été ciblée par une attaque utilisant un deepfake mi-octobre.
Il a raconté au média américain que « des dizaines de mes employés ont reçu un message vocal de ma part ». Comme c’est souvent le cas dans ce genre d’attaque, celle-ci « tentait d’obtenir leurs informations d’identification », a-t-il ajouté.
Selon le PDG, c’est une particularité de la source originale qui aurait mis la puce à l’oreille de ses salariés. L’audio utilisé venait d’une conférence. Or, Assaf Rappaport est particulièrement anxieux quand il doit parler en public, ce qui modifie sa façon de s’exprimer. Le deepfake ne ressemblait pas à sa voix de tous les jours pour eux.
Wiz a pu retrouver la source de cet audio mais n’est pas en mesure de savoir de qui est provenue l’attaque.
Assaf Rappaport a aussi expliqué son refus de l’offre d’achat proposée par Google cet été. Si le montant de celle-ci était de 23 milliards de dollars, le PDG de Wiz considère que son entreprise peut atteindre les 100 milliards de dollars parce que la sécurité du cloud, c’est le futur. C’était « la décision la plus difficile à prendre », a-t-il quand même ajouté.
L’Open Source Initiative (OSI) a publié ce lundi la version finale de sa définition de l’IA open-source. Celle-ci diffère encore un peu de la release candidate diffusée mi-octobre. Comme on pouvait s’en douter aux vues des tensions entre l’OSI et Meta, la définition exclut les modèles de l’entreprise, qui se revendique pourtant leader de l’IA open source.
Comme elle l’avait annoncé, l’Open Source Initiative (OSI) a publié la version 1.0 de sa définition de l’IA open-source. Ce texte, rédigé en collaboration avec différents experts venant de la recherche et de l’industrie, a pour ambition d’adapter la définition de l’open source et les quatre libertés essentielles au monde des modèles d’intelligence artificielle.
Dans son billet de blog, l’OSI explique qu’elle est « le résultat de plusieurs années de recherche et de collaboration, d’une tournée internationale d’ateliers et d’un processus de co-conception d’un an mené par l’Open Source Initiative (OSI), mondialement reconnue par les particuliers, les entreprises et les institutions publiques comme l’autorité qui définit l’Open Source ».
La définition insiste encore plus sur la description des données d’entrainement
Comparée à la version Release Candidate dont nous avions déjà parlé, la base du texte reste évidemment la même. Mais quelques modifications ont quand même été ajoutées.
L’OSI exige maintenant une description « complète » des données utilisées pour entrainer le modèle. Dans sa version RC, l’organisme ne demandait qu’une version « détaillée ». Cette précision renforce l’obligation d’information sur les données d’entrainement.
La définition a été, pendant son processus, critiquée pour accepter que cette description remplace le fait de publier de façon effective les données d’entrainement. L’utilisation de ce terme dans la version finale de la définition vient appuyer l’idée qu’à défaut de les publier, les créateurs de modèles doivent vraiment détailler les informations concernant leurs données d’entrainement.
Cette version insiste aussi, contrairement aux précédentes, sur le processus de filtrage utilisé sur les données collectées pour entrainer les modèles. La méthodologie de ce processus doit être détaillée et le code qui la met en place doit être publié.
Pas de contrainte sur la manière de publier les paramètres
Un dernier paragraphe a été ajouté à la définition pour préciser qu’elle n’exige pas, pour l’instant, de licence spécifique pour les paramètres du modèle : « la définition de l’IA Open Source n’exige pas de mécanisme juridique spécifique pour garantir que les paramètres du modèle sont librement accessibles à tous. Ils peuvent être libres par nature ou une licence ou un autre instrument juridique peut être nécessaire pour garantir leur liberté. Nous pensons que cela deviendra plus clair avec le temps, une fois que le système juridique aura eu l’occasion de se pencher sur les systèmes d’IA open-source ».
Meta fâchée
Comme nous l’avions déjà noté, cette définition crée des tensions entre l’OSI et Meta, qui revendique haut et fort le caractère « open-source » de ses modèles Llama. L’entreprise de Mark Zuckerberg ne détaille notamment pas les données sur lesquelles sont entrainés ses modèles. Comme expliqué plus haut, si l’OSI a rapidement fait des concessions sur la possibilité de ne pas publier les données d’entrainement, elle a encore resserré ses exigences d’information les concernant.
