Une multitude d’applications ont été créées ces derniers mois dans l’ « ATmosphere », l’écosystème construit autour du protocole AT, aux fondements du réseau social Bluesky. Avec Eurosky, il est désormais possible d’y accéder et d’en profiter depuis des serveurs européens. Next vous explique.
Vous avez entendu parler de Bluesky, l’une des alternatives à X, mais connaissez-vous Eurosky ? Nous non plus, en tout cas pas beaucoup plus que de nom, avant de nous être lancés dans nos expérimentations. Dans un précédent article, je testais Mu, réseau social porté par la Modal Foundation, une organisation installée aux Pays-Bas.
Comme j’étais déjà équipée d’un compte Bluesky, la démarche a été relativement simple : par la magie de l’architecture technique ouverte du protocole AT, sur lequel sont construits les deux réseaux sociaux, j’ai pu simplement utiliser mon compte Bluesky pour me connecter à Mu.
Sauf que cette expérience en appelait une autre, proposée bien en évidence dans mon parcours d’utilisatrice : transférer complètement mon compte, jusqu’ici hébergé par la société états-unienne Bluesky, vers la plateforme européenne Eurosky. Pour qui se préoccupe de souveraineté numérique, la proposition était alléchante. Mais elle soulevait plusieurs questions : qui me proposait ce déménagement ? Qu’est-ce que j’allais déménager exactement ? Et dans quelle mesure cela modifierait-il mon expérience de Bluesky et des autres applications de l’ATmosphere, cet écosystème d’outils installés sur le protocole AT ?
La réponse à la première question est la plus simple : c’est la Modal Foundation, encore elle, qui me proposait ce déménagement. Créée en novembre 2025, cette organisation à but non lucratif se présente comme « œuvrant au soutien de technologies sociales décentralisées qui aident les gens à créer, partager et découvrir de l’information de confiance ». Elle est partie prenante de la campagne FreeOurFeeds, qui vise depuis janvier 2025 à réunir les fonds nécessaires pour créer un écosystème social plus décentralisé que Bluesky ne l’est pour le moment, et surtout bien différent des modèles proposés par les classiques X, Facebook ou Instagram. Elle est aussi co-signataire, aux côtés de Mastodon, Framasoft, ou de la Social Web Foundation, d’un appel pour la création d’une « pile sociale européenne » (European social stack), c’est-à-dire d’une série d’outils technologiques ouverts (pour la partie réseaux sociaux) et sécurisés (surtout pour la partie messagerie) construits depuis l’Europe.
Avec Eurosky et des applications concrètes comme le réseau social Mu, la Modal Foundation cherche à proposer un autre modèle numérique que celui des géants états-uniens, en l’ancrant au sein de l’Union européenne. Nous détaillerons ces considérations économico-politiques dans un prochain article, mais dans la mesure où l’ONG porte aussi ce projet par l’exemple, c’est-à-dire en fournissant des services concrets, suivez-nous dans notre promenade numérique depuis leur service.
Déménager du ciel bleu vers le ciel européen
L’une des prémisses du fonctionnement du protocole AT consiste à vous laisser la main sur un serveur de données personnelles (Personal data server, PDS). Nous le détaillions plus longuement ici, mais pour faire simple, c’est ce véhicule, qui stocke le nom de connexion, les mots de passe, les clés cryptographiques, mais aussi les publications et la liste des personnes suivies, qui permet à un internaute de recourir à de multiples services sans se défaire de la communauté déjà construite.
Il reste 75% de l'article à découvrir. Vous devez être abonné•e pour lire la suite de cet article. Déjà abonné•e ? Générez une clé RSS dans votre profil.
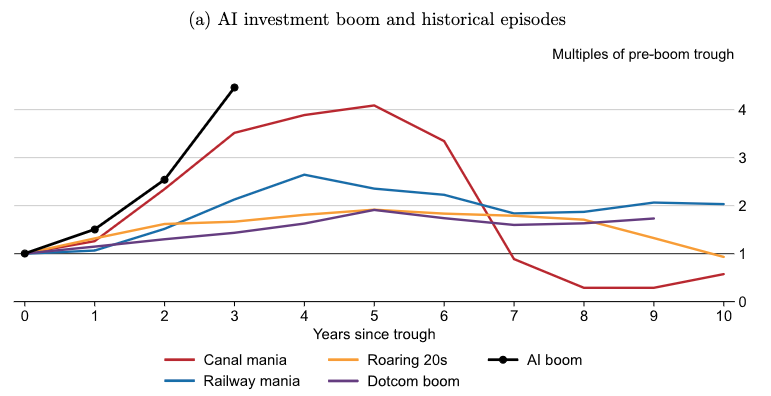
Un nouveau rapport de la banque des banques centrales analyse dans le détail les conséquences potentielles de la course à l’investissement dans l’IA. Il estime que le secteur est déjà en situation de surinvestissement, et que le mouvement en cours pourrait passer d’une « explosion » à un « effondrement » d’autant plus intense qu’il est financé par de multiples leviers financiers.
La « banque des banques centrales » l’avait laissé transparaître dès son rapport annuel. Lors de la publication du document, fin juin, la directrice adjointe de la Banque des règlements internationaux (BRI) Andrea Maechler avait listé auprès de l’AFP quatre points d’attention pour l’économie planétaire : l’inflation provoquée par le conflit au Moyen-Orient et la hausse des cours du pétrole, des plastiques ou encore des engrais, l’ « appétit exubérant pour le risque » des marchés financiers, les niveaux d’endettement élevés des États et… la course aux investissements dans l’intelligence artificielle.
Quelques jours plus tard, l’institution a publié le travail de l’un de ses économistes, Phurichai Rungcharoenkitkul, entièrement dédié à cette course. Sur 56 pages, celui-ci détaille les dynamiques d’investissement dans l’IA et les effets qu’elles pourraient avoir sur la stabilité financière. Et d’exprimer un constat clair : les surinvestissements constatés « exposent le secteur à une baisse des recettes qui pourrait transformer le boom » du secteur « en effondrement ». Et de préciser que « la course à l’engagement précoce par le biais de l’endettement et du financement circulaire augmente le risque d’effondrement ».
En d’autres termes, l’institution s’inquiète ouvertement de voir la course à l’IA dépasser de précédents booms technologiques qui s’étaient déjà, à l’époque, soldés par d’importantes perturbations de marché. Elle alerte sur le fait que les difficultés d’une seule entreprise pourraient « se répercuter sur d’autres par le biais de chaînes d’expositions financières ».
Qu’une innovation technologique produise une vague d’investissements n’a rien de spécifique en soi. L’invention du rail, la multiplication de canaux financés par les États-Unis, même la bulle Internet des années 2000 ont, à des mesures variables, enregistré ce genre d’excitation financière. Le problème, constate néanmoins l’économiste, est qu’elles ont régulièrement enregistré des corrections plus ou moins sévères sur les marchés. Par ailleurs, comparé à « son niveau le plus bas avant le boom, le développement actuel [de l’IA] est en passe de dépasser tous les épisodes précédents en seulement trois ans ».
En s’appuyant sur les bilans des entreprises d’IA et les données publiques disponibles sur les transactions, l’économiste cherche à estimer l’ampleur des investissements réalisés. « La concentration du secteur offre une visibilité inhabituelle, bien qu’incomplète, sur la situation financière des entreprises », relève-t-il, avant d’estimer que les investissements réalisés dans l’industrie représentent « environ 1,5 fois l’optimum social », c’est-à-dire la meilleure répartition possible des actifs pour satisfaire au plus grand nombre. Dans certains cas de figure, ce surinvestissement peut grimper jusqu’à trois fois au-dessus du niveau le plus efficace d’allocation de capital, estime la BRI.
Cette lecture au prisme de l’efficacité économique fait écho à des travaux menés au prisme environnemental. Ainsi d’une récente étude menée par l’analyste Ketan Joshi sur les activités de Google dans le domaine de l’IA : début juillet, ce dernier calculait qu’en quelques années à peine, Google avait multiplié par 1,5 ses dépenses énergétiques pour dégager le même volume de chiffre d’affaires. Une explosion directement liée aux besoins d’infrastructures (des puces jusqu’aux centres de données) de l’IA.
Risque de « récession à l’échelle de l’ensemble de l’économie »
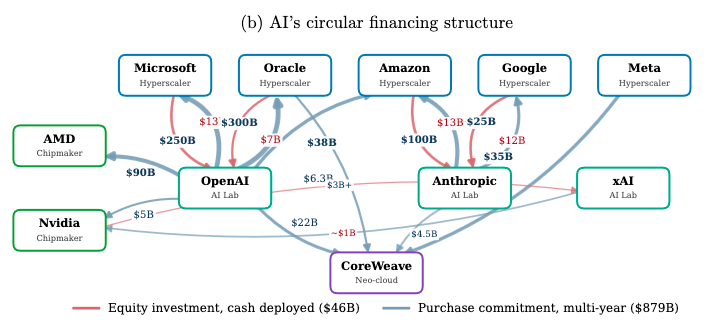
De fait, la concentration du secteur implique que les difficultés touchant l’une des sociétés de l’IA se répercutent à plusieurs niveaux de la chaîne de valeur : elles pourraient s’étendre aux constructeurs de centres de données, aux laboratoires d’IA, aux fabricants de puces ou encore aux fournisseurs de services cloud, pour commencer. D’après la BRI, cette dynamique constitue une vulnérabilité à part entière puisqu’un « choc subi par une société pourrait se propager et devenir systémique ».
L’explosion de l’IA « partage de nombreuses caractéristiques clé » observées dans des booms technologiques historiques, rappelle Phurichai Rungcharoenkitkul : les entrepreneurs investissent lourdement dans la nouvelle technologie dans l’espoir de « gagner » la course, leurs sociétés cherchant à obtenir des effets de levier capitalistique en recourant à de multiples modes de financement, tandis que l’important recours au financement spécialisé (le capital-risque) pourrait aggraver l’ampleur des pertes en cas de ralentissement économique.
Les cinq plus grands hyperscalers devraient allouer plus de mille milliards de dollars à de l’investissement dans l’IA sur la seule année 2026, calculait la BRI dans son rapport annuel (.pdf), un montant tiré à la fois par la surenchère entre concurrents et par la hausse du prix des mémoires. Or, ces montants dépassent largement leurs bénéfices comme leurs flux de trésorerie, ce qui les conduit à se tourner de plus en plus vers l’émission de titres de créance.
En définitive, la différence la plus notable entre la bulle actuelle et les précédentes se situe dans l’ampleur du phénomène actuellement à l’œuvre. Or, plusieurs des précédentes bulles de ce type ont entraîné « des récessions à l’échelle de l’ensemble de l’économie », alerte la BRI. Et d’insister sur le fait que la course actuelle présente des « risques de ralentissement à court terme ».
