Arrêté à sa descente d’avion à l’été 2024, Pavel Durov vient d’obtenir la levée des mesures qui l’empêchaient de voyager à l’étranger.
Né en Russie, naturalisé français en 2021, le cofondateur de Telegram avait été mis en examen pour douze chefs d’accusation relevant de la criminalité organisée.
En mars, il avait obtenu de rentrer à Dubaï, où il est installé. Mais il restait astreint à une limitation de ses allées et venues, et notamment à l’obligation de pointer au commissariat de Nice tous les 14 jours.
Ces mesures ont été définitivement levées, selon l’AFP et Bloomberg.
Les avocats de Pavel Durov soulignent que ce dernier a été interrogé trois fois et a « parfaitement respecté son contrôle judiciaire ».
Ces derniers mois, l’entrepreneur a utilisé à plusieurs reprises sa plateforme pour diffuser des messages critiquant les autorités françaises ou les politiques européennes.
Un groupe d’une douzaine de pays présents à la COP 30 au Brésil, dont la France, annonce vouloir s’emparer activement de la lutte contre la désinformation sur le climat. En amont du sommet, des ONG avaient sonné l’alarme à propos de la forte propagation de la désinformation climatique sur internet, avec l’IA générative comme nouvel outil de superpropagation.
En marge de la COP 30 qui se déroule actuellement à Belém, au Brésil, 12 pays ont publié une déclaration sur l’intégrité de l’information en matière de changement climatique.
Déclaration de principe de 12 pays
La Belgique, le Brésil, le Canada, le Chili, le Danemark, la Finlande, la France, l’Allemagne, les Pays-Bas, l’Espagne, la Suède et l’Uruguay appellent [PDF] à lutter contre les contenus mensongers diffusés en ligne et à mettre fin aux attaques.
Ils s’y disent « préoccupés par l’impact croissant de la désinformation, de la mésinformation, du déni, des attaques délibérées contre les journalistes, les défenseurs, les scientifiques, les chercheurs et autres voix publiques spécialisées dans les questions environnementales, ainsi que par d’autres tactiques utilisées pour nuire à l’intégrité des informations sur le changement climatique, qui réduisent la compréhension du public, retardent les mesures urgentes et menacent la réponse mondiale au changement climatique et la stabilité sociale ».
Ces pays s’engagent notamment à soutenir l’initiative mondiale pour l’intégrité de l’information sur le changement climatique lancée par l’Unesco.
Des ONG alertent sur la propagation de la désinformation, notamment à propos de la COP 30 elle-même
Début novembre, juste avant l’ouverture de la COP30, une coalition d’ONG (dont QuotaClimat et Équiterre en France) nommée Climate Action Against Disinformation publiait un rapport titré « Nier, tromper, retarder : démystifié. Comment les grandes entreprises polluantes utilisent la désinformation pour saboter les mesures climatiques, et comment nous pouvons les en empêcher ». Le rapport se faisait notamment l’écho d’une énorme campagne de désinformation sur des inondations à Belém, la ville de la COP 30, documentée par la newsletter Oii.
Celle-ci dénombrait plus de 14 000 exemples de contenus de désinformation publiés entre juillet et septembre sur la COP 30 elle-même. Notamment, des vidéos en partie générées par IA qui faisaient croire à des inondations dans la ville.
« « Voici le Belém de la COP30 qu’ils veulent cacher au monde », déclare un journaliste debout dans les eaux qui inondent la capitale de l’État du Pará », décrit Oii. « Mais… rien de tout cela n’est réel ! Le journaliste n’existe pas, les gens n’existent pas, l’inondation n’existe pas et la ville n’existe pas. La seule chose qui existe, ce sont les nombreux commentaires indignés contre le politicien mentionné dans la vidéo et contre la conférence sur le climat à Belém, sur X (anciennement Twitter) et TikTok », déplore la newsletter.
« Des mesures telles que la loi européenne sur les services numériques (DSA), qui s’appliquent au niveau supranational, rendent les grandes entreprises technologiques plus transparentes et responsables des préjudices causés », affirme la Climate Action Against Disinformation. Et elle ajoute que « si certaines entreprises donnent une mauvaise image de tous les réseaux sociaux, des sites web tels que Wikipédia et Pinterest prouvent que les politiques de lutte contre la désinformation climatique et l’intégrité de l’information sont non seulement possibles, mais nécessaires ».
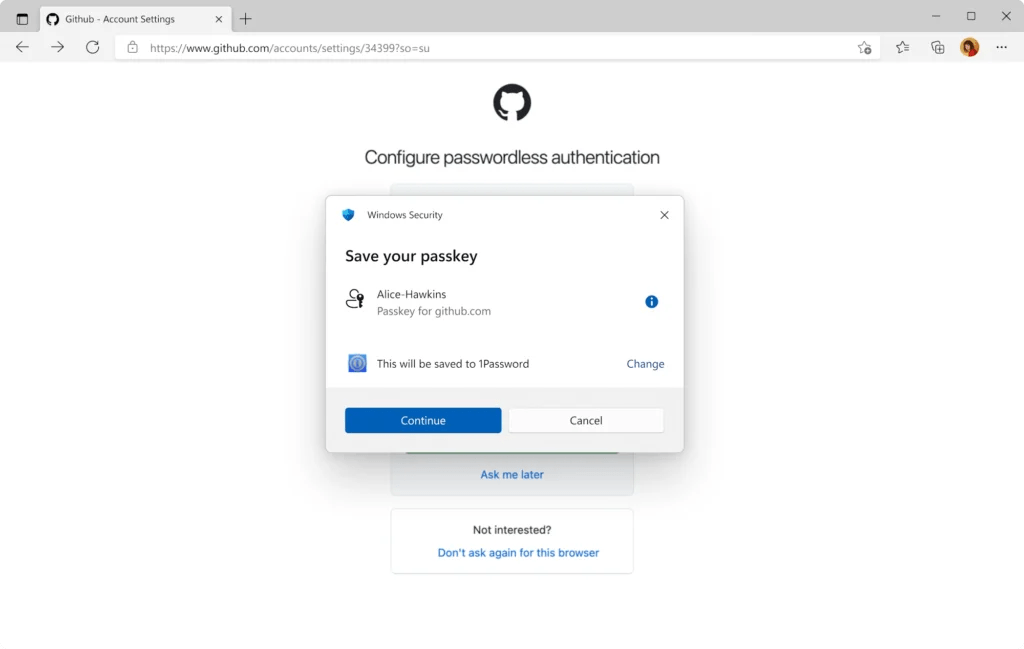
Les mises à jour de sécurité de novembre pour Windows 11 ont doté le système d’une capacité promise il y a quelques mois : permettre aux gestionnaires de mots de passe de s’intégrer totalement dans le système, avec gestion complète des clés d’accès (passkeys). Une intégration qui rappelle celle des mêmes gestionnaires sur Android et iOS.
C’est désormais le cas pour deux d’entre eux, 1Password et BitWarden. Pour le premier, il suffit de récupérer la dernière mise à jour de l’application. Après quoi, on se rend dans les Paramètres de Windows, puis dans Comptes > Clés d’accès > Options avancées. Là, il suffira d’activer le réglage correspondant au gestionnaire.
Pour BitWarden, la manipulation est la même, mais il faut pour l’instant passer par une version bêta de l’application de bureau disponible sur GitHub. Passer uniquement par l’extension pour navigateur n’est pas suffisant, car elle n’agit que dans le contexte du navigateur. Le lien donné par BitWarden dans son billet ne fonctionne cependant pas à l’heure où nous écrivons ces lignes.
L’intégration native a deux avantages. Le principal est que si le système veut stocker une clé d’accès, par exemple parce qu’une application en fait la demande, il interrogera le gestionnaire défini par défaut et pas le composant interne de Microsoft. L’autre est justement la disponibilité des clés d’accès dans tout le système, y compris dans les logiciels tiers et Windows Hello. Le gestionnaire de Microsoft, intégré notamment à Edge, reste disponible, mais devient un citoyen comme un autre au pays de Windows.
Plus de dix ans après sa précédente tentative, Valve retente sa chance sur le marché des consoles de salon avec une nouvelle Steam Machine, un casque VR et une manette revisitée. Cette fois cependant, l’entreprise a des arguments autrement convaincants, en tout cas sur le papier.
Steam Machine
Le cœur de la nouvelle offre matérielle est la Steam Machine. C’est l’équivalent du Steam Deck pour le salon, avec un matériel plus adapté. La Steam Machine est ainsi présentée comme six fois plus puissante que la console portable.
