☕️ Flock : Personne n’aime le changement de Windows
Il parait que la solution viendra du libre ! Mais il y en a peut-être bien pour cinq ans avant ça…

Il parait que la solution viendra du libre ! Mais il y en a peut-être bien pour cinq ans avant ça…
Ce n’est pas le genre d’information que l’on lit tous les jours : le site officiel d’une distribution Linux a été détourné par des pirates pour lui faire distribuer un malware destiné à Windows.
En l’occurrence, il s’agit du site de Xubuntu, la variante Xfce d’Ubuntu. Le bouton de téléchargement renvoyait vers un fichier torrent aboutissant à un fichier Zip. À l’intérieur, un fichier .exe contenant un malware au fonctionnement désormais classique : l’interception des liens menant à des comptes de cryptomonnaies s’ils sont envoyés dans le presse-papiers.
Sur Mastodon, le responsable de Xubuntu, Sean Davies, a confirmé le problème, donnant du même coup une idée de l’origine : « Nous travaillons avec Canonical pour résoudre le problème. Étant donné que les serveurs n’appartiennent pas à notre équipe, nous ne pouvons pas faire grand-chose. Depuis, nous avons supprimé la page de téléchargement et nous allons accélérer le développement de notre site statique pour remplacer notre instance WordPress vieillissante ».

Il semble que le malware soit resté en ligne pendant tout ou partie du week-end du 18 - 19 octobre, comme pointé. Dans un message publié dimanche sur Reddit par Elizabeth Krumbach Joseph, membre de l’équipe Xubuntu, on apprenait que l’incident était en cours de résolution. À l’heure où nous écrivons ces lignes cependant, le site officiel renvoie toujours vers une erreur 503 pour la page des versions, tandis que le lien de téléchargement direct pour la mouture 24.04 sur la page d’accueil ne déclenche aucune action.
Comme le signale OMGUbuntu, on ne sait pas combien de personnes ont pu être infectées, ou même s’il y a des victimes. Récupérer un Zip quand on s’attend à une image ISO (ces dernières sont intactes) a de quoi rendre méfiant. Tout comme le nom du fichier : Xubuntu-Safe-Download.zip.
Cependant, le piratage a eu lieu durant le premier week-end suivant la fin de support de Windows 10. Si des utilisateurs Linux sont venus télécharger l’image ISO de Xubuntu, un fichier Zip contenant un exécutable Windows n’a pas pu leur faire de mal. En revanche, si des personnes sous Windows sont venues tester la distribution, elles ont pu penser qu’il s’agissait d’un programme simplifiant le téléchargement et l’installation du système.
En attendant la réparation du site officiel de Xubuntu, les images ISO peuvent être téléchargées depuis le serveur d’Ubuntu.
En mai dernier, nous prenions en main AnduinOS. Cette distribution sans grande prétention se proposait de reprendre une base Ubuntu et de lui adjoindre un bureau aussi proche que possible de Windows 11. Objectif affiché : faciliter autant que possible les transitions pour les personnes intéressées. Elle a été créée par Anduin Xue, ingénieur chez Microsoft travaillant presque exclusivement sur Linux. Il s’agit en revanche d’un projet personnel, non affilié à l’entreprise.
Une mouture 1.4 du système est sortie le 17 octobre. Malgré le peu d’évolution dans le numéro de version, les changements sont profonds. Ils s’articulent principalement autour de la base technique, qui passe d’Ubuntu 25.04 à 25.10, avec un noyau Linux 6.17 et GNOME 49.

La version ajoute également trois extensions gnome-shell pour élargir la bascule automatique de la couleur d’accentuation dans les applications, un mode « Anduin To Go » pour les installations sur clés USB, ainsi qu’une uniformisation du nom et du logo associé au sein du système. On notera aussi le remplacement de Firefox par sa variante ESR pour éviter le paquet snap associé.
Anduin Xue précise que si la mise à jour est techniquement possible entre AnduinOS 1.3 et 1.4, elle n’est pour l’instant pas recommandée, à cause des profonds changements techniques introduits. Dans son billet d’annonce, il ajoute qu’un script dédié sera fourni dans les deux mois. « Nous nous engageons à n’abandonner aucun utilisateur de la version 1.3 et nous les aiderons finalement à passer à la version 1.4 de manière sûre et fiable. Ce plan devrait être entièrement mis en œuvre d’ici janvier 2026 au plus tard », explique le développeur.