Le rapport est publié alors qu’aux États-Unis, terre d’origine de la poignée des sociétés les plus engagées dans cette course à l’investissement, la Réserve fédérale a créé un groupe de travail « Productivité et emplois » dédié notamment à étudier les impacts de l’IA générative sur ces domaines. Celui-ci intègre notamment plusieurs leaders du secteur, dont le capital-risqueur Marc Andreessen, l’ancien directeur de Microsoft CoreAI et l’économiste Charles Irving Jones, détaché chez Anthropic. Autant de liens directs avec l’industrie de l’IA qui interrogent sur l’indépendance réelle de la banque centrale des États-Unis.
xAI, maison mère du réseau social X et du moteur d’IA générative Grok, poursuit en justice un homme de Caroline du Sud au motif qu’il aurait utilisé Grok pour créer du contenu représentant des agressions sexuelles sur mineurs (Child sexual abuse material, CSAM). L’homme, Terry Harwood, a été arrêté plus tôt dans l’année pour des faits d’exploitation sexuelle de mineurs.
D’après la plainte de xAI, déposée devant la cour fédérale texane, il aurait violé les conditions d’utilisation des services de la société, rapporte Reuters.
C’est, a priori, la première plainte de ce type déposée par une société éditrice de système d’IA générative contre l’un de ses utilisateurs. C’est aussi un type d’action tout à fait cohérent avec une pratique récurrente d’Elon Musk, patron de xAI. Homme le plus riche de la planète, il est connu pour tenter de régler nombre de ses conflits devant les tribunaux (quelquefois sans succès, comme dans l’affaire qui l’a récemment opposé au PDG d’OpenAI Sam Altman).
Si le profil de l’internaute visé peut expliquer la décision de le poursuivre en justice, la plainte a ceci d’étonnant qu’elle a été déposée alors même qu’Elon Musk a personnellement supervisé le tournant de plus en plus sexualisé des résultats de Grok.
Elle peut néanmoins faire office de démonstration de ses pratiques de modération, alors que la société est sous le coup de multiples enquêtes à travers le monde.
La plainte contient par exemple l’affirmation selon laquelle xAI a suspendu 52 222 comptes et soumis 73 604 alertes au Centre national pour les enfants disparus et exploités (NCMEC) des États-Unis, alertes qui auraient « conduit à (au moins) 244 arrestations ».
La société accuse Terry Harwood d’avoir téléchargé des images non sexuelles d’adultes et d’enfants sur Grok pour générer des deepfakes pornographiques de ces différentes personnes. Elle l’accuse aussi d’avoir produit des images pornographiques non consenties d’adultes.
Depuis un peu plus d’un mois, un réseau social européen a fait son entrée sur le protocole AT, qui sert de colonne vertébrale à Bluesky. Next l’a testé et en a discuté avec l’un de ses architectes.
Le réseau social a 34 jours à l’heure de publier ces lignes. Il comptait 100 000 utilisateurs au bout de 26 jours d’existence. De mon côté, j’ai rejoint la troupe alors que la plateforme fêtait sa troisième semaine d’existence.
Dans l’idée d’européaniser un peu mes réseaux sociaux – et d’écrire une série d’articles qui débute avec celui-ci –, je suis allée un cran plus loin : j’ai déplacé toutes mes données sur Eurosky, la plateforme construite par la Modal Foundation. L’entité, qui gère aussi Mu, vise à fournir au public un compte unique lui permettant d’accéder à une foultitude d’applications reliées par une seule et même infrastructure : le protocole AT.
Si tous ces termes techniques vous collent des frissons d’angoisse, retenez pour le moment qu’un compte Eurosky vous permet d’accéder, depuis l’Europe et sans avoir à vous réinscrire 15 fois, à des services aussi divers que des applications de construction de site, des réseaux sociaux (type Mu), des services de code, de blog, de veille, etc. On vous en dira plus dans un prochain article. D’ici là, vous pouvez vous référer à tout cela en évoquant l’ATmosphere, à laquelle appartient aussi… Bluesky.
Mais revenons à nos mu-tons. Depuis quelques jours, j’observais une partie de la communauté Bluesky discuter de ce nouveau réseau social, Mu. Pourquoi changer encore de plateforme, alors que j’avais déjà dû fuir X, me créer un compte sur Bluesky, un autre sur Mastodon, bref, que je vis désormais dans une (relative) cacophonie de services ? « Il n’y a aucune obligation, répond à Next le vice-président de Modal, Robin Berjon. Vous aurez le même contenu et le même genre de réseau. En revanche, vous y gagnerez un ensemble de fonctionnalités supplémentaires », à commencer par le très inutile mais très satisfaisant petit chat qui court depuis deux semaines en bas de mon écran.
Là, il court partout. Mais quand il sera fatigué, il fera une sieste. / Mu, capture d’écran
L’interopérabilité en action
Surtout, le réseau est construit de telle sorte qu’il est possible de tester Mu sans abandonner son compte Bluesky. Vous voyez l’interopérabilité, ce terme barbare que professent certains défenseurs du numérique (comme la Quadrature du Net) depuis des années ? Très concrètement, c’est cela qu’elle permet : avoir un compte utilisateur quelque part, s’en servir pour accéder à une multitude de services construits par des gens différents. Ça permet aussi d’accéder au même contenu, produit par la même foule de personnes auxquelles, personnellement, je me suis abonnée depuis mon arrivée sur Bluesky, depuis l’interface de mon choix.
En l’occurrence, depuis un demi-mois, j’ai abandonné la plateforme grise et bleue de Bluesky pour adopter celle marron et rose (vous pouvez tout à fait modifier les couleurs dans les paramètres) de Mu. Avec un poticha en plus.
Si j’insiste sur le chat, c’est à la fois pour la blague et parce que ç’a fait l’effet d’un excellent coup marketing à l’échelle de la rédaction de Next. J’ai vu des gens en parler depuis Bluesky. Je me suis dit qu’il fallait que je teste. J’ai créé mon compte, j’ai été dans Paramètres / Companion (oui, de petits anglicismes subsistent) et voir ce petit être de pixel se promener sur mon écran m’a rendue excessivement heureuse. J’en ai parlé sur les réseaux (alors que j’aurais dû accorder toute mon attention à une réunion de rédaction, oups). Mes collègues l’ont vu : en moins de trois minutes, une bonne partie d’entre eux étaient en train de tester pour avoir, eux aussi, la satisfaction de voir un petit-chat-mignon sur leur écran.
Des vérificateurs de confiance par communauté
Plus sérieusement, cela dit, Mu propose quelques autres fonctionnalités différentes de celles de Bluesky. Ainsi de l’onglet « Actualités », accessible à gauche, sous la page d’accueil. « Pour le moment il est très basique, il ne prend en compte que quelques centres d’intérêt et une zone géographique, mais on travaille sur quelque chose de plus avancé, explique Robin Berjon. Quelque chose qui ressemble à un mélange entre les flux sociaux des journaux et le flux RSS d’un journal, en faisant apparaître les comptes des journalistes sur le côté, les commentaires des gens… »
Un peu plus développé, Mu recourt aussi à un système de vérificateur de confiance. Ici, pas de paiement ou de nombre d’abonnés à dépasser pour obtenir le coche des utilisateurs vérifiés. Au contraire, il faut plutôt compter sur les travaux de communautés spécifiques pour faire émerger une série de comptes vérifiés.
« L’idée, à terme, c’est d’avoir un Wikipedia de la vérification. » Sur Facebook ou Twitter, rappelle Robin Berjon, de premiers programmes de vérification ont émergé, sur lesquels les sociétés ont fait des efforts « dans un premier temps. Cela devait notamment servir à protéger contre les bots. Et puis ils se sont rendu compte que moins de bots, cela impliquait moins de vues, donc des statistiques publicitaires plus basses. » Sans parler du tournant très pécuniaire pris par X, sous l’impulsion d’Elon Musk. En déléguant à des communautés nationales, d’intérêts, de spécialités, le but est « d’empêcher que la vérification ne reste aux mains d’une seule société, qui puisse changer d’avis ».
Cliquer sur le coche de vérification d’un compte permet d’afficher les entités qui l’ont vérifié. / Mu, capture d’écran
Et de souligner que Medsky, une communauté dédiée à la santé, est par exemple très active dans la validation de « comptes crédibles de la communauté médicale ». En l’état, le système est « encore un peu trop centralisé », note cela dit Robin Berjon : rien n’empêche le compte La France sur Bluesky/Eurosky, qui a vérifié mon propre compte, de changer de politique du jour au lendemain, donc de minimiser la crédibilité de sa vérification. « Des communautés comme ATProto Belgique essaient de déporter cela, en créant des processus documentés, en fournissant une traçabilité de l’information qui permet à l’utilisateur de vérifier comment les décisions sont prises. » Une logique aussi ouverte, encore une fois, que celle qui anime Wikipedia.
Parmi les nouvelles fonctionnalités à venir, Robin Berjon cite la possibilité d’intégrer « des mini-applications, des mini-fonctionnalités, des petits jeux » directement dans Mu. Ou encore un chantier relatif à la vérification de l’âge. « On peut être partagés, considérer que ce type de décision politique n’est pas dingue. Mais comme ça semble arriver, autant le faire le moins mal possible. » En d’autres termes, les équipes de la Fondation Modal devraient réfléchir à un système aussi « respectueux de la vie privée et peu intrusif » que possible. De ces gros chantiers aux petits outils comme le chiffrage automatique du nombre de messages dans un thread, la plateforme promet sur son site web« des nouvelles choses toutes les semaines ».
Un réseau social (très) jeune
Au bout de quelques semaines d’usage, quelles critiques pourrais-je faire à cette version européenne de Bluesky ? Comme j’ai été jusqu’au bout de la démarche, c’est-à-dire que je ne me suis pas contentée de recourir à mon compte utilisateur Bluesky pour tester Mu, mais que j’ai déplacé mes données chez Eurosky, je tombe quelquefois sur un message d’erreur lorsqu’un collègue m’envoie un lien vers un message Bluesky.
À moi de déduire des éléments que j’y lis (je pars généralement du nom du profil) pour aller rechercher le message depuis mon compte Mu. Ce genre de désagrément « est voué à se résorber » au gré des travaux sur Mu, indique Robin Berjon. Ce matin, j’ai aussi vécu l’étrange expérience de voir ma photo de profil remplacée par la sienne – j’avais visiblement traîné un peu trop longtemps sur son profil le temps d’écrire cet article. Bref, Mu est jeune, et encore un peu brouillon par endroits.