Le cœur de la nouvelle bête est un processeur AMD doté de six cœurs Zen 4 pouvant grimper jusqu’à 4,8 GHz (TDP de 30 W), épaulé par 16 Go de DDR5. Côté graphique, on trouve un GPU AMD RDNA 3 « Navi 33 » équipé de 8 Go de mémoire GDDR6 (TDP de 110 W). Selon The Verge qui était présent à l’évènement de lancement, ce GPU se rapproche des Radeon RX 7600 et 7700, dont la puissance théorique est équivalente ou supérieure à ce que peut fournir une PS5 Pro.
Côté performances, nos confrères disent avoir vu fonctionner le benchmark intégré à Cyberpunk 2077 à une moyenne de 65 images par seconde sur un téléviseur 4K, avec réglages ray tracing positionnés en moyen. Il ne s’agissait cependant pas d’une définition native de l’image, mais d’un 1080p mis à l’échelle via le FSR 3.0 d’AMD. Avec une 4K native, la moyenne était de 24 i/s, mais The Verge fait remarquer que les autres consoles n’utilisent généralement pas non plus la 4K native avec les jeux exigeants.
L’ensemble est intégré dans un boitier cubique de 160 mm d’arête dont l’alimentation est interne. Le refroidissement est assuré par un vaste radiateur à ailettes, des caloducs et un ventilateur de 120 mm dont les pales ont été travaillées pour le silence, selon Valve. En plus du SSD fourni (de 512 Go ou 2 To), la machine contient une baie M2 2280 qui peut accueillir les SSD de taille standard et les modèles plus petits M2 2230 (utilisés notamment par le Steam Deck).
La Steam Machine, qui joue la carte de la sobriété, dispose en outre d’une façade interchangeable. Elle permet de faire varier le style de la console, avec du bois ou autre matériau. The Verge a pu également observer un panneau avec écran e-paper intégré pour afficher des informations sur le fonctionnement de la machine. Ces panneaux s’enlèvent et s’installent via un support magnétique. Valve a indiqué que les fichiers CAO correspondants seraient fournis pour que tout le monde puisse imprimer et/ou fabriquer ses propres panneaux. La personnalisation s’étend à la barre lumineuse sur la façade avant, qui permet d’afficher des informations comme la progression d’un téléchargement. La couleur et l’animation peuvent être changées, et il sera possible de l’éteindre complètement.
La console sera mise en vente début 2026, en deux versions, avec 512 Go ou 2 To de stockage. Elle sera vendue avec ou sans la nouvelle manette, mais Valve n’a pas encore communiqué sur les prix. On retrouvera dans tous les cas deux sorties vidéo (HDMI 2.0 et DisplayPort 1.4), quatre ports USB-A (deux USB 2 et deux USB 3), un port USB-C 10 Gbit/s, un port Ethernet Gigabit, du Wi-Fi 6E (en 2×2) et du Bluetooth 5.3. Sans surprise, la Steam Machine fonctionnera sur SteamOS (basée sur Arch avec KDE Plasma), qui accompagne déjà le Steam Deck.
Signalons enfin que la console peut être aussi bien utilisée au salon avec une manette que sur un bureau avec un clavier et une souris.
Des arguments nettement plus convaincants qu’il y a dix ans
La Steam Machine pourrait rencontrer le succès, là où la précédente tentative de Valve a échoué dans les grandes largeurs. D’une part parce que Valve sera l’unique distributeur de la Steam Machine, alors que la précédente version était davantage un modèle que tous les constructeurs pouvaient reproduire, avec de grands écarts dans les configurations et l’expérience. D’autre part car le contexte a grandement évolué.
On parle bien désormais de Linux comme d’une plateforme de jeu plus que crédible. Valve est pour beaucoup dans cette évolution grâce au Steam Deck, dont le succès incontestable repose sur Proton. Cette couche d’émulation, basée sur Wine, a largement contribué à lubrifier toute la mécanique nécessaire à l’exécution des jeux Windows sur système Linux, avec le plus souvent des performances équivalentes, voire supérieures. Certaines distributions, dont GLF OS, capitalisent sur ce succès croissant.
Steam est aujourd’hui de loin la plus grosse boutique en ligne de jeux vidéo, avec environ 100 000 titres référencés. Beaucoup peuvent être joués sur le Steam Deck, mais la Steam Machine, beaucoup plus puissante, déverrouille presque tout le reste du catalogue. Les 16 Go pourraient se révéler un peu justes dans les prochaines années, mais le vrai cheval de bataille sera le support des jeux par Proton. Le site ProtonDB permet d’ailleurs de suivre le niveau de prise en charge pour chaque titre.
Steam Frame, le nouveau casque VR
Valve retente également sa chance dans le domaine de la réalité virtuelle avec le Steam Frame, qui doit faire oublier le précédent casque, l’Index. Pesant 440 g (contre 809 g pour l’Index), il dispose de deux modes de fonctionnement : soit indépendant, grâce à sa puce Arm et son stockage intégrés (un port microSD est aussi présent), soit comme un écran déporté en exploitant un dongle 6 GHz à brancher sur le PC de jeu (ou la Steam Machine, bien sûr).
L’idée de Valve est simple avec le casque : tous les jeux de votre bibliothèque Steam doivent être jouables sur le Frame, sans fil. The Verge, qui l’a également testé, évoque un très bon confort, avec notamment « un coussin facial particulièrement moelleux et soyeux », ainsi qu’une bonne répartition du poids, la batterie étant placée à l’arrière de la tête.
La solution de Valve est assez originale pour faire fonctionner les jeux. La puce embarquée est en effet un Snapdragon 8 Gen 3, ce qui nécessite une grosse adaptation pour faire tourner des jeux développés pour x86. Un émulateur, nommé Fex, s’occupe ainsi des adaptations en temps réel, mais nos confrères pointent des « accrocs » dans les jeux, dont Hades II et Hollow Knight Silksong.
Valve s’est montrée proactive sur le sujet, indiquant qu’il sera possible de télécharger des versions préconverties du code, de la même manière que le Steam Deck permet de télécharger des shaders précalculés. De manière générale, nos confrères n’ont pas été impressionnés par les performances, mais Valve a évoqué des bugs et promis des optimisations à venir au cours des prochains mois.
La partie matérielle n’est pas non plus la meilleure de sa catégorie, loin de là. Les deux écrans sont de type LCD, avec des définitions de 2160 x 2160. Le passthrough est monochrome, quand le Meta Quest 3D, vendu 300 dollars, dispose d’un passthrough couleur. Pas un problème selon Valve cependant, le Frame ayant été pensé pour le jeu, le passthrough des caméras extérieures n’est là que pour assurer un positionnement. La sangle intègre également deux haut-parleurs de chaque côté, afin d’annuler les vibrations qu’ils engendrent.
À noter que Valve a indiqué à Gamers Nexus que le Frame serait capable de charger les fichiers APK des applications Android, ce qui devrait lui ouvrir de plus amples capacités. Sans surprise, l’autonomie dépendra de l’utilisation. La batterie fournie permet de délivrer 21,6 Wh, soit environ la moitié du Steam Deck. Il sera cependant possible de brancher n’importe quelle batterie d’au moins 45 W via un port USB-C.
Comme pour la Steam Machine, le Steam Frame sera lancé début 2026, sans plus de précisions pour le moment. Le tarif n’a pas non plus été donné.
Le Steam Controller fait peau neuve
En 2013, Valve avait également lancé une manette. Le pari était alors osé, car en lieu et place des contrôles habituels, le Steam Controller proposait deux pads circulaires tactiles. Le stick analogique et les quatre boutons étaient disposés en-dessous et très rapprochés. Aucune croix directionnelle sur cette première manette. L’ensemble fournissait une expérience très différente de ce que l’on pouvait trouver (et que l’on trouve encore) sur les manettes de PlayStation et Xbox.
Entre temps, Valve a cependant lancé son Steam Deck et le travail réalisé sur la console a servi de base pour une nouvelle version de la manette. Les contrôles ressemblent beaucoup plus à ce que l’on trouve ailleurs, avec la croix et les quatre boutons sur les bords, deux sticks analogiques plus centrés, ainsi que deux zones tactiles carrées sur le bas de la manette.
Sur son site, Valve décrit ses sticks comme magnétiques, avec « sensation améliorée, une meilleure réactivité et une fiabilité à long terme ». Les vibrations sont présentées comme « haute définition », avec retour haptique « précis et immersif ». Le nouveau Steam Controller dispose également d’une visée gyroscopique à la demande : si l’on appuie sur les poignées situées sous la manette de chaque côté, on active la visée, qui se coupe quand on relâche la pression. Les pavés tactiles sont décrits comme particulièrement précis, au point de pouvoir être utilisés dans les FPS.