À The Verge, Meta affirme être « d’accord avec [son] partenaire OSI sur de nombreux points », mais pas sur tous, ce qui la pousse à contester le consensus : « il n’existe pas de définition unique de l’IA open source, et la définir est un défi, car les définitions précédentes de l’open source n’englobent pas les complexités des modèles d’IA d’aujourd’hui qui progressent rapidement ».
Malgré ce désaccord avec Meta, la définition a acquis le ralliement d’autres acteurs du secteur. « La nouvelle définition exige que les modèles open source fournissent suffisamment d’informations sur leurs données d’entraînement pour qu’une « personne compétente puisse recréer un système substantiellement équivalent en utilisant des données identiques ou similaires », ce qui va plus loin que ce que font aujourd’hui de nombreux modèles propriétaires ou qui sont open source d’apparence », selon Ayah Bdeir, responsable IA chez Mozilla.
Pour Clément Delangue d’Hugging Face, cette définition est « une aide considérable dans l’élaboration de la conversation sur l’ouverture de l’IA, en particulier en ce qui concerne le rôle crucial des données d’entraînement ».
Un homme de 27 ans a été condamné à 18 ans de prison au Royaume-Uni pour avoir fabriqué des images d’abus sexuels sur des enfants, explique le Guardian. Utilisant des photos « normales » de vrais enfants, il les a transformés avec le logiciel de création de modèles humains DAZ 3D en images de viols. Ici, contrairement aux « deepfakes » où une tête est transférée sur un autre corps, Hugh Nelson, l’auteur de ces images, a créé complètement les personnages et les scènes.
La police britannique a découvert qu’il les vendait sur internet via des forums de discussion, engrangeant 5 000 Livres sterling (6 000 euros) sur une période de 18 mois. Le journal britannique explique qu’il a, dans certains cas, fourni des images en utilisant des photos d’enfants proches de ses clients.
Le juge Martin Walsh qui a condamné Hugh Nelson a déclaré qu’il était « impossible de savoir » si des enfants avaient été violés à la suite de la création de ses images et que l’auteur ne s’était pas soucié du préjudice causé par la diffusion de ce matériel « déchirant et écœurant ».
Il a pu être arrêté après qu’il a proposé à un policier en couverture la création d’un nouveau personnage pour 80 livres sterling (95 euros).
L’Internet Watch Foundation s’alarmait récemment du franchissement d’un « point de bascule » concernant les images d’abus sexuels d’enfants générées par IA.
En 20 ans d’Internet, de partage et de publication massive de contenus soumis au copyright, le discours public a évolué. Il est passé d’une condamnation totale des pratiques d’échanges entre utilisateurs pairs à pairs à une acceptation tacite de l’entrainement des IA génératives, parfois sur les mêmes masses de données, pourvu que les données ne soient pas nommément citées.
Entre la répression contre les figures symboliques du partage de fichiers sur Internet – Shawn Fanning, Aaron Swartz et Alexandra Elbakyan – et l’utilisation massive des bases de données d’œuvres protégées par le Copyright par les entreprises de l’IA générative, le discours public et politique a bifurqué. D’un tout répressif dont le point d’orgue en France a été la loi Hadopi, nous sommes passés au jet d’un voile pudique sur l’utilisation de données culturelles par les startups qui promettent d’être les prochaines licornes de l’IA.
De la fin des années 90 à celle des années 2010, les politiques du numérique ont notamment été portées par la volonté de protéger du piratage les contenus numériques comme les musiques, les films, mais aussi les livres et les articles scientifiques.
Il reste 86% de l'article à découvrir. Vous devez être abonné•e pour lire la suite de cet article. Déjà abonné•e ? Générez une clé RSS dans votre profil.
L’agence de presse britannique a signé un accord avec Meta permettant aux chatbots de l’entreprise de Mark Zuckerberg d’utiliser ses contenus.
C’est le premier accord du genre signé par Meta. Son concurrent OpenAI a, quant à lui, signé plusieurs accords, notamment avec le groupe Condé Nast.
Aucune information sur le montant de l’accord n’a été divulguée. Selon Axios, si l’accord permet bien à Meta de proposer des réponses en temps réel aux utilisateurs de Facebook, Instagram, WhatsApp et Messenger via son chatbot, il n’est pas clair qu’il laisse la possibilité à l’entreprise d’entrainer ses grands modèles de langage sur les contenus de l’agence de presse.