J’ai changé / Mu, Capture d’écran
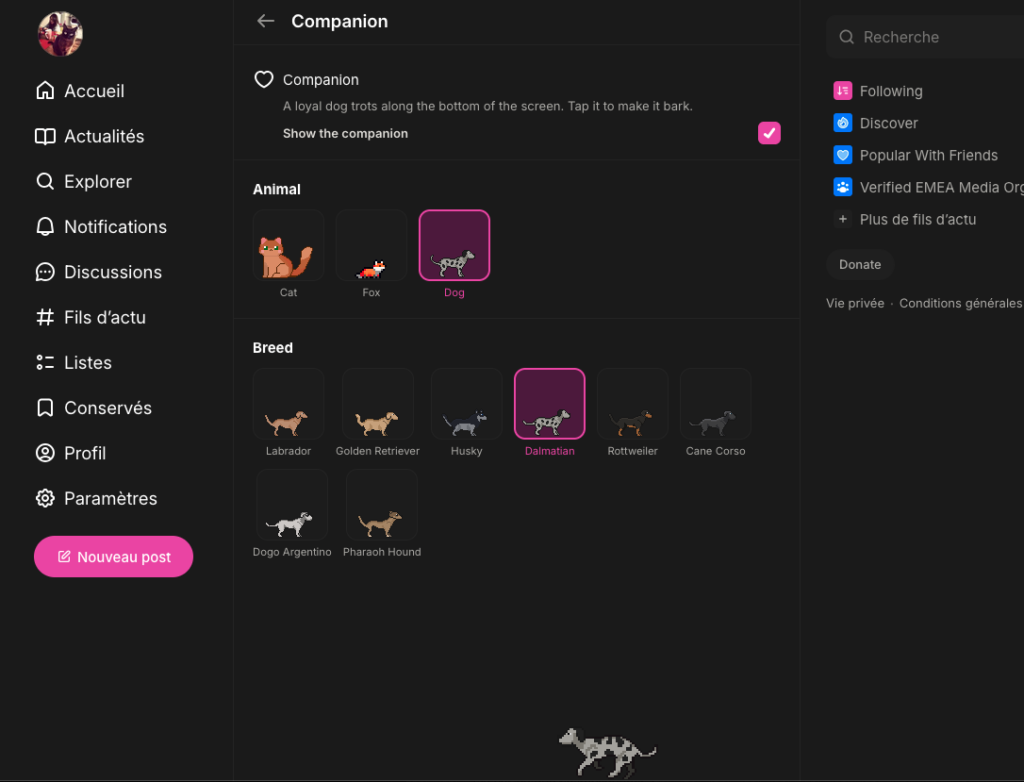
Mais ces petits désagréments n’empêcheront probablement pas les geeks de tous poils d’observer avec bienveillance l’évolution rapide de la plateforme. Y compris sur la question des petits chats. Puisqu’évidemment, il a fallu que des amateurs de chiens (ces gros jaloux) s’en mêlent. Depuis quelques jours, la palette des animaux compagnons s’est donc élargie. Jugez-en par vous-même :
Paramétrage de l’animal compagnon sur Mu / Capture d’écran
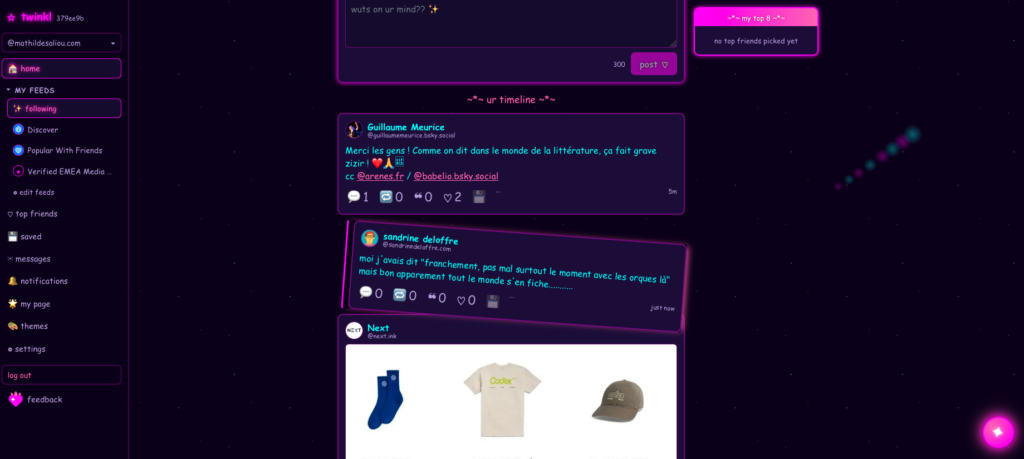
Si vous préférez les paillettes, Mu a déjà un concurrent très très très Y2K (années 2000, pour nos vénérables lecteurs qui seraient perdus) : twinkl social. Je vous laisse sur une capture d’écran, mais je vous en parlerai un peu plus dans un prochain article.
Des paillettes et du glitter, svp / Capture d’écran du fil principal sur Twinkl.social
Dans son rapport sur la place des femmes dans le jeu vidéo, la délégation sénatoriale aux droits des femmes relève que si les femmes sont aussi largement joueuses que les hommes, leur accession à l’industrie du jeu vidéo ou au monde de l’e-sport reste, lui, bien plus complexe.
Plus de 200 milliards de dollars, tel est le volume que représente l’industrie du jeu vidéo dans le monde. À l’échelle du globe comme à celle de l’Hexagone, elle se place à la première place des industries culturelles. En France, relève la délégation sénatoriale aux droits des femmes, le jeu vidéo représente 1 000 sociétés actives, plus de 10 000 emplois directs (dont 57 % travaillent en région parisienne) et six milliards d’euros de chiffre d’affaires.
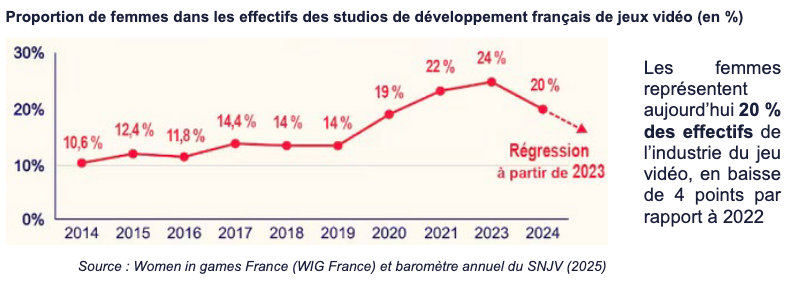
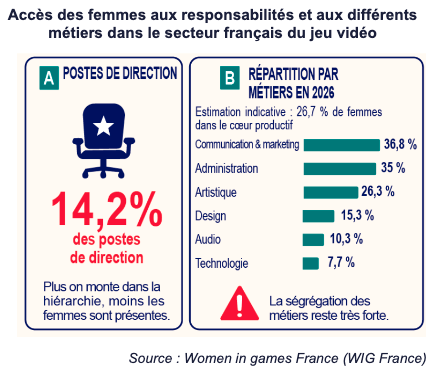
Si le loisir a bénéficié d’une féminisation massive de ses publics – aujourd’hui, 51 % des joueurs français sont des joueuses, proportion qui grimpe à 55 % au sein de la génération Z -, celle de l’industrie est encore loin d’être effectuée. Seulement 20 % des effectifs totaux du jeu vidéo sont des femmes, « une proportion qui tombe à 7,7 % dans les métiers techniques et à 14 % dans les postes de direction », indique la délégation sénatoriale des droits des femmes.
Poursuivant des travaux engagés sur la place des filles et des femmes dans les sciences et les techniques, cette dernière a publié un rapport intitulé « Jeux vidéo : de la Game Boy aux filles dans le game, l’égalité en cours de chargement ». Fruit de 8 mois de travail et de l’audition de plus de 90 spécialistes du domaine, le document constate aussi, dès ses premières pages, que les femmes font partie des premières victimes de la crise économique post-pandémie qui s’est abattue sur l’industrie.
Rapport sénatorial « Jeux vidéo : de la Game Boy aux filles dans le game, l’égalité en cours de chargement »
Dans le jeu comme dans l’industrie, des pratiques genrées
Les femmes présentes dans l’industrie des jeux vidéo n’y sont pas de manière uniforme. Elle sont très peu représentées dans le game design, c’est-à-dire dans la création des « règles et principes du jeu ». De même qu’ailleurs dans l’industrie technologique, elles sont particulièrement peu nombreuses dans les postes de programmation.
Rapport sénatorial « Jeux vidéo : de la Game Boy aux filles dans le game, l’égalité en cours de chargement »
La première cause de ce déséquilibre se trouve du côté de la formation initiale. Comme pour le reste des filières technologiques, les femmes y sont déjà moins nombreuses (un quart des effectifs des formations spécialisées dans le jeu vidéo), mais la déperdition augmente avec le temps. Elles ne sont ainsi plus que 20 % dans les studios, soit 6 points de moins qu’en formation. Par ailleurs, elles sortent de leur carrière plus tôt que les hommes, généralement autour de 35 ans.
« Ce phénomène du "tuyau percé" est le résultat d’un environnement de travail encore peu favorable aux femmes, à de moindres opportunités d’avancement ou d’accès à des postes stratégiques au sein de l’entreprise, enfin à la perpétuation, dans certains environnements de travail, d’un climat professionnel toxique voire de situation de violences et harcèlement sexistes et sexuels au travail. » Le constat rejoint en tous points celui formulé en 2025 par la spécialiste des enjeux d’inclusion dans le numérique Caroline Ramade auprès de Next.
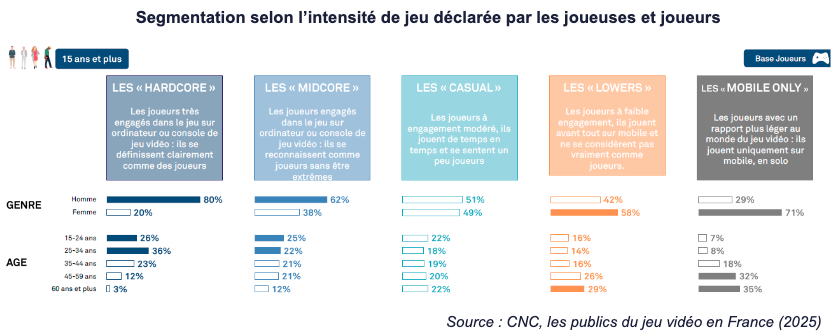
Malgré ces éléments, en tant que public, les femmes sont clairement joueuses. 69 % d’entre elles déclaraient jouer aux jeux vidéo en 2024, d’après le Syndicat des éditeurs de logiciels de loisirs (Sell). Leurs pratiques diffèrent néanmoins en partie de celle des hommes. Elles ne représentent que 20 % des joueurs dits « hardcore » et 58 % des joueurs dit « lowers », c’est-à-dire jouant « avant tout sur mobile » et qui « ne se considèrent pas vraiment comme joueurs ». Elles représentent aussi 71 % des joueurs qui n’utilisent que leur mobile.
Rapport sénatorial « Jeux vidéo : de la Game Boy aux filles dans le game, l’égalité en cours de chargement »
Des imaginaires « marqués par des biais sexistes » au jeu vidéo « outil d’égalité » ?