La manette est prévue pour fonctionner partout où Steam est installé, des ordinateurs classiques à la Steam Machine, en passant par le Steam Frame et le Steam Deck. La manette, elle aussi lancée début 2026 (aucun tarif annoncé), sera entièrement personnalisable et présentera deux boutons pour les fonctions maison : un bouton Steam qui sert d’accès à la bibliothèque et de bouton marche/arrêt, et un accès rapide pour les accès aux notifications, contacts, discussions et autres.
Les benchmarks de LLM pullulent mais aucun, ou presque, ne semble s’appuyer sur un travail réellement scientifique, analysent des chercheurs. Ils appellent à une plus grande rigueur.
À chaque publication d’un nouveau modèle pour l’IA générative, l’entreprise qui l’a conçu nous montre par des graphiques qu’il égale ou surpasse ses congénères, en s’appuyant sur des « benchmarks » qu’elle a soigneusement choisis.
Plusieurs études montraient déjà qu’en pratique, ces « bancs de comparaison » n’étaient pas très efficaces pour mesurer les différences entre les modèles, ce qui est pourtant leur raison d’être.
Un nouveau travail scientifique, mené par 23 experts, a évalué 445 benchmarks de LLM. Il a été mis en ligne sur la plateforme de preprints arXiv et sera présenté à la conférence scientifique NeurIPS 2025 début décembre.
Une faible majorité s’appuie sur une méthode théorique robuste
Déjà, une faible majorité (53,4 %) des articles présentant ces 445 benchmarks proposent des preuves de leur validité conceptuelle, expliquent les chercheurs. 35 % comparent le benchmark proposé à d’autres déjà existants, 32 % à une référence humaine et 31 % à un cadre plus réaliste, permettant de comprendre les similitudes et les différences.
Avant de mesurer un phénomène avec un benchmark, il faut le définir. Selon cette étude, 41 % des phénomènes étudiés par ces benchmarks sont bien définis, mais 37 % d’entre eux le sont de manière vague. Ainsi, quand un benchmark affirme mesurer l’ « innocuité » d’un modèle, il est difficile de savoir de quoi on parle exactement. Et même 22 % des phénomènes étudiés par ces benchmarks ne sont pas définis du tout.
16 % seulement utilisent des tests statistiques pour comparer les résultats
De plus, les chercheurs montrent que la plupart de ces benchmarks ne produisent pas des mesures valides statistiquement. Ainsi, 41 % testent exclusivement en vérifiant que les réponses d’un LLM correspondent exactement à ce qui est attendu sans regarder si elles s’en approchent plus ou moins. 81 % d’entre eux utilisent au moins partiellement ce genre de correspondance exacte de réponses. Mais surtout, seulement 16 % des benchmarks étudiés utilisent des estimations d’incertitude ou des tests statistiques pour comparer les résultats. « Cela signifie que les différences signalées entre les systèmes ou les affirmations de supériorité pourraient être dues au hasard plutôt qu’à une réelle amélioration », explique le communiqué d’Oxford présentant l’étude.
Enfin, les chercheurs expliquent qu’une bonne partie des benchmarks ne séparent pas bien les tâches qu’ils analysent. Ainsi, comme ils le spécifient dans le même communiqué, « un test peut demander à un modèle de résoudre un casse-tête logique simple, mais aussi lui demander de présenter la réponse dans un format très spécifique et compliqué. Si le modèle résout correctement le casse-tête, mais échoue au niveau du formatage, il semble moins performant qu’il ne l’est en réalité ».
« « Mesurer ce qui a de l’importance » exige un effort conscient et soutenu »
Dans leur étude, les chercheurs ne font pas seulement des constats. Ils ajoutent des recommandations. Ils demandent notamment à ceux qui établissent des benchmarks de définir clairement les phénomènes qu’ils étudient et de justifier la validité conceptuelle de leur travail.
Pour eux, les créateurs de benchmarks doivent s’assurer de « mesurer le phénomène et uniquement le phénomène » qu’ils étudient, de construire un jeu de données représentatif de la tâche testée et d’utiliser des méthodes statistiques pour comparer les modèles entre eux. Enfin, ils leur conseillent de mener, après avoir conçu leur benchmark, une analyse des erreurs « qui permet de révéler les types d’erreurs commises par les modèles », ce qui permet de comprendre en quoi le benchmark en question est réellement utile.
« En fin de compte, « mesurer ce qui a de l’importance » exige un effort conscient et soutenu de la part de la communauté scientifique pour donner la priorité à la validité conceptuelle, en favorisant un changement culturel vers une validation plus explicite et plus rigoureuse des méthodologies d’évaluation », concluent-ils.
« Les benchmarks sous-tendent presque toutes des affirmations concernant les progrès de l’IA », explique Andrew Bean, dans le communiqué, « mais sans définitions communes et sans mesures fiables, il devient difficile de savoir si les modèles s’améliorent réellement ou s’ils en donnent simplement l’impression ».
Un email, c’est une carte postale. La métaphore n’est pas nouvelle, mais elle n’en reste pas moins toujours vraie. Mais savez-vous vraiment comment circulent les emails et qui peut y accéder ? Next vous explique leur fonctionnement et comment vérifier qui y a potentiellement accès.
En marge de notre dossier sur le fonctionnement en profondeur d’Internet, nous avons décidé de nous pencher sur les emails. Ils sont utilisés par tout le monde, parfois pour des futilités, parfois pour des choses importantes. Ils constituent aussi un enjeu de souveraineté, malheureusement trop souvent pris à la légère.
Un email par défaut, il faut le considérer comme une carte postale : n’importe quel intermédiaire peut lire son contenu, son expéditeur et son destinataire. Pire encore, il est facile d’usurper n’importe quelle identité. On peut évidemment appliquer une couche de chiffrement – un peu à la manière de mettre la carte postale dans une enveloppe –, mais c’est un autre sujet que nous aborderons dans un second temps.
Tout d’abord, comment se passe l’envoi d’un email ? Il faut savoir que l’email se décompose en deux principales parties, regroupés au sein de ce qu’on appelle le format MIME (Multipurpose Internet Mail Extensions ou Extensions multifonctions du courrier Internet) :
Une en tête (header) avec l’expéditeur, le destinataire, le sujet, la date…
Le corps du message (body) avec le contenu de l’email et les éventuelles pièces jointes
La première partie du voyage de notre message se déroule dans un client de messagerie (Mail User Agent ou MUA) de l’expéditeur, que ce soit une application ou depuis un site web. L’acheminement du courrier se fait ensuite vers un serveur de courriel (Mail Transfer Agent ou MTA) rattaché à votre nom de domaine, via le protocole SMTP. À partir de là, la moitié du chemin est faite.
On peut se faire passer pour n’importe qui, la preuve !
L’email passe du serveur MTA lié à votre messagerie au serveur MTA rattaché au nom de domaine de votre destinataire. Par exemple, si vous m’envoyez un email sur une adresse en @next.ink depuis un email @Orange.fr, le serveur MTA de départ sera celui d’Orange, celui de réception est chez moji (qui héberge Next.ink). De son côté, le destinataire récupère son email via son client de messagerie relié au MTA (de moji, vous suivez ?).
Le problème avec cette architecture, c’est qu’il est très facile pour n’importe qui de faire n’importe quoi. En effet, on peut facilement modifier les en-têtes pour changer l’expéditeur et se faire passer pour une autre personne.
N’allez en effet pas croire que c’est compliqué à mettre en place… quelques lignes de codes et une dizaine de minutes suffisent. Pour créer le message ci-dessous, nous avons simplement assemblé un email avec les éléments suivants (oui, c’est aussi simple que ça en a l’air, mais nous ne ferons pas de tuto) avec le résultat juste en dessous :
message = MIMEMultipart()
message["From"]="Sundar Pichai sundar.pichai@google.com"
message["Subject"]="Trop bien guys votre enquete sur les sites GenAI !"
message["Reply-To"]="sundar.pichai@google.com"
Vers qui partent les emails ? Les enregistrements MX balancent tout !
Les mails pouvant circuler dans tous les sens sans restriction particulière par défaut, les serveurs associés aux adresses emails sont publics. On les trouve dans les enregistrements MX des noms de domaines ; MX pour Mail eXchange. Pour simplifier, quand vous m’envoyez un email à sebastien@next.ink, ils sont envoyés au serveur oui.do.