Axios rappelle que Meta a conclu ce genre d’accords en 2019 pour afficher les contenus de divers médias dans l’onglet « news » de Facebook avant d’abandonner cette fonctionnalité. Les contenus de l’agence de presse Reuters ne faisaient pas partie de ceux repris dans cet onglet à l’époque.
Reuters a publié une dépêche sur le sujet sans pour autant révéler plus d’informations sur le sujet.
Satellites of love ... and beaucoup de trash aussi
Des chercheurs en astrophysique ont signé une lettre envoyée à la Federal Communications Commission (FCC), l’autorité de régulation américaine, lui demandant de mettre fin à l’ « absurde » exemption qu’elle a accordée aux opérateurs satellite concernant les normes environnementales à respecter.
De plus en plus de travaux scientifiques pointent les problèmes environnementaux qu’engendrent les constellations de satellites en orbite terrestre basse comme Starlink, Kuiper ou encore OneWeb.
Jeudi 24 octobre, 120 astrophysiciens ont envoyé une lettre qui reproche au régulateur américain, la Federal Communications Commission (FCC), de ne pas remplir son rôle concernant ces constellations. L’association de consommateurs américaine Public Interest Research Group l’a rendue publique [PDF].
Les chercheurs font le constat que « le nombre de satellites de taille importante en orbite terrestre basse au niveau le plus bas a été multiplié par 127 et le nombre total de gros satellites en orbite terrestre basse a été multiplié par 12 en cinq ans, sous l’impulsion de SpaceX ».
500 000 satellites pour toutes les méga-constellations
Et comme on le sait, ils rappellent que cette augmentation du nombre de satellites lancés dans l’espace est loin de s’arrêter : « la nouvelle course à l’espace s’accélère rapidement : certains experts estiment que 58 000 satellites supplémentaires seront lancés d’ici 2030. D’autres plans ont été proposés pour lancer 500 000 satellites afin de créer de nouvelles méga-constellations qui alimenteraient l’internet par satellite ».
Mais, pour ces scientifiques, « nous devrions regarder avant de sauter ». C’est-à-dire analyser les effets de ces lancements sur notre environnement avant de s’engager dans cette course.
« Les effets néfastes sur l’environnement du lancement et de la combustion d’un si grand nombre de satellites ne sont pas clairs », estiment-ils. Ils s’appuient notamment sur le fait que « le gouvernement fédéral [américain] n’a pas réalisé d’étude environnementale pour en comprendre les effets ». Mais ils ajoutent que « ce que nous savons, c’est qu’un plus grand nombre de satellites et de lancements entraîne une augmentation des gaz et des métaux nocifs dans notre atmosphère ». On sait, par exemple, que leur dégradation, tous les cinq ans quand ils redescendent dans l’atmosphère, endommage la couche d’ozone.
« Nous ne devrions pas nous précipiter pour lancer des satellites à cette échelle sans nous assurer que les avantages justifient les conséquences potentielles du lancement de ces nouvelles méga-constellations, qui rentrent ensuite dans notre atmosphère pour y brûler ou y créer des débris » assènent-ils.
Une pause dans les lancements et une vraie étude d’impact de la FCC demandées
Ces chercheurs demandent donc à la FCC de reprendre les choses depuis le départ et de mettre en pause tous les lancements de ces satellites tant qu’elle n’a pas conduit une véritable étude d’impact environnemental. Ils font remarquer que « la course du new space a démarré plus rapidement que les gouvernements n’ont pu agir ». Les agences de régulation examinent les licences individuelles et ne disposent pas des politiques nécessaires pour évaluer les effets globaux de toutes les méga-constellations proposées.
Et ils font remarquer que la FCC « contourne l’obligation de contrôle environnemental des méga-constellations de satellites prévue par la loi sur la politique environnementale nationale (National Environmental Policy Act) en invoquant une exclusion catégorique ». Ils s’appuient sur un constat déjà fait par le Government Accountability Office américain (organisme d’audit, équivalent de la Cour des comptes) en 2022. « En mai 2024, la FCC n’a pas réexaminé ses règles et continuait à exclure les constellations de satellites du contrôle environnemental », affirment-ils.