Historiquement, le jeu vidéo s’est largement construit sur un imaginaire sexiste, qui se retrouve aussi bien dans les publicités des années 1980 (dans lesquelles les protagonistes tenant les manettes sont généralement des jeunes garçons blancs) que dans les scénarii de jeu. Ainsi de la figure de « demoiselle en détresse », très bien représentée par la princesse Peach dans de nombreux jeux de la franchise Mario, ou des représentations sexistes et irréalistes de femmes, quand bien même elles seraient protagonistes principales, à l’instar de Lara Croft dans le premier Tomb Raider.
Il reste 51% de l'article à découvrir. Vous devez être abonné•e pour lire la suite de cet article. Déjà abonné•e ? Générez une clé RSS dans votre profil.
D’après les calculs de Meta, les plaintes déposées par la Californie, le Colorado, le Kentucky et le New Jersey pourraient l’exposer à 1 400 milliards de dollars d’amende si l’entreprise est déclarée coupable d’avoir conçu Facebook et Instagram de manière à rendre les plus jeunes utilisateurs dépendants de leur usage.
L’entreprise a soumis ce chiffre dans un document déposé devant la Justice ce lundi et relayé par Reuters. Il est très proche de sa capitalisation actuelle, qui s’élève à 1 500 milliards de dollars.
« Une telle sanction n’a pas de comparaison dans l’histoire de la protection des consommateurs », indique la société, qui estime que les plaintes manquent de fondement.
Illustration : Flock
La société est poursuivie devant un tribunal californien pour avoir « priorisé ses profits sur la sécurité des enfants, alimentant la crise de la santé mentale que nous observons toucher toute une génération de jeunes États-uniens », selon l’équipe du procureur Rob Bonta.
Lors d’une audience de juin, des représentants des États plaignants ont déclaré calculer le montant qu’ils allaient réclamer en multipliant le nombre de violations par les montants des amendes fixées par chaque loi étatique.
Le nombre de violations, lui, serait égal à une estimation du nombre d’adolescents et de jeunes utilisateurs affectés par les actes de Meta.
Au mois d’août, la juge Yvonne Gonzales Rogers se prononcera sur les plaintes des quatre États en question, ainsi que sur celles des vingt-neuf États qui poursuivent l’entreprise essentiellement au motif que celle-ci aurait collecté des données de mineurs sans consentement parental adéquat.
Meta nie les accusations et déclare que les procureurs n’ont pas d’éléments permettant de démontrer une « addiction aux réseaux sociaux », dans la mesure où celle-ci n’est pas une maladie psychiatrique établie.
Très critiqué pour les enjeux de vie privée posés par son nouveau modèle Muse Image, Meta a décidé de suspendre l’outil permettant de générer des images en utilisant des photos d’autres utilisateurs Instagram.
L’expérience aura fait long feu. Déployée la semaine dernière, la fonction du modèle Muse Image permettant d’exploiter des images d’autres utilisateurs d’Instagram a été suspendue par Meta. En d’autres termes, les utilisateurs du réseau social peuvent toujours générer des images avec ce nouvel outil, mais ils n’ont plus la possibilité d’y faire figurer un autre utilisateur. En cause : de multiples critiques sur la manière dont le réseau social encourageait les internautes à utiliser les images des autres utilisatrices et utilisateurs pour générer de nouveaux contenus à l’aide de l’intelligence artificielle.
Le 8 juillet, Meta a dévoilé un modèle de génération d’image intégrée à son chatbot Meta AI et déployé des fonctionnalités de cet outil dans Instagram, permettant aux usagers de créer de nouvelles images et de retoucher ou de fictionnaliser des images existantes. Les possibilités vont de l’évolution d’une photo en lui appliquant un filtre jusqu’à la transformation complète des éléments représentés à l’image (pour leur donner l’aspect de pâte à modeler, par exemple). Elle permettait aussi de représenter d’autres internautes, grâce à une simple mention de leur handle Instagram.
« Incompréhension totale de l’opinion publique » envers ce type d’outils
Le 10 juillet, l’entreprise est revenue sur son projet. Dès la publication de Muse Image, Meta s’est retrouvée sous un feu de critiques nourries sur le choix de déployer les fonctionnalités de recours à son modèle sur le modèle de l’opt-out. De fait, les utilisateurs se retrouvaient automatiquement embarqués dans le système, et ne pouvaient s’y opposer qu’en se rendant dans les paramètres de leurs comptes, à l’onglet « Partages et réutilisations ». Des célébrités et des syndicats hollywoodiens se sont même emparés du sujet.
Ainsi de Hannah Einbinder, révélée par la série Hacks, ou du syndicat des acteurs états-uniens SAG-AFTRA, qui ont appelé leurs audiences respectives à refuser ce réusage de leurs images et publications Instagram. Pour SAG-AFTRA, « toute modalité autre qu’un choix [opt-in, ndlr] clair et évident pour ce type d’utilisation des images des utilisateurs d’Instagram est inacceptable, et une incompréhension totale de l’opinion publique vis-à-vis des dangers évidents que ce genre d’utilisation provoque ».
De fait, difficile de ne pas penser à la vague de deepfakes pornographiques qui a enseveli X lorsque des fonctionnalités similaires y ont été rendues disponibles à l’hiver 2025. Difficile, aussi, de ne pas voir les problématiques de droits d’auteurs que ce type d’outil amplifie, dans la mesure où Instagram est très largement utilisé par les artistes graphiques pour faire connaître une partie de leur travail.
La fonctionnalité n’a « pas répondu aux attentes »
« Notre souhait était de fournir un outil créatif utile et de donner aux gens le contrôle sur la possibilité de laisser leur contenu public être référencé de cette manière », a déclaré Meta dans un communiqué. Outre le contenu publié par les internautes, la photo de profil faisait aussi partie des contenus susceptibles d’être réutilisés si l’usager laissait Meta AI libre d’accéder à ses publications.
« Nous avons entendu les commentaires indiquant que cette fonctionnalité n’avait pas répondu aux attentes », a continué l’entreprise. À ce titre, indique-t-elle, elle n’est plus disponible. Ce 13 juillet, la formulation des encarts qui indiquaient encore vendredi « Autoriser la réutilisation de votre contenu sur Instagram et avec les fonctionnalités IA de Meta » déclare désormais seulement « Autoriser la réutilisation de votre contenu ». Le texte explicatif mentionnant les fonctionnalités d’IA a été modifié, supprimant cette évocation.
Seule la partie dédiée à la réutilisation des reels (les vidéos verticales) souligne qu’en cas de consentement de l’internaute, « tout ou partie de votre audio d’origine » peut être réutilisé « sur les applications et le site Web de Meta AI ».
Avant Meta, OpenAI avait déployé des fonctionnalités similaires avec son modèle Sora 2, aux États-Unis. Là encore, les outils avaient été déployés sur le mode de l’opt-out. Et dans ce cas aussi, l’entreprise avaient été suffisamment critiquée pour décider de modifier sa politique. Elle a finalement coupé l’accès à Sora en mars 2026.
C’est sur marinelepen.com que la cheffe du Rassemblement National a lancé sa campagne pour la Présidentielle 2027, juste après avoir été reconnue coupable de détournement de fonds publics (elle se pourvoit en cassation).
Pourquoi marinelepen.com et pas .fr, pour un rendez-vous national de cette importance ? Parce que marinelepen.fr n’était pas disponible : d’après le Bulletin Quotidien, le nom de domaine a été acheté en 2021 par une entreprise belge spécialiste du référencement, Score Worldwide.
Celle-ci a récupéré le nom de domaine avant la dernière campagne présidentielle de Marine Le Pen, en 2022, pour une seule raison : son nom était de plus en plus recherché en ligne. Auprès de Libération, un cadre de l’entreprise indique même que l’achat a été effectué « sans savoir qu’elle était une femme politique française ».
Pendant un moment, la page du site web a présenté un portrait de l’élue et l’indication que le nom de domaine était à vendre. Actuellement, il annonce simplement, en français et en anglais : « Ce domaine de marketing est à vendre : toute offre supérieure à 25 000 € HT sera prise en considération. Veuillez envoyer votre proposition avant le 14 juillet 2026 à l’adresse servicedesk@score-worldwide.com. » La date butoir n’est qu’« indicative », précise le responsable de l’entreprise.
Capture d’écran du site marinelepen.fr le 13 juillet 2026
Le message est assorti d’une publicité pour des cliniques privées de Belgique et du Nord de la France supposées aider ses clients à « prolonger [leur] espérance de vie grâce à notre stratégie de longévité et à nos traitements urologiques ».
S’il a utilisé le nom de domaine marinelepen.fr un temps, le Rassemblement National a visiblement oublié de renouveler son droit annuel d’usage du nom de domaine, ce qui a permis à Score Worldwide de s’en emparer.
Alors que l’entreprise avait demandé au parti s’il souhaitait en récupérer l’accès (contre finances), le parti vient de s’adjoindre les services du cabinet Mark pour tenter d’en récupérer l’accès gratuitement. Auprès de Libération, Score Worldwide déclare ne pas envisager de céder le nom de domaine sans contrepartie.
Dans un rapport de 160 pages sur les zones grises de l’information, trois sénatrices et sénateurs appellent à protéger et financer la pluralité de la presse et à responsabiliser les géants numériques.
Sommes-nous prémunis contre une ingérence informationnelle venue de l’intérieur du pays ? À cette question, la réponse du sénateur Laurent Lafon (Union Centriste), président de la commission sénatoriale de la culture, de l’éducation, de la communication et du sport est très claire : « Non ». La France a beau être bien protégée par une entité comme VIGINUM sur tout ce qui a trait aux ingérences numériques étrangères, elle présente une « vulnérabilité » sur ce qui relève des manipulations perpétrées depuis l’intérieur du pays, que celle-ci soit le fait d’une personnalité, d’un parti politique, ou de toute autre entité trouvant un intérêt politique ou financier à manipuler les espaces numériques où circule l’information.
Tel est l’un des principaux constats dressés par la commission à l’occasion de la publication, ce 9 juillet, de son rapport sur « Les zones grises de l’information ». Aux côtés des co-rapporteures Agnès Evren (Les Républicains) et Sylvie Robert (Socialistes), celui-ci décrit un environnement dans lequel non seulement le secteur de la presse est singulièrement abîmé, mais où la circulation de l’information de qualité est compliquée par l’architecture des plateformes numériques les plus utilisées par le public et par la production à grande ampleur de contenus de mal- ou de désinformation.
« Notre première préoccupation, c’est de protéger nos échéances électorales », indique Laurent Lafon. Les trois sénateurs déposeront à la fin de l’été une proposition de loi qui intégrera l’essentiel des 56 recommandations formulées dans leur travail. En tête de ces dernières : celle de créer un Observatoire de la désinformation interne, indépendant, qui effectue l’équivalent des missions de VIGINUM à l’intérieur du pays. Celui-ci serait « chargé d’inciter les plateformes à modifier leurs algorithmes ou à invisibiliser un utilisateur fautif en cas de menace grave pour la qualité de l’information à l’approche des élections ». Il pourrait aussi être en mesure de saisir la Commission nationale de contrôle de la campagne électorale en vue de l’élection présidentielle (CNCCEP) ou l’Autorité de régulation de la communication audiovisuelle et numérique (Arcom) en cas, notamment, « d’atteinte à l’égalité entre les candidats ».