Cette information est publique, dans le DNS, lisible par tout le monde depuis son ordinateur. Deux outils extrêmement simples permettent de récupérer les enregistrements MX : nslookup et dig (il en existe bien d’autres).
Sous Windows et Linux, nslookup est disponible en ligne de commande. Il existe aussi dig, plus complet, sur les distributions Linux. Voici les commandes à utiliser dans les deux cas, pour les serveurs emails recevant tous les envois vers @next.ink. Pour dig, nous avons ajouté le paramètre +short afin de n’avoir que les champs MX les uns en dessous des autres sans tous les détails supplémentaires, mais vous pouvez l’enlever pour une réponse plus longue.
nslookup -type=mx next.ink
dig +short MX next.ink
Dans les deux cas, le résultat est évidemment le même : mx1.oui.do avec une préférence à 1 et mx2.oui.do avec la préférence à 2. La préférence est simplement l’ordre dans lequel il faut choisir les serveurs pour envoyer les emails. mx1.oui.do est le premier, mais s’il ne répond pas, un serveur secondaire est disponible sur mx2.oui.do.
Ce que les enregistrements MX permettent de prouver
Cela signifie donc qu’un simple coup d’œil à l’enregistrement DNS permet de savoir qui s’occupe de la réception des emails. Si une entreprise utilise les services de Google pour gérer ses emails, les enregistrements MX pointeront vers des sous domaines de Google.com. Pour du Microsoft, ils pointent vers du Outlook.com, etc.
Quelques points à savoir. Les serveurs MX indiquent la route à suivre et pointent vers le premier « poste de douane », c’est-à-dire l’endroit où arrivent les emails avant d’être ensuite acheminés vers leur destinataire. Ils peuvent ensuite prendre des chemins plus ou moins long et sinueux avant d’arriver à destination, mais nous n’avons pas accès aux détails des routes, c’est de la tambouille interne.
Voici quelques exemples. Certains comme Polytechnique et l’Université de Paris Saclay gèrent la réception en interne, d’autres comme l’Université de Versailles Saint-Quentin passent par Renater (Réseau National de télécommunications pour la Technologie, l’Enseignement et la Recherche). Blablacar utilise de son côté Google.
Cela ne veut pas obligatoirement dire que les mails @Blablacar.fr finissent dans une boite Gmail ou un compte Google Workspace, mais cela prouve néanmoins qu’ils arrivent chez Google comme premier poste de douane.
Le géant du Net a donc accès à un moment donné à tous les emails envoyés à @Blablacar.fr. Et comme tout poste de douane qui se respecte, il peut décider du jour au lendemain de couper l’accès, mais de continuer à recevoir les emails entrants, jusqu’à ce que les enregistrements MX soient changés.
Autre point important, ce n’est pas parce qu’une entreprise passe par autre chose que Google ou Outlook dans ses enregistrements MX, qu’elle n’utilise pas à un moment donné les services des géants américains ; simplement les enregistrements MX ne permettent pas de le prouver.
Certains comme Shares.io – une plateforme d’investissement « développé, opéré et régulé en France » – doublent la mise avec Google comme enregistrements MX primaire, secondaire et tertiaire, ainsi que Outlook en quatrième position si les trois serveurs Google devaient ne pas répondre. Ceinture et bretelle aux couleurs des États-Unis en somme.
Un vrai enjeu de souveraineté !
En résumé : si les MX pointent vers Google ou Microsoft, cela prouve que les entreprises américaines ont accès aux emails, peu importe où ils finissent par arriver. Mais nous ne pouvons en déduire rien de plus ; aucun corollaire n’existe à cette affirmation.
Par exemple, les enregistrements MX de Next.ink renvoient vers oui.do, mais ensuite impossible de savoir ce qu’il se passe pour un observateur à l’extérieur ; ils pourraient se retrouver sur un compte Gmail sans que vous le sachiez. Rassurez-vous, chez Next les emails sont bien gérés et stockés en interne chez oui.do (moji), dans leurs datacenter à Nanterre.
La gestion des enregistrements MX est donc un enjeu fort quand il s’agit de parler de souveraineté numérique. Problème, beaucoup d’entreprises, start-ups et institutions françaises utilisent encore massivement Google et dans une moindre mesure Microsoft comme point d’entrée des emails.
SPF, DKIM et DMARC : le trio de la sécurité des emails
Terminons enfin avec un point que nous avions déjà abordé il y a quelques années, mais qu’il est bon de rappeler quand on parle email. Il est possible d’ajouter des couches de sécurité avec DKIM, SPF et DMARC, notamment pour éviter que des petits malins ne changent l’expéditeur sans se faire remarquer.
Le Sender Policy Framework (SPF) « permet au serveur qui reçoit un e-mail de s’assurer que ce dernier a bien été envoyé depuis un serveur de confiance », explique OVHcloud. Si vous recevez un email provenant du domaine exemple.com, le SPF permet de vérifier que le serveur est bien autorisé à envoyer des emails au nom de exemple.com.
Avec SPF, on peut donc vérifier que l’email provient d’un serveur autorisé, mais rien de plus. N’importe qui pouvant envoyer des emails en @next.ink pourrait se faire passer pour une autre personne de @next.ink. Pour s’assurer que l’expéditeur du message est, lui aussi, autorisé, un autre protocole existe : DKIM ou DomainKeys Identified Mail.
Il permet « aux propriétaires de domaines de signer automatiquement « les courriels » provenant de leur domaine, tout comme la signature d’un chèque permet de confirmer l’identité de son auteur », explique Cloudflare. DKIM utilise un chiffrement asymétrique : une clé publique sur le serveur email et une clé privée utilisée par l’expéditeur pour signer l’en-tête de l’email.
« Les serveurs de messagerie qui reçoivent le courrier électronique peuvent vérifier que la clé privée de l’expéditeur a été utilisée en appliquant la clé publique », détaille Cloudflare. Un point important : la vérification de l’expéditeur est de la responsabilité du serveur email rattaché au nom de domaine de l’expéditeur, c’est à lui que revient la charge de s’assurer que l’utilisateur qui envoie l’email est le bon. Comme les utilisateurs doivent s’identifier, cela n’est généralement pas un problème.
Enfin, DMARC (Domain-based Message Authentication Reporting and Conformance) défini ce que doit faire un serveur de messagerie en fonction des résultats de la vérification SPF et DKIM. On parle de « politique DMARC » qui peut être de refuser en bloc les messages échouant aux tests SPF et/ou DKIM, les mettre en quarantaine ou tout simplement les accepter. Oui, un message peut louper son test SPF, échouer à DKIM et arriver tout de même dans votre boite de réception, la fleur au fusil.
La Société des Auteurs et Compositeurs Dramatiques (SACD) assigne TikTok en référé devant le Tribunal judiciaire de Paris pour violation de droits d’auteur.
En jeu : des dialogues, des extraits de films allant d’« OSS 117 » à « Petit Ours Brun », des spectacles d’humoristes…
« Après quatre ans de discussions avortées », pendant lesquelles la plateforme a utilisé « des œuvres protégées du répertoire de la SACD sans aucune autorisation et en n’ayant jamais proposé de contreparties acceptables », la SACD a décidé de porter l’affaire en justice.
Elle déclare TikTok « en position de contrefaçon » et demande « réparation du préjudice subi par les auteurs et autrices des œuvres exploitées ».
La procédure est transmise en Irlande, où se situe le siège européen de TikTok Technology Limited. D’après la SACD, l’audience française est fixée au 18 mars 2026.
Google poursuit son offensive en direction du marché entreprise avec le lancement de Cameyo, une solution de virtualisation permettant d’utiliser des clients lourds au sein de son navigateur Web Chrome ou du système d’exploitation dérivé de ce dernier, ChromeOS.
Légers, endurants et abordables, les ordinateurs Chromebook de Google souffrent d’une limitation inhérente à leur système d’exploitation, dérivé du navigateur Chrome : l’impossibilité d’exécuter nativement des logiciels conçus pour Windows. Une carence que pallient les solutions de type VDI (Virtual Desktop Interface) ou DaaS (Desktop as a Service), qui tirent parti de la virtualisation pour proposer l’accès, en local, à un environnement exécuté dans le cloud.
Virtualiser l’app plutôt que l’environnement
Mais pourquoi virtualiser une instance complète de Windows quand on peut se contenter de simplement exécuter à distance une application ? C’est ce constat qui a motivé, en juin 2024, le rachat par Google de l’éditeur spécialisé Cameyo.