Selon nos confrères du Monde, le journal Libération est actuellement touché par une cyberattaque utilisant un rançongiciel. Si le média a pu publier des articles sur son site internet, plusieurs logiciels – dont celui de mise en page de la version papier du journal – sont actuellement inutilisables par les salariés.
La direction du journal a prévenu la rédaction par email vendredi en fin de matinée en demandant aux salariés de privilégier le télétravail ce jour-ci et de ne pas utiliser le réseau Wi-Fi interne.
En septembre, c’était le groupe Bayard et notamment son journal La Croix qui étaient touchés par une attaque de ce type. L’Agence France Presse a aussi été ciblée très récemment.
L’entreprise qui propose des services d’auto-école en ligne a signalé à ses clients, via un email qu’un lecteur nous a transféré, une « intrusion externe dans le système d’information d’Ornikar qui a exposé vos informations personnelles suivantes : nom, prénom, e-mail, numéro de téléphone, date de naissance et adresse postale ».
Ornikar leur assure que leurs données bancaires et leurs mots de passe n’ont pas été compromis. Elle ajoute avoir déclaré l’incident à la CNIL, conformément à la réglementation.
Selon Saxx, 4,3 millions de comptes seraient concernés.
Contactée par Next, l’entreprise n’a pas répondu à notre sollicitation.
Des études récentes montrent que les grands modèles de langage ont de bons résultats dans les tests de comparaison car ceux-ci correspondent aux données sur lesquelles ils ont été entrainés. Il suffit d’une petite variation dans le test pour que les performances s’effondrent.
Depuis l’arrivée des grands modèles de langage (large language models, LLM), le débat sur leur capacité de raisonnement oppose les ingénieurs et chercheurs du domaine.
Certains prétendent que ces modèles permettent de créer des intelligences artificielles qui raisonnent, d’autres que ce sont de simples perroquets récitant statistiquement ce qui se trouve dans leurs données d’entrainement.
Les premiers s’appuient sur des tests de raisonnement (benchmarks) pour comparer leurs résultats à ceux de leurs concurrents et de leurs anciennes versions. De mois en mois, ils observent les scores augmenter petit à petit et certains se disent qu’un jour ou l’autre, grâce aux modèles de langage, la machine dépassera les capacités humaines.
Les autres s’appuient notamment sur le principe sur lequel ont été fondés les LLM pour expliquer qu’ils n’utilisent que des modèles de raisonnement qu’ils ont mémorisés à partir de leurs données d’entrainement. Bref, comme le disaient déjà en 2020 Emily Bender, Timnit Gebru, Angelina McMillan-Major et Margaret Mitchell, les LLM ne seraient que des « perroquets stochastiques ».
Plusieurs études récentes montrent que les « benchmarks » ne permettent pas de mesurer les capacités de raisonnement de ces modèles, mais plutôt leurs capacités à … répondre de façon fidèle à ces tests. Car les résultats s’effondrent quand les chercheurs leur font passer des tests similaires, mais présentant d’infimes variations.
Il reste 89% de l'article à découvrir. Vous devez être abonné•e pour lire la suite de cet article. Déjà abonné•e ? Générez une clé RSS dans votre profil.
Selon l’agence de presse Reuters, l’autorité britannique de la concurrence (Competition and Markets Authority, CMA) a lancé formellement une enquête sur les liens entre la maison mère de Google, Alphabet, et la startup d’intelligence artificielle Anthropic.
Fin juillet, l’autorité examinait déjà cette relation de façon plus informelle en invitant toute personne connaissant le dossier à lui fournir des informations. Elle est maintenant passée à la vitesse supérieure et se donne jusqu’au 19 décembre pour accomplir la première phase de son enquête formelle.
À Reuters, Anthropic déclare être « une entreprise indépendante et aucun de nos partenariats stratégiques ou de nos relations avec les investisseurs ne diminue l’indépendance de notre gouvernance d’entreprise ou notre liberté de s’associer avec d’autres ».
Du côté de Google, l’entreprise assure qu’ « Anthropic est libre d’utiliser plusieurs fournisseurs de cloud et de le faire, nous n’exigeons pas de droits technologiques exclusifs ».
Les diverses autorités de la concurrence scrutent depuis quelques mois les liens entre les différentes startups leaders de l’IA générative et les multinationales du numérique. Fin juin, l’autorité française alertait de « risques potentiels » ciblant notamment la relation entre Microsoft et OpenAI et les investissements d’Amazon et Alphabet dans Anthropic.