Presse à la peine et évolution des pratiques d’information
Mené pendant six mois, tirant les leçons des différentes opérations d’ingérence informationnelle constatées en France et en Europe, notamment autour de rendez-vous électoraux, le travail des sénateurs aboutit à la nécessité d’agir sur plusieurs fronts.
Il reste 76% de l'article à découvrir. Vous devez être abonné•e pour lire la suite de cet article. Déjà abonné•e ? Générez une clé RSS dans votre profil.
Pour une dizaine de millions d’euros par an, le programme Tremplin de la Mission French Tech œuvrait depuis cinq ans à la promotion de la diversité dans le secteur numérique.
D’après les informations de La Tribune, il vient d’être supprimé pour raisons budgétaires. Il devrait être remplacé par un nouveau programme nommé, de manière provisoire, Nova.
Le cursus avait été lancé en 2019 par le secrétaire d’État au Numérique de l’époque, Mounir Mahjoubi. Celui-ci soulignait alors la surreprésentation d’ « hommes qui vivent en centre-ville, issus de famille CSP+ » au sein de la French Tech, une population qui ne « ressemblait pas à (…) la France ».
En France, en 2025, seulement 9 % des start-ups étudiées dans le baromètre du BCG pour l’association SISTA avaient été fondées par des femmes. Ces sociétés avaient par ailleurs levé 1 % du total des fonds réunis sur l’année auprès du capital-risque, subissant un cumul de discriminations régulièrement étudiées. Les équipes mixtes, qui comptent pour 10 % du total des start-ups, avaient en revanche levé 18 % de l’enveloppe globale.
Dans l’IA, le déséquilibre est plus grand, avec seulement 3% de startups créées par des équipes féminines, et 19 % par des équipes mixtes.
Le programme Tremplin permettait à 500 entrepreneurs issus des minorités de genre, culturelle, ou de zones rurales d’accéder à un an d’incubation, de formation aux codes de l’entrepreneuriat et à une aide susceptible de grimper jusqu’à 30 000 euros.
Moins coûteux, le programme Nova devrait se concentrer sur les scale-up, c’est-à-dire les sociétés ayant validé leur modèle économique, et qui cherchent à étendre leur activité.
Dans le secteur de l’information (médias, numériques), l’adoption forte de l’IA s’accompagne d’une augmentation des effectifs sur 24 mois, relève une nouvelle étude. Des résultats qui viennent ajouter de la complexité (ou de la nuance ?) dans les débats sur les effets de ce type de technologies sur le travail.
L’intelligence artificielle cause-t-elle la suppression de milliers d’emplois ? Permet-elle la création de milliers d’autres ? Se contente-t-elle de modifier la qualité des emplois préexistants ? Depuis l’introduction des modèles génératifs, les travaux s’accumulent, qui tentent de détailler les effets concrets de la technologie sur le travail.
Une nouvelle étude menée par Ramp et Revelio Labs vient dessiner une image un peu moins négative que l’essentiel de celles qui la précèdent. La première suit les dépenses des entreprises en matière d’IA, et la seconde s’intéresse à l’évolution des effectifs des sociétés. En cumulant leurs données relatives à 22 000 entreprises états-uniennes, elles constatent que celles qui ont investi le plus dans l’IA enregistrent une croissance plus forte de leur nombre d’employés que les autres.
La tendance s’observe jusque du côté des emplois juniors. Elle est, cela dit, « quasiment exclusivement liée » aux sociétés dont l’adoption d’IA est dite de « haute intensité ».
Tous les types d’emploi, mais surtout des sociétés technologiques
Ce type d’entreprise est à envisager comme dépensant une moyenne de 30 $ par employé et par mois en IA sur ses trois premiers mois d’activité. En moyenne, ces sociétés ont enregistré en deux ans une croissance de 10,2 % de leur effectif global, et de 12 % de leurs effectifs à des postes juniors. Les premiers effets en termes de croissance émergent « environ 6 à 12 mois après l’adoption, probablement après que les entreprises mettent en place de bonnes pratiques, intègrent les IA dans les outils de travail et se retrouvent en capacité de faire de nouveaux investissements et de recruter des équipes », écrivent les auteurs de l’étude.
En termes métiers, ces « adopteurs de haute intensité » font évoluer positivement leurs effectifs dans toutes sortes d’emplois, y compris certains très exposés à l’IA. Ainsi des métiers d’ingénierie, de vente, de service client ou de finance. Les sociétés qui investissent moins dans ces technologies n’enregistrent pas de variation évidente de leurs effectifs.
Est-ce à dire que l’IA explique directement l’augmentation constatée des effectifs ? L’histoire n’est pas si simple : d’après les auteurs de l’étude, le profil des sociétés qui tombent dans la catégorie « adopteurs de haute-intensité » est lui-même relativement spécifique. De manière générale, les entreprises qui recourent à l’IA sont « plus grandes, plus techniques et en croissance plus rapide » avant même de s’être tournées vers ces technologies.
Ce sont globalement des entreprises qui paient des salaires plus hauts que dans le reste du panel étudié, et qui sont plus souvent « soutenues par du capital-risque ». Elles sont par ailleurs plus souvent actives dans des domaines proches du monde technologique (le recours à l’IA est nettement moins fort dans des domaines comme la construction, la santé, l’art et le divertissement ou l’hôtellerie et la restauration). Dans la mesure où ce type d’entreprises croit généralement bien plus rapidement que les autres grâce à leur forme de financement, note TechCrunch, cela complique la capacité à établir si c’est bien l’IA qui conduit l’augmentation des embauches, ou l’activité générale.
Les auteurs constatent par ailleurs que la présence d’ingénieurs joue directement sur l’adoption : elle est « beaucoup plus courante lorsqu’une entreprise a des équipes d’ingénierie ». Les sociétés de l’industrie de l’information (médias, fournisseurs logiciels, etc.) sont celles qui démontrent le plus fort lien entre adoption d’IA et augmentation à moyen terme de l’emploi.
Autre élément notable : les données de Ramp et Revelio Labs n’illustrent pas d’effet négatif de l’IA sur l’emploi (au sens où son adoption aurait expressément conduit à la réduction des forces des sociétés concernées). En cela, elles tendent à confirmer les éléments établis par Oxford Economics en janvier, selon lesquels de nombreuses sociétés exagéraient purement les effets des technologies sur leur productivité.
Un débat qui reste ouvert
Au-delà de la question du type de sociétés et de leur secteur d’activité, comment comprendre ces résultats, si différents des multiples études bien plus négatives sur les effets de l’IA sur l’emploi, et qui inquiètent les Français ? Les pistes sont multiples.
L’explication peut se trouver du côté du recul croissant qu’il est possible d’obtenir sur les impacts de cette technologie, d’une part. Elle peut aussi se chercher du côté des effets d’annonces, dans lesquels des sociétés indiquent remplacer des employés par des nouvelles technologies pour transformer une mauvaise nouvelle (l’entreprise va trop mal pour maintenir ses effectifs) en une d’apparence positive (l’entreprise est innovante).
Elle peut aussi s’expliquer par le fait que cette étude s’inscrit dans une somme plus large de travaux, qui ne permettront de dégager une image claire des effets de l’IA sur l’emploi qu’au bout d’une durée bien plus longue que trois ans. Et contrairement à d’autres travaux, elle prend le parti d’adopter une approche macro. Cela signifie qu’elle ne donne aucune précision sur la qualité des emplois créés, et sur la mesure dans laquelle l’IA les a modifiés.
Dans un rapport dédié aux masculinismes, la délégation des droits des femmes du Sénat appelle à renforcer le contrôle sur les plateformes dont les modèles économiques et les outils de monétisation de contenus participent directement à alimenter la violence de genre.
Fin juin, la délégation des droits des femmes du Sénat publiait « Mascus : la nouvelle offensive contre les femmes », un rapport d’information sur la menace masculiniste. Fruit de l’audition d’une centaine de personnes, et de l’analyse de multiples contenus disponibles en ligne, le travail vise à mettre en perspective cette menace spécifique, croissante en France autant qu’à l’étranger, et qui s’appuie sur la haine des femmes. Ces mouvements « représentent un risque réel pour notre démocratie et notre cohésion sociale », indique le document. À ce titre, ils constituent un « enjeu majeur de politique publique », qui nécessite un « réveil des consciences ».
Concrètement, constatent les sénatrices Béatrice Gosselin (LR), Olivia Richard (Union centriste) et Laurence Rossignol (PS), coautrices du rapport, la banalisation des idées masculinistes s’appuie sur deux pieds. Une première idée considère que l’égalité femmes-hommes serait déjà une réalité, au mépris des faits relatifs aux violences conjugales, aux violences sexuelles, à l’égalité salariale, à l’accès aux postes de pouvoir dans l’économie, la politique ou ailleurs. Une deuxième affirme que les féministes ne cherchent qu’à nuire aux hommes. Et ces idées sont relativement diffuses au sein de la société.
En conclusion de son travail, la délégation des droits des femmes formule 24 recommandations dont une série consiste à « assainir l’espace numérique », alors qu’une étude de 2024 constatait qu’il fallait 26 minutes à un compte tout juste créé sur TikTok ou YouTube pour se voir proposer des contenus misogynes. À ces fins, les sénatrices soutiennent aussi bien l’interdiction d’accès aux principaux réseaux sociaux aux moins de 15 ans que des travaux sur les modèles économiques des plateformes et réseaux sociaux. Elles s’intéressent aussi au modèle économique des influenceurs masculinistes eux-mêmes, préconisant de « démonétiser les contenus sexistes, misogynes et masculinistes », afin de réduire l’intérêt pécunier à la diffusion de ce type de publications.
Des stéréotypes persistants, jusque dans les institutions
Auditionnée par la délégation des droits des femmes, la chercheuse et autrice de La Terreur masculiniste (éditions du Détour, 2024) Stéphanie Lamy salue l’appel des sénatrices à améliorer la formation des institutions – en particulier des services d’enquête et du milieu judiciaire – sur la variété des mouvements à l’œuvre pour promouvoir une suprématie masculine.
Il reste 83% de l'article à découvrir. Vous devez être abonné•e pour lire la suite de cet article. Déjà abonné•e ? Générez une clé RSS dans votre profil.
Dans un rapport préliminaire, des scientifiques commissionnés par l’ONU estiment que la rapidité des progrès de l’IA pourrait empêcher les États de la gouverner correctement. L’institution appelle ses membres à lancer une coopération internationale sur le sujet.
Une semaine à peine après que le secrétaire général de l’Organisation des Nations Unies (ONU), António Guterres, a appelé l’industrie de l’IA à « dire la vérité » sur ses impacts environnementaux, l’institution en remet une couche. Dans un rapport préliminaire publié ce 1er juillet, le Groupe scientifique international indépendant des Nations Unies sur l’intelligence artificielle alerte sur le fait que les « capacités de l’IA progressent désormais plus rapidement que la science et les gouvernements ne sont capables de les comprendre et de les encadrer ».