Fondée en 2010 aux États-Unis, cette entreprise explore en effet une approche plus ciblée, dite VAD, pour Virtual Application Delivery, qui consiste donc à ne virtualiser qu’un seul logiciel, par opposition à un système d’exploitation. Cameyo a d’abord travaillé sur des exécutables combinant l’application ciblée et l’environnement nécessaire à sa virtualisation, avant d’embrasser la vague du cloud et de travailler à l’intégration au sein du navigateur Web.
C’est dans ce contexte que Cameyo s’est progressivement rapprochée de Google, pour proposer la mise à disposition de clients lourds Windows au sein de Chrome et de ChromeOS. Les deux entreprises ont notamment collaboré autour de la prise en charge, par Cameyo, du système de fichiers local de ChromeOS, du presse-papier et de la capacité à délivrer les applications virtualisées sous forme de PWA (Progressive Web Apps).
Suite au rachat, Cameyo a disparu des radars pendant plusieurs mois, et fait désormais son retour sous forme d’une offre intégrée au catalogue des solutions entreprises de Google.
« Avec Cameyo by Google, toutes vos applications sont plus faciles à déployer et à gérer, et aussi plus sécurisées. Vos collaborateurs peuvent accéder à leurs applications habituelles où qu’ils se trouvent, sans aucune formation supplémentaire. En transférant tout votre travail sur le Web, vous avez toutes les cartes en main pour relever les défis de demain », vante le moteur de recherche.
Un lancement opportun
Google avance trois avantages principaux : une sécurité accrue, grâce à la séparation entre l’appareil et l’application employée (principe du Zero Trust), un coût total de possession (TCO) réduit dans la mesure où la virtualisation intervient sur un périmètre plus restreint, et un confort accru pour l’utilisateur final, qui peut par cet intermédiaire accéder à ses applications métier directement dans son navigateur. À ces arguments s’ajoutent bien sûr les potentielles économies engendrées par le passage d’un parc de machines Windows à des Chromebook ou autres ordinateurs équipés des outils logiciels de Google.
« Contrairement aux écosystèmes d’entreprise tout ou rien, la suite Google pour entreprises ne vous oblige pas à abandonner vos investissements existants au nom de la modernisation. Au contraire, elle vous offre la liberté de moderniser les différentes couches de votre infrastructure à votre rythme, en fonction des besoins de votre entreprise, tout en conservant l’accès à vos investissements technologiques existants », promet l’éditeur.
Cameyo est présentée comme la brique manquante dans l’éventail des solutions dédiées au poste client de la suite des outils maison – crédit Google
Le calendrier est sans doute propice au retour de Cameyo. D’un côté, la fin du support de Windows 10 et la politique commerciale de Microsoft autour du support étendu suscitent de nombreuses critiques. De l’autre, Google Workspace occupe déjà des positions significatives sur le marché entreprise, en se présentant très directement comme une alternative à Microsoft 365 et à la messagerie Exchange. Google a par ailleurs le champ libre pour avancer ses pions sur le marché de la virtualisation dédiée à ChromeOS, puisque le développement de Parallels Desktop pour ChromeOS a été arrêté, avec une fin de support programmée au 21 avril 2026.
Google ne communique à ce stade aucun prix public relatif à l’offre de virtualisation Cameyo.
La Coimisiún na Meán (Commission des médias) irlandaise a annoncé ce 12 novembre l’ouverture d’une enquête contre le réseau social d’Elon Musk, X.
La plateforme est soupçonnée d’enfreindre le règlement européen sur les services numériques (DSA), notamment parce qu’elle n’offrirait pas à ses usagers la possibilité de faire appel des décisions de modération, comme l’y oblige l’article 20 du règlement.
X est sous le coup d’une autre enquête, ouverte par la Commission européenne fin 2023, pour son rôle dans la gestion et la diffusion de désinformation.
Cette enquête est la première ouverte par l’institution irlandaise dans le cadre du DSA. Elle fait suite à une plainte d’utilisateurs et à la fourniture d’informations supplémentaires par l’ONG HateAid.
Si le régulateur irlandais constate qu’une grande plateforme numérique contrevient au texte, il peut la condamner à une amende susceptible de grimper jusqu’à 6 % de son chiffre d’affaires annuel.
Face aux enjeux de manipulation de l’information et de désinformation, la Commission européenne présente un « bouclier de la démocratie ». Des ONG comme Reporters Sans Frontières appellent à aller plus loin.
Sauvegarder l’« intégrité de l’espace d’information », « renforcer nos institutions, des élections justes et libres, et des médias libres et indépendants » et « renforcer la résilience de la société et l’engagement des citoyens », tels sont les trois piliers du « bouclier de la démocratie »présenté ce 12 novembre par la Commission européenne.
Autonomiser des démocraties « fortes et résilientes »
En jeu : déployer une série de mesures pour « autonomiser, protéger et promouvoir des démocraties fortes et résilientes » dans un contexte de « pressions internes et externes » sur les démocraties. « Alors que la démocratie consiste à mêler différentes voix de la société et à trouver des solutions communes, des régimes autoritaires cherchent à créer et agrandir les divisions, instrumentaliser les conflits, discréditer les acteurs démocratiques, en particulier les médias libres et la société civile, tout en affaiblissant les élections libres et équitables. »
Citant directement la Russie parmi les acteurs de ce type d’ingérence accroissant la désinformation et manipulant l’information disponible dans le débat public, la Commission se penche aussi sur l’émergence de technologies comme l’intelligence artificielle, susceptible « d’affecter sévèrement l’espace démocratique, processus électoral compris ».
La percée surprise du candidat d’extrême droite Călin Georgescu, après une intense campagne menée sur TikTok, lors de l’élection présidentielle roumaine de 2024, ou encore les manipulations constatées en amont de l’élection moldave sont, de nouveau, citées comme exemples des effets de ces opérations.
Divers outils législatifs préexistants, dont la directive NIS2 et le règlement cyber-résilience, transposés en septembre, le règlement sur la publicité politique, ou encore les règlements sur les services et les marchés numériques sont cités comme outils de cette défense démocratique.
En lien avec les récents textes sur les plateformes numériques, la Commission européenne créera un protocole dédié à la gestion de crises, notamment face aux « opérations d’information à grande échelle et potentiellement transnationales ». Ce mode d’action intégrera la gestion des menaces cyber, notamment celles visant la bonne tenue des processus électoraux.
Pour renforcer la société civile, la Commission annonce plusieurs mesures dédiées à développer l’éducation générale autour de « l’esprit critique, l’inclusivité, la liberté d’expression et l’engagement civique actif ». Elle prévoit notamment de muscler son soutien aux médias, notamment aux échelles locales et régionales, où les rédactions disparaissent. Et confirme le soutien financier au programme AgoraEU, doté de neuf milliards d’euros pour promouvoir les différents enjeux cités précédemment au sein de l’Union.
Dès le 10 novembre, Reporters Sans Frontières (RSF) et l’Union européen de radio-télévision (UER) indiquaient ne considérer ce programme que comme une « première étape », qu’ils souhaitent voir déboucher sur des propositions législatives.
Dans une lettre ouverte (.pdf), les deux organisations appellent les législateurs à préserver l’accès des Européens à « des sources d’information fiable », mesure qu’ils n’estiment possible que si l’Europe assure la mise en avant de médias d’intérêt général, oblige les plateformes numériques à accroître leur transparence – et à accentuer la visibilité de ces sources d’information fiable par rapport à celle des contenus de désinformation et de propagande –, et régule les services reposant sur de l’intelligence artificielle.
Trois ans après l’introduction de ChatGPT, leur production d’information continue en effet de présenter des problèmes – que ce soit en termes de faits (erreurs, « hallucinations ») ou de sources de l’information –, un enjeu inhérent à leur fonctionnement.
Dans le procès qui oppose le New York Times à OpenAI, le journal a demandé cet été de pouvoir analyser les logs de l’utilisation de ChatGPT afin de trouver d’éventuelles preuves de violation de copyright.
Ce vendredi 7 novembre, la juge Ona Wang a informé [PDF] les deux parties qu’ « OpenAI est tenu de fournir les 20 millions de logs de ChatGPT anonymisés aux plaignants avant le 14 novembre 2025 ou dans les 7 jours suivant la fin du processus d’anonymisation ».
Photo de Jakayla Toney sur Unsplash
Comme le raconte Reuters, l’entreprise de Sam Altman a répondu [PDF] ce mercredi en se plaignant que « pour être clair : toute personne dans le monde ayant utilisé ChatGPT au cours des trois dernières années doit désormais faire face à la possibilité que ses conversations personnelles soient transmises au Times afin que celui-ci puisse les passer au crible à sa guise dans le cadre d’une enquête spéculative ».