Aux États-Unis, la FTC enquête depuis janvier sur ces éventuels problèmes de concurrence.
Les entreprises d’IA générative avaient prévenu que les outils de détection de contenus générés par des IA n’étaient pas efficaces. Leur taux de faux positifs est loin d’être nul, menant à des accusations parfois erronées alors que leur utilisation est massive dans les universités.
Même la foire aux questions d’OpenAI l’explique depuis quelque temps : « Alors que certains (y compris OpenAI) ont publié des outils prétendant détecter du contenu généré par une IA, aucun d’entre eux n’a prouvé qu’il établissait une distinction fiable entre ce type de contenu et celui généré par l’homme ».
Et pourtant, ils sont massivement utilisés dans les universités pour vérifier le travail des étudiants. Bloomberg explique que les deux tiers des enseignants américains utilisent des détecteurs d’IA générative pour repérer des textes qui ne seraient pas écrits par les étudiants.
2 à 3 % de faux positifs
Or, le média américain a testé deux des détecteurs les plus utilisés, GPTZero et Copyleaks sur un échantillon de 500 copies rédigées et soumises à correction durant l’été 2022, alors que ChatGPT n’était pas encore sorti. Résultats : 488 dissertations ont été considérées comme écrites par un humain, neuf ont été étiquetées comme partiellement générées par IA et partiellement rédigées par un humain, et trois ont été étiquetées comme entièrement générées par IA. Ce taux peut paraître bas, mais il représente nombre de fausses accusations au vu du nombre de copies.
D’autant que, comme l’explique Bloomberg, les accusations erronées tombent plus souvent sur des étudiants au style d’écriture plus « générique ». En effet, celui des étudiants dont la langue d’examen (ici l’anglais) n’est pas leur langue maternelle, de ceux qui ont simplement appris un style plus simple et mécanique ou des personnes dites neuroatypiques, peut plus facilement être confondu avec un texte généré par une IA.
Le média américain a recueilli le témoignage d’une étudiante neuroatypique accusée de triche par son université et qui a reçu cette accusation comme un « coup de poing dans le ventre ». Un autre étudiant, d’origine italienne et qui a obtenu un 0, se dit accablé. Il explique que son enseignant n’en démord pas, ayant passé le texte dans plusieurs détecteurs qui donnent tous le même résultat.
En juillet 2023, une étude scientifique montrait déjà les biais de ce genre de détecteurs sur les textes en anglais rédigés par des personnes non-nativement anglophones.
Utilisation « moralement problématique »
Sur X, en réaction à l’article de Bloomberg, Ethan Mollick, enseignant chercheur à l’Université Wharton de Californie, affirme qu’ « il est moralement problématique d’utiliser des détecteurs d’IA lorsqu’ils produisent des faux positifs qui salissent les étudiants d’une manière qui leur porte préjudice et alors qu’ils ne peuvent jamais prouver leur innocence ». Il ajoute, insistant : « ne les utilisez pas ».
Certains enseignants appliquent ce conseil et ont adapté leurs évaluations, soit en incorporant l’utilisation des IA dans leur enseignement, soit en modifiant leurs exigences pour qu’elles soient moins facilement atteignables à l’aide d’une IA. Mais Bloomberg montre que le business derrière la détection de textes générés par IA est florissant, puisque le leader du secteur, GPTZero, a levé 13,5 millions de dollars depuis sa création début 2023 et revendique 4 millions d’utilisateurs.
Si ces entreprises clament ne pas vouloir être prises pour des juges, il est difficile de savoir que faire de leurs résultats puisqu’une fois un texte étiqueté comme généré par une IA, il est impossible de savoir s’il s’agit d’un faux positif ou pas.
Le média américain explique que certains étudiants utilisent ces logiciels, à leur tour, pour vérifier que leurs textes ne sont pas faussement détectés comme générés par des IA, et les modifient s’ils le sont. Bloomberg ajoute que l’utilisation d’un logiciel d’aide à l’écriture comme Grammarly (qui donne des conseils de tournure de phrases) peut faire passer rapidement un texte détecté comme « 100 % écrit par un humain » à « 100 % généré par une IA ».













![[Édito] De Napster à OpenAI : le copyright sacrifié sur l’autel de l’IA](https://next.ink/wp-content/uploads/2024/10/Hold-up.webp)