L’enjeu est d’autant plus important que « plus l’intelligence artificielle progresse sans règles communes, moins les gouvernements et les peuples auront leur mot à dire sur son devenir », a déclaré António Guterres. Le document évoque une rupture plus forte que l’arrivée de modèles génératifs comme ChatGPT dans les mondes économiques et numériques. Il alerte en particulier sur l’émergence d’« agents » capables, de manière relativement autonome, de naviguer en ligne, écrire du code, lancer des actions sur des logiciels, etc. Et souligne qu’« aucune garantie scientifique » ne permet d’en assurer le contrôle à long terme.
Un panel de scientifiques diversifié
Parmi les auteurs de ce document figurent des scientifiques connus de l’industrie de l’IA et reconnus pour leurs projets d’ « alignement » (Yoshua Bengio, lauréat du prix-Turing en 2018, Joëlle Barral, directrice de recherche chez Google DeepMind) ou leur implication en matière de défense de l’information (Maria Ressa, cofondatrice de Rappler et prix Nobel de la paix en 2021). Avec des spécialistes venus du Nigeria (Rita Orji), du Brésil (Teresa Ludermir), d’Inde (Balaraman Ravindran), du Pakistan (Bilal Mateen) ou d’Égypte (Mennetallah El-Assady), parmi d’autres nations, il constitue surtout un travail collectif riche d’une bien plus grande diversité que l’essentiel de la littérature sur les enjeux relatifs à l’IA. À l’échelle internationale, cette dernière est en effet largement dominée par des travaux venus des États-Unis, et dans une moindre mesure d’Europe et de Chine.
Collectivement, les auteurs du rapport saluent certains bénéfices apportés par l’intelligence artificielle, comprise comme « des systèmes qui perçoivent, apprennent et agissent », qui « infèrent à partir de données d’entrée comment générer des données de sortie », parmi lesquelles « des prédictions, du contenu, des recommandations, des actions ou des décisions, avec divers degrés d’autonomie et d’adaptabilité ». Parmi ces intérêts : des « applications utiles dans les sciences, la santé, l’agriculture, l’accessibilité, le travail de la connaissance et les technologies de l’information, y compris pour le développement de l’IA elle-même ». En exemple, ils citent le modèle de Google Deepmind AlphaFold, capable de prédire la structure des protéines à partir de leur séquence en acides aminés.
Le rapport précise par ailleurs qu’il se concentre sur les « modèles de fondation », compris comme des systèmes généralistes capables de réaliser une variété de tâches. Il souligne néanmoins que des systèmes spécialisés existent, et que ces derniers « fournissent des bénéfices mesurables lorsque la tâche est bien définie, les données disponibles et que les institutions peuvent le déployer volontairement ».
Il souligne cela dit l’absence d’égalité dans l’évolution de ce type de technologies : trois quarts de la puissance des supercalculateurs d’IA les plus performants est disponible aux États-Unis, la Chine en compte 15 %, et le reste du monde se partage le solde. De même, ces deux pays concentrent l’essentiel des modèles les plus avancés. Nombre de pays en développement, en revanche, manquent des infrastructures leur permettant de participer à la construction des modèles ou de les auditer. Le risque, alertent les scientifiques : que le déploiement accéléré de l’IA n’aggrave les inégalités et dépendances préexistantes à l’échelle du globe.
Côté usages, les auteurs du rapport soulignent les enjeux soulevés par la multiplication de contenus pédopornographiques et de deepfakes à caractère sexuel, tous générés par IA. Ils constatent la facilité avec laquelle l’IA générative permet de fabriquer du faux, de manière crédible, et alertent sur les effets que cela a sur les débats publics, ou encore de son rôle pour faciliter divers types de cyberattaques. Ils soulignent, enfin, comment la « complaisance » des modèles grands public peut renforcer les convictions des internautes, y compris lorsque celles-ci sont dangereuses.
Étonnamment, le document n’évoque à aucun moment l’opposition croissante à l’intelligence artificielle (notamment générative), quelquefois incarnée plus localement par une opposition à ses infrastructures. Celle-ci est pourtant visible jusque dans le pays leader de l’industrie, que sont les États-Unis.
Il n’évoque pas, non plus, les travailleurs des données, certes souvent invisibilisés, dont le rôle est pourtant essentiel à la fabrication des systèmes d’IA évoqués. Parmi les pays qui, faute d’infrastructure, se retrouvent privés des capacités d’« adapter » les modèles « à leurs propres réalités », certains comme le Venezuela, le Kenya ou Madagascar, sont aussi les foyers de clusters d’entraîneurs de données dont le travail est nécessaire pour faire fonctionner les modèles évoqués.
En revanche, pour António Guterres, la publication de ce rapport préliminaire doit être perçue comme la première étape d’un travail collectif, dans lequel il enjoint les États membres à construire un cadre international de coopération sur l’IA. Mais même ce travail promet d’être complexe : le rapport explique en effet que « la plupart des pays, y compris de nombreuses économies avancées, manquent d’expertise technique qui leur permettrait d’évaluer les modèles "frontière" les plus efficaces ou de participer à leur gouvernance de manière significative ».
Cinq chauffeurs de VTC ont déposé plainte pour traite d’êtres humains contre Uber, une action qui vient s’ajouter à celle de quatre livreurs contre Uber Eats et Deliveroo.
Cinq chauffeurs de VTC ont déposé plainte au pénal contre Uber. D’après les informations de Libération, ils accusent la société de « traite d’êtres humains ». Au dossier sont versés les éléments collectés au gré de plus de 300 procédures lancées aux prud’hommes et soutenues par le syndicat FO-INV, qui aide les plaignants à demander la requalification de leurs contrats de travail.
La plainte est déposée quelques jours à peine après le reflux d’une vague caniculaire pendant laquelle les conditions de travail de certains de leurs collègues, livreurs de repas à domicile, se sont elles aussi dégradées. Auprès de Politis, nombre d’entre eux décrivent un surplus de commandes alors même que les trajets à vélo ou à scooter sont rendus d’autant plus épuisants par la chaleur.
Travailler sans pouvoir payer son loyer
La plainte pour traite d’êtres humains, elle, ne concerne pour le moment que des cas de chauffeurs VTC. Le membre de l’INV Brahim Ben Ali détaille à Libération les cas de chauffeurs « décédés de crises cardiaques ou d’AVC alors qu’ils conduisaient » (au moins huit en un an), les situations de « travailleurs sans-papiers », de « vulnérabilité », de « surendettement ». Chauffeur depuis 2019, plaignant dans l’affaire, Mohammed, 50 ans, se décrit comme « prisonnier » d’un système sur lequel il n’a pas de prise : nombreux sont ceux qui, comme lui, enchaînent les heures de travail sans parvenir pour autant à assumer le poids de leur loyer et autres charges.
Couplé à la recherche permanente d’augmentation des profits de la part des plateformes, le conseil d’INV maître Samir Kahoul estime que ces éléments, dont le « recrutement massif et organisé » d’une catégorie précise de la population, à l’aide d’outils numériques, permettent de caractériser la traite d’êtres humains. À ses côtés, Brahim Ben Ali appelle à ne plus simplement discuter d’« indépendance » et de « salariat », mais bien à ouvrir le débat sur l’esclavage moderne.
Un enjeu qu’Uber, dans son cas, rejette clairement, qualifiant les prises de position de Brahim Ben Ali de diffamation.
Un enjeu qui relie divers types de travail des plateformes
Difficile, néanmoins, de ne pas faire le lien avec une autre plainte, déposée fin avril, contre Deliveroo et Uber Eats. Cette fois-ci, ce sont quatre livreurs qui ont accusé les deux plateformes de traite d’êtres humains, critiquant non seulement la baisse régulière des rémunérations, mais aussi le recours important à des travailleurs sans papiers et une organisation « violente » recourant de manière « systématique » à la discrimination.
En mars 2025, l’Agence nationale de sécurité sanitaire de l’alimentation, de l’environnement et du travail (Anses) publiait un long avis détaillant l’ampleur des risques psychosociaux auxquels est exposée cette catégorie de travailleurs. Un an plus tard, un autre travail réalisé par Médecins du Monde, l’Institut de recherche pour le développement et l’Institut national d’études démographiques (Ined) constatait que que 85 % des livreurs souffraient de fatigue chronique, 45 % étaient en détresse psychologique, 36 % touchés par des douleurs « intenses et régulières » au bas du dos, pour un revenu net moyen de 880 euros, soit bien en-dessous du smic.
Leur plainte prend une nouvelle couleur alors que le mois de juin 2026 a enregistré des records de chaleur. Auprès de Politis, le coordinateur de la Maison des livreurs de Bordeaux Jonathan L’Utile Chevallier constate que « notre société est en train de s’habituer à ce que des personnes essentiellement étrangères et racisées nous servent », sans préoccupation pour la complexité accrue de leur activité lors des épisodes climatiques extrêmes (grand froid ou canicule).
Hors de France, des discussions sont déjà ouvertes pour d’autres types de travail des plateformes. C’est notamment le cas d’entraîneurs de données kényans, qui adressaient en 2024 une lettre ouverte au président des États-Unis, Joe Biden, l’appelant à mettre fin aux modèles déployés par les géants du numérique, qui les maintiennent, eux, dans des « conditions de travail relevant de l’esclavage moderne ».
En novembre, la population californienne devra voter sur un projet de taxation de ses milliardaires. Retour sur les enjeux.
La Californie adoptera-t-elle une taxe sur le patrimoine des milliardaires ? Portée par le syndicat du personnel de santé, le Service Employees International Union-United Healthcare Workers West (SEIU-UHW), la proposition prévoit de prélever 5 % d’impôt sur le patrimoine de tous les résidents de l’État au 1er janvier 2026 détenteurs de plus d’un milliard de dollars de patrimoine.
Quand bien même ce projet ne concerne que cet État précis, l’idée, elle, est devenue un sujet de débat à l’échelle nationale, en amont des élections de mi-mandat prévues en novembre aux États-Unis.
Alors qu’elle a largement dépassé le nombre de signatures nécessaires pour être soumise au vote de la population californienne, et serait selon certains sondages soutenue par 54 % de la population locale, elle rencontre une opposition croissante des principaux concernés. L’industrie de la tech et celle des cryptoactifs emploient désormais une partie de leur fortune à allumer des contre-feux.
Une taxe ponctuelle après la baisse des dépenses de santé
Tel qu’il est dessiné, le projet est pour le moment temporaire. Si elle est acceptée, la loi californienne sur l’imposition des milliardaires prélèverait donc 5 % de la fortune des milliardaires locaux. Le but : financer les programmes de santé, d’éducation et d’aide alimentaire de l’État, singulièrement éprouvé par la « belle loi unique » (« One Big Beautiful Bill Act ») de Donald Trump. Adopté le 5 juillet 2025, ce texte a notamment réduit les dépenses fédérales en matière de santé.