De leur côté, les avocats du journal ont expliqué [PDF] qu’OpenAI a eu trois mois pour anonymiser les données, que l’un des représentants d’OpenAI a reconnu que le processus permettra « d’effacer du contenu les catégories d’informations personnelles identifiables et autres informations (par exemple, les mots de passe ou autres informations sensibles) comme les données utilisateur ». Le journal fait aussi remarquer qu’il doit respecter une ordonnance spéciale protégeant ces données lors de l’inspection de ces logs.
L’entreprise de Sam Altman fait aussi une comparaison avec des affaires ayant impliqué Google en affirmant que « les tribunaux n’autorisent pas les plaignants qui poursuivent Google à fouiller dans les emails privés de dizaines de millions d’utilisateurs Gmail, quelle que soit leur pertinence. Et ce n’est pas non plus ainsi que devrait fonctionner la divulgation dans le cas des outils d’IA générative »
Mais la juge a expliqué qu’ « OpenAI n’a pas expliqué pourquoi les droits à la vie privée de ses consommateurs ne sont pas suffisamment protégés par : (1) l’ordonnance de protection existante dans ce litige multidistrict ou (2) la dépersonnalisation exhaustive par OpenAI de l’ensemble des 20 millions de logs ChatGPT des consommateurs ». Elle semble estimer que les conversations des utilisateurs avec un chatbot ne peuvent pas être considérées comme des conversations privées au même titre que des échanges de courriers ou d’e-mails entre deux personnes réelles.
Nouvelle mouture du principal modèle chez OpenAI. Il est présenté comme plus chaleureux et rapide, plus convivial et personnalisable. Comme toujours, les personnes abonnées l’ont d’abord, avant une diffusion chez les utilisateurs gratuits.
L’entreprise a à cœur de faire oublier les premières semaines du lancement de son GPT-5, présenté en aout comme une étape majeure. Le nouveau LLM s’était rapidement attiré les critiques, à cause de difficultés sur des problèmes simples de logique. Depuis, le tir a été en partie corrigé et OpenAI a lancé Codex, sa réponse à Claude Code.
On savait néanmoins qu’il faudrait des changements structurels plus importants que de petits ajustements. GPT-5.1 est donc disponible depuis ce 12 novembre avec à son bord des améliorations assez prévisibles : plus « convivial et intelligent », plus rapide et plus personnalisable, selon OpenAI. Un nouveau lot de « personnalités » fait son apparition.
Instant, Thinking et Auto dans un bateau
Le modèle préserve les deux variantes du modèle 5. La première, Instant, est faite pour répondre rapidement. Présenté comme « plus ludique et conversationnel », ce modèle est censé fonctionner désormais sur une base de « raisonnement adaptatif », pour décider quand réfléchir avant de donner des réponses complexes. Son évaluation de ces situations serait plus précise.
La seconde version, Thinking, est toujours dédiée au raisonnement. C’est la mouture du modèle la plus aboutie actuellement chez OpenAI, pour les résultats les plus précis, avec comme toujours un temps de traitement plus long. L’outil se veut plus accessible que sa précédente incarnation, en utilisant moins de jargon technique. Lui aussi se veut « plus chaleureux et plus empathique ».
Entre les deux, on retrouve la version 5.1 de GPT Auto, toujours chargé de répartir les requêtes entre les deux variantes du modèle. OpenAI assure que dans la majorité des cas, les utilisateurs n’auront pas besoin de choisir le modèle, le système le faisant seul en fonction du prompt.
On note que l’annonce d’OpenAI ne contient aucun tableau de comparaison de performances sur les différents benchmarks habituels. Seule exception, un graphique montrant que le nouveau modèle passe moins de temps sur les tâches aisées et plus de temps sur les tâches plus complexes. La société le présente dans tous les cas comme « plus performant et utile ». Elle assure également que les instructions personnalisées sont suivies de manière plus efficace.
Le déploiement a commencé
Le déploiement de GPT-5.1 Instant et Thinking a commencé hier soir, d’abord pour les personnes abonnées Pro, Plus, Go et Business. Le déploiement est progressif et se fait sur plusieurs jours. Pour les formules Enterprise et Edu, un accès anticipé de sept jours a été lancé hier soir. Les structures concernées ont un accès garanti et peuvent tester les nouveaux modèles pendant cette période. Après quoi, GPT-5.1 deviendra le seul modèle utilisable.
Il deviendra également le modèle par défaut dans ChatGPT, mais les abonnés payants pourront toujours accéder à la version 5 pendant trois mois. Les utilisateurs gratuits auront aussi la nouvelle version, mais un peu plus tard.
Invité par La Dépêche du Midi à débattre de « la démocratie face aux réseaux sociaux » avec des Français, Emmanuel Macron a avant tout cité son souhait de créer une majorité numérique à 15 ans. Il a esquissé la possibilité de quitter certaines plateformes sociales comme X.
Interrogé sur le rôle des réseaux sociaux, et notamment de X, dans la diffusion de la désinformation, Emmanuel Macron a déclaré « réfléchir » à sortir de ce type de plateforme.
Invité par La Dépêche du Midi à échanger pendant deux heures face à 300 lectrices et lecteurs du journal, le président s’est exprimé sur une variété de sujets liés au numérique, de l’exposition des plus jeunes aux écrans jusqu’au besoin d’imposer la transparence aux principales plateformes numériques. Et de souligner que dans le contexte actuel de désagrégation de l’espace informationnel, « les fondements de notre république et de notre démocratie » sont aujourd’hui menacés.
Minimiser le temps d’écran, majorité numérique à 15 ans
« Toutes nos études montrent que nos enfants, ados, sont de plus en plus perturbés par ces réseaux sociaux ». C’est sur le temps d’exposition aux écrans et l’impact des réseaux sociaux sur les plus jeunes que le président de la République a entamé ses deux heures d’échanges. Alors que le « durcissement de la menace informationnelle » était cité il y a moins d’une semaine dans les murs du Sénat, Emmanuel Macron échangeait sur le thème de « la démocratie à l’épreuve des réseaux sociaux ».
À cette occasion, le président a rappelé la volonté d’interdire les écrans aux enfants de moins de trois ans, et de minimiser l’exposition avant six ans – des décisions préconisées par le rapport dédié qui lui a été remis en 2024, et reprises en juin par la ministre de la Santé et des Solidarités. Sur la question des réseaux sociaux, il est revenu sur les débats menés à l’échelle européenne sur la manière de les réguler. Et a plaidé, comme à son habitude, pour une majorité numérique assortie d’une vérification de l’âge des internautes à 15 ans.
Éviter que « les réseaux sociaux » ne « gagnent la présidentielle »
Interrogé sur la place accordée au docteur Raoult pendant la crise du Covid, Emmanuel Macron pointe le rôle des médias « qui ont relayé ses paroles » et « assume de ne pas avoir eu une décision politique pour l’empêcher », dans la mesure où il revenait à la communauté scientifique d’établir l’invalidité de ses traitements. Rappelons qu’Emmanuel Macron a mis en avant le chercheur en organisant notamment une visite médiatisée de son laboratoire en avril 2020.
Plus largement, le président souligne le « sujet géopolitique » que constitue désormais la désinformation, alimentée comme elle l’est par la Russie, la Chine et diverses autres puissances étrangères. « On doit tout faire pour que ce ne soit pas les réseaux sociaux », ou quelques acteurs « qui ont l’usage le mieux organisé », qui parviennent à « gagner la présidentielle ». Et le président de déclarer « réfléchir » à quitter certains réseaux, à commencer par X.
En termes de régulation, Emmanuel Macron estime que l’objectif est de créer « une économie pour qu’il y ait de la transparence ». Autrement dit : ne pas interdire, mais obliger les plateformes à partager leurs données et leurs algorithmes, comme le règlement européen sur les services numériques s’y emploie, pour permettre aux chercheurs et auditeurs agréés d’aider le public à mieux comprendre le fonctionnement de ces outils.
Interrogé sur la concentration des médias traditionnels dans les mains d’une poignée de milliardaires, il souligne aussi que « c’est un problème », conséquence « d’un modèle économique en crise ». En conclusion, interrogé avant tout sur les mesures à prendre pour protéger la jeunesse, Emmanuel Macron réitère son souhait de voir advenir une majorité numérique à 15 ans et sur la nécessité de former de manière « renforcée à l’esprit critique » — formation qui intégrerait, selon ses dires, divers enjeux de cultures numériques, allant de la compréhension du fonctionnement d’Internet à celui de l’intelligence artificielle.
En 2024, Apple présentait son Private Cloud Compute. L’idée était de ne déporter dans le cloud que les requêtes LLM les plus complexes (les autres fonctionnant en local) pour les exécuter dans un environnement dédié, fonctionnant sur des puces maison et bardé de protections pour que les échanges soient privés. Apple avait décrit les grandes lignes de sa sécurité.
Ce 11 novembre, Google a annoncé un programme similaire, nommé Private AI Compute. Un nom calqué sur celui d’Apple qui renvoie à des caractéristiques pratiquement identiques (pdf) : utilisation des puces TPU maison, enclave sécurisée équivalente à celle des téléphones (Titanium Intelligence Enclaves), préservation de la confidentialité des échanges, utilisation des mêmes modèles (Gemini), etc.
Le discours est lui aussi le même : aujourd’hui, de nombreuses opérations sont réalisées localement, mais la puissance manque rapidement quand la requête devient plus complexe. Puisqu’une exécution entièrement locale n’est pas possible, autant envoyer les requêtes dans un « espace sécurisé et fortifié », « tout en veillant à ce que vos données personnelles restent privées et ne soient accessibles à personne d’autre, pas même à Google », promet l’entreprise.
Le fait de lancer une telle initiative va cependant plus loin que de reprendre l’idée d’Apple : en l’adoptant, Google valide la démarche de l’entreprise de Cupertino, alors même que celle-ci semble pour l’instant très en retard. Certaines rumeurs récentes ont évoqué des réunions entre Apple et Google, afin que la première utilise les LLM de la seconde. Le résultat serait alors équivalent côté utilisateur : des modèles Gemini et une architecture très similaire, avec chiffrement et couches multiples de protection.
Le Private AI Compute de Google est déjà actif. Magic Cue, responsable des suggestions contextuelles sur la gamme Pixel 10, l’utilise par exemple. Même chose pour Recorder, dont le résumé des transcriptions peut être appliqué à un plus grand nombre de langues. Gemini Nano reste utilisé pour les opérations locales, mais à la manière d’Apple l’année dernière, Google ne dit pas précisément comment la bascule s’opère.
L’un des tribunaux régionaux de Munich s’est prononcé ce mardi 11 novembre en faveur du lobby de l’industrie musicale allemande GEMA dans une affaire l’opposant à OpenAI.
Le jugement concerne l’utilisation des paroles de chansons de neuf auteurs allemands connus, dont « Atemlos » de Kristina Bach et le fameux « Wie schön, dass du geboren bist » de Rolf Zuckowski.
La cour donne raison à la GEMA, autant sur « la mémorisation dans les modèles linguistiques » des paroles que leur reproduction dans les résultats du chatbot : les deux, selon elle, constituent des atteintes des droits d’exploitation du copyright. Ces utilisations « ne sont couvertes par aucune limitation [du copyright] et notamment pas par la limitation relative à la fouille de données et de textes », commente le tribunal dans son communiqué.
« La chambre estime que les paroles litigieuses sont reproduites dans les modèles linguistiques 4 et 4o », explique-t-il.
Le tribunal considère qu’une « perception indirecte » de la mémorisation dans les modèles linguistiques est un indice suffisant pour la démontrer en se fondant sur la jurisprudence de la Cour de justice de l’Union européenne (CJUE). En l’occurence, le fait que ChatGPT a « rendu accessibles au public les paroles des chansons » est considéré comme une preuve indirecte de cette mémorisation en plus d’être une preuve directe de leur reproduction dans ses résultats.
« Nous sommes en désaccord avec la décision, et nous étudions les prochaines démarches possibles », a déclaré OpenAI à l’AFP. L’entreprise souligne également que le jugement ne concernerait que les textes qui figurent dans la plainte de la GEMA.
C’est « une victoire historique pour la GEMA », selon le cabinet d’avocats qui l’accompagne. « C’est la première fois qu’un tribunal allemand confirme que les entreprises d’IA ne peuvent pas utiliser des contenus protégés par le copyright ». « Cette décision rendue à Munich apporte une sécurité juridique aux professionnels de la création, aux éditeurs de musique et aux plateformes dans toute l’Europe, et elle est susceptible de créer un précédent dont l’impact s’étendra bien au-delà des frontières allemandes », ajoutent les représentants du lobby musical allemand.
Le tribunal n’a pas donné les détails des dédommagements que devra verser OpenAI.
Comment faire face à la chute des pages vues, que Wikipedia met sur le compte du développement de l’IA générative ?
La fondation Wikimedia a la solution : dans une publication du 10 novembre, elle appelle les développeurs d’IA à recourir à ses ressources de manière « responsable », en créditant leur source et en soutenant le projet contributif financièrement.
« Les humains apportent à la connaissance des éléments que l’IA ne saurait remplacer », indique la fondation qui fournit l’infrastructure technique pour permettre à des communautés de wikipédiens et wikipédiennes d’alimenter bénévolement les encyclopédies de leurs langues respectives.
Pour permettre au projet de se perpétuer, la fondation appelle donc les créateurs d’IA génératives à citer leurs sources humaines – et Wikipedia, lorsque les contenus ayant servi à alimenter leurs machines viennent de là.
D’après la fondation, « pour permettre à la population d’avoir confiance en l’information partagée sur internet, les plateformes devraient rendre les sources de leurs informations évidentes et promouvoir le fait de visiter et de participer à ces sources ».
Elle incite aussi les constructeurs à se tourner vers son API payante, disponible depuis la plateforme Wikimedia Entreprise, ce qui permet d’utiliser le contenu de l’encyclopédie « à grande échelle et de manière durable sans surcharger les serveurs de Wikipédia », tout en soutenant financièrement ses activités.
La Commission européenne a proposé d’affaiblir rapidement le RGPD au profit des entreprises d’IA. Les pays membres semblent vouloir une discussion plus longue sur le sujet, même si l’Allemagne inspire la proposition de la Commission.
Une petite bombe a été lâchée la semaine dernière avec la fuite d’un brouillon de la Commission européenne de la loi « omnibus numérique » prévoyant d’affaiblir le RGPD au profit des entreprises d’IA. Elle doit officiellement le présenter le 19 novembre prochain et le texte peut encore changer d’ici là.
L’association noyb de Max Schrems, qui y est totalement opposée, a publié [PDF] les positions de neuf pays sur la « simplification » du RGPD rendues avant la fuite du brouillon.
L’Allemagne pour des changements en profondeur… mais avec des discussions en amont
L’Allemagne plaidait pour une vaste révision du règlement mais sans que la loi « omnibus numérique » qui doit entrer en discussion d’ici peu en soit le vecteur le plus significatif. Berlin considère que les discussions autour du sujet méritent du temps.
« Afin d’ajuster l’équilibre entre les droits fondamentaux des personnes concernées et les droits fondamentaux des citoyens et des entreprises à traiter des données à caractère personnel (notamment la liberté d’information, la liberté des sciences, la liberté d’exercer une activité commerciale), toute modification du RGPD, tout en garantissant un niveau adéquat de protection des données et en préservant les principes fondamentaux du RGPD, devrait être examinée avec soin et mise en œuvre de manière ciblée, précise et fondée sur les risques », affirmait l’Allemagne.
Mais, pour noyb, « il semble que la Commission se soit simplement « emparée » » de cette position non-officielle de l’Allemagne pour établir sa proposition d’un affaiblissement du RGPD exprimée dans le brouillon de l’ « omnibus numérique » , « étant donné que de nombreux changements apportés au projet semblent être une copie conforme des demandes formulées dans la lettre allemande qui a fuité », affirme l’association de Max Schrems.
La France et sept autres pays de l’UE pour des changements à la marge
De leurs côtés, les huit autres pays qui se sont exprimés (la République tchèque, l’Estonie, l’Autriche, la Pologne, la Slovénie, la Finlande, la Suède et la France) ne pressent pas pour un changement majeur du texte. Si aucun d’entre eux ne nie le besoin de clarification de certains points dans le règlement européen, notamment pour faciliter la mise en conformité des entreprises, une bonne partie d’entre eux souligne, à l’instar de la République tchèque, la nécessité que cela reste « compatible avec la protection effective des droits fondamentaux ».
Prague voit surtout des modifications à la marge comme la possibilité pour les responsables du traitement de ne pas « déployer des efforts disproportionnés » pour fournir des informations lorsqu’une personne lui demande, comme l’article 15 du règlement le prévoit, si certaines de ses données à caractère personnel sont ou ne sont pas traitées. La Suède propose aussi des changements à la marge comme un relèvement du seuil pour lequel les entreprises doivent notifier la violation de données personnelles.