Auprès du Guardian, la directrice du SEIU-UHW indique que le projet de taxation des plus riches était une réponse directe à cette évolution législative, et qu’il visait à rétablir un déséquilibre existant selon lequel les « travailleurs normaux paient un taux effectif d’impôt plus élevé que les états-uniens les plus riches ». Au total, la Californie comptait au 1ᵉʳ janvier environ 200 foyers à la fortune supérieure au milliard de dollars.
Un an plus tôt, la joint venture Silicon Valley constatait que le seul berceau de l’industrie technologique, la Silicon Valley, comptait de son côté neuf milliardaires détenant 15 fois plus de liquidités que la moitié de la population de la zone. Parmi eux : Mark Zuckerberg, fondateur de Meta, Larry Page et Sergey Brin, fondateurs de Google, Jan Koum, cofondateur de WhatsApp, Jensen Huang, patron de NVIDIA, ou Laurene Powell Jobs, philanthrope et veuve du fondateur d’Apple. Le think tank qualifiait la situation de propice à « l’instabilité » et « la révolte ». Depuis, l’essentiel des acteurs de la tech a encore accru sa fortune à la faveur de l’expansion de l’industrie de l’intelligence artificielle.
Si la taxe était appliquée, elle pourrait rapporter 100 milliards de dollars, calculent ses promoteurs.
Pour la directrice du SEIU-UHW, « demander à ceux qui ont le plus profité de l’économie de contribuer plus – en particulier à stabiliser le système de santé, qui est menacé – en est une étape raisonnable ». Les grandes fortunes locales, elles, ne l’entendent pas de cette oreille.
Depuis le début des travaux pour collecter du soutien à la mesure, nombre d’entre eux ont reproduit le schéma éprouvé lors de la campagne présidentielle précédente, en versant des millions de dollars à des comités d’action politique (PAC).
Principaux financeurs de cette opposition, Sergey Brin a versé au moins 82 millions de dollars dans des travaux d’opposition à cette taxe, et le crypto-milliardaire Chris Larsen, au moins 13,2 millions de dollars. Derrière eux, le cofondateur de Palantir Peter Thiel, l’ex PDG de Google Eric Schmidt, le PDG de Doordash TonyXu, celui de Stripe Patrick Collision et plusieurs capitaux-risques ont aussi mis la main à la poche, liste le Guardian.
En quelques semaines, cela leur a permis de faire émerger deux contre-propositions de loi qui seront, elles aussi, soumises au vote en novembre. Avec le risque de confondre les électeurs lorsqu’ils seront face aux trois propositions de texte.
La forme de la réforme contestée plus largement
En dehors de ces magnats qui luttent pour préserver leur propre fortune, plusieurs organisations s’opposent aussi à la proposition de taxation du SEIU-UHW. L’association des enseignants californiens, des groupes de l’industrie de la construction, et d’autres du domaine de la santé, dont l’affiliation californienne du planning familial, critiquent la manière dont elle est écrite. Ils regrettent, notamment, que la proposition d’imposition ne permette aucun financement de long terme : si la loi passe, la taxe ne serait prélevée qu’une fois, à raison d’1% par an sur cinq ans.
Le gouverneur de Californie, Gavin Newsom, est lui aussi au nombre des opposants. Il affirme que cette nouvelle imposition fera fuir les milliardaires de Californie. L’argument est fréquent, lorsque les questions d’imposition des hautes fortunes occupent le débat public. En France, où il est cité autour des projets de taxe sur les ultra-riches, dite taxe Zucman, les faits tendent pourtant à l’infirmer. De même, en Suède, qui a appliqué un impôt sur la fortune pendant près d’un siècle avant de le supprimer en 2007, l’évolution de ces taxations n’a eu qu’un effet infime sur la migration des plus riches.
Deux Français ont d’ailleurs participé à l’élaboration de la proposition du SEIU-UHW : les économistes Gabriel Zucman et Emmanuel Saez, spécialistes des questions de taxation des hauts patrimoines.
Depuis quelques jours, le climatologue Christophe Cassou et l’économiste du climat Vincent Viguié sont pris à partie sur les réseaux sociaux.
Leurs torts ? Avoir souligné l’urgence de s’adapter au changement climatique, et les problèmes que le déni climatique posait en la matière. Ou, avoir souligné que le débat sur la climatisation faisait, précisément, partie des stratégies d’obstruction à l’adaptation : si ces outils peuvent constituer des solutions temporaires, ils ne permettent en rien de répondre à l’ampleur des évolutions nécessaires pour s’adapter au contexte climatique, et encore moins pour aller vers une réduction des émissions de CO2.
Dans le cas de Christophe Cassou, l’extrait d’interview diffusé par BFM sur X n’intègre pas la nuance que le climatologue lui-même ajoute à ses propos un peu plus tard dans l’entretien (après avoir expliqué que les débats sur la climatisation relèvent de l’« enfumage », qui empêche d’« aborder les vraies questions », il admet que, pour autant, hôpitaux, écoles et divers autres établissements gagneraient à s’en équiper).
Illustration : Flock
Pour avoir détaillé ces faits scientifiques, relève le média BonPote, les deux hommes se retrouvent pris à partie par des internautes, des journalistes et des représentants politiques. Sur X, c’est par exemple le cas de François de Rugy (Les Républicains, vice-président du conseil régional des Pays de la Loire, 76 000 followers) ou Jean-Philippe Tanguy (Rassemblement National, député, 107 000 followers).
Ce genre de violence numérique n’a rien de neuf, en particulier sur cette plateforme où les communautés climatosceptiques sont actives depuis longtemps. Après le rachat de la plateforme par Elon Musk et la fin de ses pratiques de modération historiques, quantité de scientifiques et de défenseurs de l’environnement avaient fui la plateforme pour se protéger de la violence qui les y visait.
Pendant la semaine de canicule, ce genre de violence en ligne avait déjà visé de nombreux profils travaillant de près ou de loin sur les questions environnementales, en particulier des journalistes météo et d’autres climatologues.
Comme le souligne BonPote, il s’agit aussi, pour certains partis, de détourner l’attention de leurs actions en matière d’environnement : plus les partis sont positionnés à droite sur l’échiquier politique, plus ils ont voté de textes en faveur de la consommation d’énergies fossiles sur l’exercice parlementaire 2022 - 2025.
La présence de journalistes, comme la rédactrice en chef du service société du Point Géraldine Woessner (114 000 followers), parmi les internautes qui prennent à partie Christophe Cassou, interroge aussi sur le rôle des médias dans l’épisode.
Dans une récente tribune parue dans Le Monde, le journaliste Sylvestre Huet souligne ainsi que les médias, comme les représentants politiques (et dans une certaine mesure, les citoyens eux-mêmes) gagneraient à faire leur autocritique de manière urgente s’ils veulent réussir à expliquer pourquoi la mésinformation climatique continue de proliférer, y compris sous 40 °C.
Avec son nouvel Observatoire des pratiques de l’influence, l’association Paye ton influence éclaire les pratiques publicitaires des marques de grande consommation. Que ce soit en matière de partenariats avec des influenceurs ou de publications sponsorisées, les géants de l’ultra fast-fashion Shein et Temu inondent TikTok, Instagram et YouTube.
Pour qui les créatrices et créateurs de contenu en ligne font-ils de la publicité ? Dans 16 % des cas, pour des marques de mode, dans 17 % des cas, pour des marques de beauté. La technologie arrive en troisième position (11,5 % des publicités), suivie par l’alimentation (11,3 %).
Deux des dix marques qui ont le plus de partenariats avec des influenceurs sont des marques à impact sociaux et écologiques « jugés négatifs », indique l’Observatoire des pratiques de l’influence : Temu et Shein. Ces enseignes correspondent aux « marques aux impacts négatifs avérés, comme la fast-fashion, les industries fossiles, etc », explique à Next Amélie Deloche, cofondatrice de l’association Paye ton Influence.
Dans l’analyse menée avec l’aide de l’ONG Data for Good, ce type de marques représente 10 % du panel de 1 308 enseignes repérées. Elles totalisent en revanche 18 % des publications sponsorisées étudiées. L’enjeu d’autant plus important que l’ensemble des internautes s’informe désormais plus via les plateformes, notamment sociales, que via les sites web ou applications de média. C’est donc là qu’ils sont le plus exposés à des publicités, en particulier lorsqu’ils ont entre 18 et 24 ans. En effet, dans cette tranche d’âge, plus d’une personne sur deux (52 %) déclare consommer son information sur les réseaux sociaux et plateformes de vidéos.
Lutter contre les impacts environnementaux de la consommation.
Créé en décembre 2021, Paye ton influence veut « provoquer le réveil écologique du secteur de l’influence et responsabiliser ses acteurs ». En pratique, il s’agit de dénoncer « les imaginaires à rebours des enjeux environnementaux popularisés par les influenceurs : surconsommation, partenariats avec des entités responsables d’impacts écologiques et sociaux importants, mise en avant de lobbies », indique l’association sur sa page Tipeee.
Il reste 70% de l'article à découvrir. Vous devez être abonné•e pour lire la suite de cet article. Déjà abonné•e ? Générez une clé RSS dans votre profil.
Présenté comme « révolutionnaire », le climatiseur Epicooler, qui jouit de nombreuses vidéos YouTube et supposés tests indépendants positifs, cache en fait une arnaque.
Les publicités pour le faux climatiseur tournent depuis des semaines, en ligne. Il s’appelle Epicooler, il est présenté comme « révolutionnaire », « sans installation », affiché autour de 110 euros. Une affaire, pour faire face aux canicules ambiantes. Problème : ce climatiseur n’en est pas un, et souvent, la commande n’est même pas honorée.
Rien que l’affichage du prix est trompeur : sur les publicités, l’Epicooler est annoncé à 110 euros, mais la facture grimpe à 157,97 euros, ou 241,96 euros si vous en achetez deux. Raison avancée : les « frais de port et de douanes ». Sur Signal-Arnaques comme sur Trustpilot, les avis négatifs s’accumulent.
Un climatiseur qui défie les lois de la physique
Surtout, la description du produit lui-même pose problème. L’Epicooler est présenté comme un « climatiseur portable sans installation », théoriquement à même de refroidir une pièce de 51 m² sans compresseur ni tuyau d’évacuation. L’opportunité semble en or, sauf que matériellement, elle décrit un phénomène impossible : sans ces deux éléments, impossible d’évacuer la chaleur.
Comme le remarque Clubic, la foire aux questions du site web d’Epicooler vend (un peu) la mèche. Pour expliquer l’absence de tuyau, elle indique que « l’eau de condensation s’évapore à l’intérieur de l’unité », c’est-à-dire qu’elle n’est pas évacuée, donc que la chaleur reste dans la pièce. De fait, comme le rapportent de multiples utilisateurs mécontents, l’objet n’est qu’un simple ventilateur.
Outre la marchandise trompeuse, tout ce qui entoure sa vente relève de l’arnaque. Débités, certains clients n’ont rien reçu du tout. Créé en avril 2026, le site epicooler.fr lui-même n’est qu’une collection de liens affiliés et porte les traces de multiples copies en fonction des marchés visés – l’Australie, notamment, est visée depuis plusieurs mois.
Derrière le nom Epicooler et ses copies Coolizi, Breezo ou Jiubery, Clubic a identifié la société lituanienne UAB Dara Digital. C’est cette dernière qui expédie (ou pas) les engins à ses clients. C’est aussi elle qu’on retrouve derrière d’autres objets vendus comme « miracles », dont la buse à haute pression Jetterix, les écouteurs SonaBuds ou encore les patchs chauffants WellHeat, supposés soulager les tensions musculaires.
Mais revenons à nos climatiseurs qui ne climatisent pas, et sont aussi vendus sous le nom de Coolizi. Sur le site de cette autre marque est référencée la société Dedata International, dont l’adresse juridique se trouve aux États-Unis, et celle physique, dans un immeuble de domiciliation de Hong Kong. Le numéro de TVA, quant à lui, est maltais, ce qui laisse supposer que la société récupère ainsi la TVA européenne.
Pour promouvoir le tout, le réseau d’arnaque semble avoir mis la main sur des chaînes YouTube et divers blogs, via lesquels des heures de reviews et de tests visiblement générés par IA donnent des retours élogieux du produit. De quoi piéger de nombreux internautes : Médiamétrie a constaté qu’un quart des Français visitaient régulièrement des sites entièrement générés par IA, et que les plus de 50 ans étaient les plus exposés à ces contenus de faible qualité, représentant 75 % des internautes attirés par les sites GenAI.
En pleine période de fortes chaleurs (et de soldes prolongés !) attention, donc, aux cyberarnaques. Pour protéger les autres internautes, il est utile de rapporter les escroqueries sur les plateformes Signal Conso et Pharos.
Et pour éviter de tomber soi-même dans le panneau, le ministère de l’Économie propose une série de mesures mêlant vérification de la réputation du site internet et de ses mentions légales à celle des avis consommateurs, en passant par le fait de privilégier des sites français ou européens, ou par un réflexe simple : si l’offre est trop alléchante, méfiance.
L’écrivain Julien Blanc-Gras a vu son nom utilisé pour promouvoir un livre qui n’est pas de lui. L’affaire illustre un phénomène plus large d’usurpations d’identité de personnalités publiques, qui prend un nouveau tour à l’ère de l’IA générative.
Il s’appelle Julien Blanc-Gras, il a écrit des livres comme Gringoland (Au diable Vauvert, 2005), In Utero (Au diable Vauvert, 2015) ou Bungalow (Stock, 2024), mais il n’a pas écrit Guide complet d’aventure : le manuel de survie du voyageur moderne. L’ouvrage, pourtant, était bien disponible à l’achat sur Amazon, pour la somme de 17,05 euros, jusqu’à récemment.
L’écrivain a pris la plume, dans Le Monde, pour raconter cette expérience. Outre produire une jolie chronique, il illustre bien le casse-tête dans lequel se retrouvent artistes, journalistes et autres personnalités présentes en ligne lorsque leur nom est réutilisé, sans consentement, pour donner une forme d’autorité à des contenus générés par intelligence artificielle (IA).
L’objet de l’inconfort a été mis en vente le 20 mars, compte 134 pages, et est décrit, dans sa présentation, comme une « méthode redoutable pour retrouver la liberté de voyager intelligemment, hors des sentiers battus », produite par « l’auteur baroudeur et écrivain Julien Blanc-Gras ». Ce dernier conteste. Et raconte la « sidération » qui l’a traversé, lorsqu’il a découvert ce produit sur la page Amazon qui liste ses ouvrages.
Comme lui, plusieurs autrices et auteurs anglophones ont eu au fil des années récentes le déplaisir de voir leur nom utilisé pour vendre des ouvrages qu’ils n’avaient pas produits. Vanessa Fox O’Loughlin a ainsi vu son nom de plume, Sam Blake, réutilisé pour produire les textes du personnage qu’elle qualifie de « Sam Fake ».
En 2023, Jane Friedman, elle, a dû se battre pour obtenir le retrait de cinq ouvrages proposés sur Amazon sous son nom. La plateforme d’e-commerce a commencé par lui déclarer que, dans la mesure où son nom n’était pas déposé comme une marque, donc pas protégé comme tel, elle ne supprimerait pas les produits en question. Après que l’autrice s’en est émue publiquement, cela dit, les ouvrages ont disparu de la page Amazon à son nom.
Le cas de Julien Blanc-Gras, lui, est le premier connu en français. « Dans un geste masochiste », l’auteur raconte avoir acheté le livre pour voir de quoi il retournait. Il décrit la couverture « hideuse », la quatrième de couverture « rédigée avec des bullet points », la mention « publié indépendamment », probable traduction littérale de la formule anglaise « published independently ».
Deux jours plus tard, il a reçu l’objet, dont l’immatriculation ISBN est « bidon ». Dans ses pages, des termes inexistants, comme l’ « inflatrooting ». Des thématiques relativement cohérentes avec l’œuvre de l’auteur, aussi (« immersion culturelle, goût de l’imprévu, souci environnemental »). Sauf qu’elles sont remâchées « dans une novlangue de camelot sous ayahuasca refourguant des investissements en cryptomonnaies sur Instagram ».
Guide complet d’aventure supposément écrit par Julien Blanc-Gras – archive.is
Julien Blanc-Gras est visiblement choqué et déçu de voir son art remixé par une machine, et son nom « estampillé influenceur marketing ». Sur la raison pour laquelle son identité est ainsi réutilisée, le rédacteur en chef adjoint du média l’ADN, David-Julien Rahmil, lui soumet l’hypothèse que des scammeurs aient repéré une « catégorie " niche ", les livres de voyages, en l’occurrence », puis un nom crédible – celui de Julien Blanc-Gras – pour faire remonter leur produit dans les systèmes de recommandations d’Amazon :
« Ça pourrait venir de la communauté des hustle bros, ces influenceurs business qui proposent de devenir riche en cinq minutes sur les réseaux. Ils lancent une arnaque qui rapporte peu, mais ils l’utilisent ensuite comme exemple pour vendre leur méthode. »
Éditeur « abasourdi et démuni »
Hustle bros ou pas, l’auteur usurpé voudrait bien que son nom cesse d’être accolé à du jus d’IA. Et là, les choses se corsent. Son éditeur se déclare « abasourdi et démuni ». Le service juridique de la maison d’édition se déclare incapable d’aider, dans la mesure où c’est le nom de Julien Blanc-Gras qui est visé, et non celui de la maison. Le Syndicat national des auteurs et des compositeurs (SNAC) recommande de son côté de faire des signalements à la répression des fraudes et à Pharos, ce à quoi l’écrivain ajoute un signalement à Amazon.
Côté droit, l’avocat spécialiste du droit d’auteur Benjamin Demange constate que l’usurpation d’identité n’est « pas évidente » : difficile de démontrer devant un juge que le recours au nom de l’artiste « trouble [sa] tranquillité », comme le veut le code pénal. L’escroquerie serait éventuellement plaidable, mais le montant est si faible que la plainte peinerait à être traitée en priorité. Le droit de la propriété intellectuelle (qui refuse les atteintes au droit à la paternité) et celui de la consommation (qui permettrait d’avancer la pratique commerciale trompeuse) pourraient fournir plus de recours, à condition d’identifier les auteurs de l’arnaque. Or, pour cela, il faudrait qu’Amazon consente à partager les informations nécessaires.
C’est devant la relative impasse que Benjamin Demange explique avoir choisi une autre solution : « activer le quatrième pouvoir en racontant cette histoire dans Le Monde ». De fait, partager le phénomène permet de souligner à nouveau la foule de problématiques que le déploiement de l’IA générative crée pour les artistes et autres créateurs de contenu.
Il y a, pour commencer, tout ce qui touche à l’entraînement des modèles par le recours, sans permission, à des œuvres soumises au droit d’auteur : pour pouvoir produire un fac-similé, quand bien même de niveau très médiocre, du travail de Julien Blanc-Gras, il a fallu qu’un modèle ait absorbé tout ou partie de son œuvre en amont.
Il y a, ensuite, cet enjeu émergent des usurpations d’identité. D’ores et déjà visible chez les auteurs, il concerne aussi toutes sortes de personnalités présentes en ligne. L’affaire Grammarly, qui fournissait jusqu’au 11 mars 2025 un outil nommé « révisions expertes », l’a bien illustré. Le correcteur orthographique suggérait en effet de reprendre les textes des internautes « à la manière de » personnalités réelles.
À force de tests, nous avions notamment repéré les noms des autrices françaises Annie Ernaux, Delphine de Vigan et Marie Darrieussecq, des chercheuses Geneviève Pruvost et Valérie Masson-Delmotte, et de la journaliste Florence Aubenas. Aucune de celles que nous avons réussi à joindre n’avait donné son consentement à voir son nom cité, ou son expertise imitée par de la génération par IA.
Dans ce cas-là, c’est l’action collective, aux États-Unis, de multiples personnalités visées qui avait permis la suppression de la fonctionnalité incriminée.
Le débat sur la manière de lutter contre les usurpations d’identité facilitées par IA générative, lui, reste ouvert. Outre le problème de la protection de son nom et de son œuvre, il pose aussi celui de la protection des consommateurs : dans un autre genre, on se rappelle des arnaques diffusées en ligne en capitalisant sur l’image de Brad Pitt, d’Élise Lucet ou de Jamel Debbouze.
Il y a des milliers de communautés, en ligne, mais connaissez-vous celle du tricot ? Alimentée par des échanges de patrons, des influenceuses qui dépassent les deux millions d’abonnés sur Instagram, des sites communautaires comme Ravelry ou le temple des créations artisanales Etsy, la pratique s’est tissée une nouvelle jeunesse.
Célébrée lors de la journée mondiale du tricot en public, le 13 juin, l’activité tient aussi bien du rituel que de la recherche de pratiques favorisant la déconnexion, relève l’ADN.
Illustration : Flock
Avant même les débats sur les addictions aux réseaux sociaux, des tricoteuses comme la Néerlandaise Loes Veenstra s’y sont adonnées pour lutter contre l’envie de fumer. Désormais, la pratique est recommandée pour lutter contre toutes sortes d’envies néfastes pour la santé, des troubles alimentaires jusqu’au doomscrolling.
Outre avoir permis d’alimenter les liens de la communauté au-delà des frontières, le numérique est aussi source d’inspiration : certaines, comme l’artiste et chercheuse Hayley Mortin, tricotent ainsi des motifs inspirés des CAPTCHA.
Mais le tricot n’est pas épargné par les maux de notre temps : patrons générés par IA, podcast présenté par des voix générées par IA… Dans la laine comme dans de nombreuses autres activités, l’AI slop vient compliquer la navigation.