Quant à la France, elle jugeait qu’ « à ce stade, les retours des parties prenantes collectés par la Commission ont montré qu’elles ne souhaitaient pas d’une réouverture du RGPD » et que « les autorités françaises se sont également exprimées en ce sens et maintiennent cette position ». Comme les sept autres pays, elle estimait que « pour atteindre un équilibre optimal entre les enjeux d’innovation et la protection des libertés fondamentales, les efforts de mise en œuvre du texte doivent se poursuivre ». Par contre, Paris appelle « le CEPD [Contrôleur européen de la protection des données] et les autorités de protection des données à mener rapidement des consultations des acteurs sur les sujets prioritaires que sont l’articulation du RGPD avec le règlement sur l’intelligence artificielle (RIA), la pseudonymisation et l’anonymisation, dans les semaines qui viennent ». La France estime qu’ « il s’agit d’une attente très forte pour que les besoins concrets puissent être exprimés en amont de la finalisation du premier jet des lignes directrices sur ces sujets ».
De son côté, Max Schrems réitère ses critiques sur le projet : « Le brouillon n’est pas seulement extrême, il est également très mal rédigé. Il n’aide pas les « petites entreprises », comme promis, mais profite à nouveau principalement aux « grandes entreprises technologiques » ». noyb s’est joint à l’Edri et à l’organisation irlandaise Irish Council for Civil Liberties pour envoyer une lettre ouverte [PDF] à la Vice-présidente exécutive de la Commission européenne à la Souveraineté technologique, à la Sécurité et à la Démocratie, Henna Virkkunen. Dans ce texte, les trois associations affirment que les changements « considérables » prévus par le brouillon « priveraient non seulement les citoyens de leurs droits, mais compromettraient également la compétitivité européenne ».
Fin d’une ère, pour Facebook. Le 10 février 2026, deux de ses plugins externes, le bouton J’aime et le bouton Partager seront jetés aux oubliettes.
Lancés en 2010, ces deux outils avaient largement participé à alimenter les échanges sur Facebook, en simplifiant la promotion et le partage commenté d’articles et de liens divers.
D’après l’entreprise, cela dit, ces outils « représentent une époque antérieure du développement du web, et leur usage a décru naturellement à mesure que le paysage numérique évoluait ».
Pour pallier cet usage déclinant, Meta annonce donc qu’à compter du 10 février 2026, ces dispositifs seront transformés en un pixel 0x0, ce qui rendra les boutons invisibles sur les sites les utilisant, « sans créer de message d’erreur ni abîmer de fonctionnalité ».
S’il n’a pas été inventé par Facebook, le bouton J’aime a largement modifié notre rapport au web. Initialement ajouté sur des sites comme Yelp ou, donc, Facebook, pour motiver les internautes à produire du contenu et le partager, il a ensuite été détourné de cet usage initial pour se transformer en métrique des pratiques numériques à collecter, pour mieux vendre de la publicité.
La question du traitement des données personnelles était remontée jusqu’à la Cour de Justice de l’Union Européenne. En 2019, elle avait conclu que l’éditeur d’un site pouvait être responsable avec Facebook d’une partie des traitements de données personnelles orchestrés par le bouton « J’aime ». Celui-ci permettait à Facebook de récupérer des données même si l’internaute ne cliquait pas dessus ou n’était pas abonné.
Si l’outil extérieur aux plateformes de Meta disparaît, les emojis « j’aime », « j’adore » , « soutien » , « colère » (lancés en 2016) et autres restent bien présents à l’intérieur des réseaux sociaux de l’entreprise.
Douze ans après son arrivée au sein de ce qui s’appelait à l’époque Facebook, le chercheur français Yann LeCun s’apprête à quitter l’entreprise de Mark Zuckerberg, devenue depuis Meta.
Arrivé en 2013 pour créer et diriger le laboratoire de recherche et développement de l’entreprise Facebook Artificial Intelligence Research (FAIR), le chercheur a amené à Facebook puis Meta ses connaissances sur le deep learning dont il est l’un des pionniers. Ainsi, le FAIR a permis à Facebook d’être l’un des premiers réseaux sociaux à intégrer des systèmes d’intelligence artificielle, notamment pour la reconnaissance faciale.
Mais la récente reprise en main des recrutements sur l’IA par Mark Zuckerberg semble avoir donné une direction que le Français ne veut pas suivre. En effet, depuis cet été le CEO de Meta a redirigé toutes les forces de R&D dans la création d’un laboratoire dédié à la « superintelligence » en s’appuyant sur les modèles génératifs dérivés des LLM. Il a débauché des spécialistes chez Apple, Anthropic, OpenAI ou Scale AI et misé sur Alexandr Wang pour la direction de la R&D. Mark Zuckerberg veut pousser ses chercheurs à creuser cette voie et sortir plus de modèles qui doivent alimenter en IA plus rapidement les produits de Meta.
Ce choix, selon le Financial Times, aurait poussé Yann LeCun à quitter l’entreprise en vue de fonder sa propre startup. En effet, s’il soutient que les LLM sont « utiles », il pense qu’ils ne seront jamais capables ni de raisonner ni de planifier comme les humains. Il pousse donc, au sein du laboratoire de Meta, le travail sur ce que les chercheurs en IA appellent les « world models », des modèles capables de conceptualiser un monde, comme l’ont proposé en 2018 les chercheurs David Ha et Jürgen Schmidhuber. Ceci permettrait d’intégrer de véritables robots dans le monde réel.
Ainsi, Meta a travaillé sur plusieurs séries d’architectures : JEPA, V-JEPA, DINO-WM et PLDM. Mais ceux-ci en sont encore aux débuts de la recherche sur le sujet et subissent des critiques. Par exemple, tout en admettant que V-JEPA 2 « marque une avancée » sur des tâches de manipulation de bras robotiques, des chercheurs doutent de ses capacités sur « des tâches plus diverses (par exemple, préparer le petit-déjeuner) ou adaptées à des environnements plus complexes avec des dépendances à long terme (par exemple, l’alpinisme) ».
Le chercheur français semble vouloir continuer dans cette voie en montant sa propre startup.
La nouvelle mouture du navigateur est assez riche en nouveautés. Elle introduit notamment la possibilité d’ajouter, modifier et supprimer des commentaires dans les documents PDF. Elle permet également de prévisualiser les onglets présents dans un groupe en survolant le nom de ce dernier avec la souris, la liste s’affichant alors.
D’autres ajouts pratiques font leur apparition. Par exemple, la barre latérale permet de gérer les mots de passe, qui ne nécessitent donc plus l’ouverture d’un nouvel onglet ou d’une nouvelle fenêtre. À la manière de ce que pratiquent certains moteurs de recherche comme Google, Firefox permet maintenant de « Copier le lien du surlignage » depuis un clic sur un passage surligné. On peut alors coller un lien modifié vers la page qui affichera le passage en question chez les personnes qui le recevront.
On trouve aussi de nouveaux fonds d’écran (en versions claires et sombres), une option pour ouvrir un onglet depuis une app tierce dans un onglet à côté de l’onglet actif plutôt qu’à la fin, des onglets horizontaux légèrement plus arrondis (pour une plus grande cohérence avec le style vertical), l’utilisation de Zstandard pour la compression des modèles linguistiques de traduction afin de réduire le poids et la consommation d’espace disque, ou encore une simplification de l’installation des agents tiers.
Firefox 145 introduit en outre un renforcement des protections pour la vie privée, d’abord en activant l’Enhanced Bounce Tracking Protection par défaut quand on navigue en mode strict. Ensuite, toujours dans ce mode ou quand on se trouve en navigation privée, Firefox détecte un plus grand nombre de signaux récupérés pour rendre un(e) internaute unique pour les bloquer.
Comme la fondation l’indique dans un billet dédié, ces nouvelles protections sont déployées par phase et ne sont pas disponibles par défaut chez tout le monde. « Nos recherches montrent que ces améliorations ont réduit de près de moitié le pourcentage d’utilisateurs considérés comme uniques », affirme Mozilla. L’éditeur ajoute que la progression de ces outils est complexe, car de nombreux cas d’utilisation présentent des raisons légitimes de demander l’accès à certaines informations, par exemple le fuseau horaire pour les services d’agendas.
Enfin, Firefox 145 est la dernière version à prendre en charge les systèmes Linux 32 bits, comme prévu. Le navigateur corrige en outre 16 failles de sécurité, dont 9 critiques.