Dans l’objectif d’une harmonisation continue et d’une réduction de la consommation, l’Union européenne vient de mettre à jour ses règles d’écoconception pour les chargeurs USB-C et sans fil. Les constructeurs ont jusqu’en 2028 pour se préparer, avec à la clé des économies attendues loin d’être anodines.
Le texte, publié le 13 octobre par la Commission européenne, est une extension significative de l’actuel règlement sur les chargeurs. La nouvelle législation est beaucoup plus ambitieuse, car elle généralise les règles d’écoconception à un plus grand nombre de cas de figure, loin des seuls domaines mobiles comme les smartphones et tablettes.
Sont ainsi concernées de nombreuses catégories de produits, dont les ordinateurs portables, les écrans d’ordinateurs, les routeurs et autres bornes Wi-Fi, les batteries externes et bon nombre de produits ménagers. En clair, tout ce qui se recharge à l’aide d’un chargeur dont la puissance n’excède pas 240 watts. Il y a toutefois des exceptions, dont tout ce qui fonctionne en conditions humides, les jouets, aspirateurs, la plupart des outils électriques et équipements audio. En tout, la Commission estime que ce sont pas moins de 400 millions de nouveaux chargeurs qui sont achetés chaque année dans l’Union, qu’ils soient fournis avec les produits ou achetés séparément.
« Avoir des chargeurs communs pour nos smartphones, ordinateurs portables et autres appareils que nous utilisons tous les jours est une décision intelligente qui donne la priorité aux consommateurs tout en réduisant le gaspillage d’énergie et les émissions. Le changement concret que nous introduisons aujourd’hui dans le domaine de l’approvisionnement externe en énergie aidera les Européens à économiser de l’argent tout en réduisant notre impact environnemental, et prouve que l’innovation peut être à la fois source de progrès et de responsabilité », a déclaré à cette occasion Dan Jørgensen, commissaire européen chargé de l’énergie et du logement.
Rappelons que ce règlement vient compléter d’autres déjà disponibles depuis quelques années, notamment celui entré en vigueur fin 2024 pour consacrer l’USB-C comme port de recharge universel, notamment sur les smartphones, tablettes et ordinateurs portables. Il est également en phase avec les nouvelles étiquettes énergie obligatoires depuis juin dernier.
Avec le nouveau texte, l’Union européenne réclame désormais des exigences minimales pour tous les chargeurs, nommés EPS dans le texte pour External Power Supplies. Pour l’ensemble des produits concernés, les chargeurs filaires devront obligatoirement proposer un port USB-C accompagné d’un câble détachable. Dans le cas d’une panne de l’un ou de l’autre, il faut pouvoir le remplacer séparément. Les câbles eux-mêmes devront afficher leur puissance nominale de 60 ou 240 W.
Comme indiqué, la puissance maximale sera de 240 watts, correspondant au maximum de l’actuelle norme Power Delivery, comme nous l’avions expliqué au printemps dernier. Les exigences se font également plus strictes sur l’efficacité énergétique. Par exemple, la consommation à vide (quand le chargeur est branché mais inutilisé) ne devra pas excéder 0,3 W.
En outre, tous les chargeurs fonctionnant entre 10 et 240 W devront afficher une meilleure efficacité énergétique (rendement) pour mieux contrôler les déperditions d’énergie. Le règlement réclame également une meilleure efficacité en puissance de charge partielle, plus spécifiquement à 10 % de la puissance nominale. Tous les détails se trouvent dans la première annexe.
Les chargeurs sans fil sont également abordés. La Commission note qu’ils consomment davantage que les chargeurs filaires, mais eux aussi devront se montrer plus efficaces, notamment vis-à-vis de leur popularité grandissante.
Pour marquer la séparation entre les chargeurs compatibles avec les nouvelles exigences et les anciennes générations, un logo « EU Common Charger » devra être affiché sur les boites et les chargeurs.
À noter que le texte fait également rentrer les chargeurs de plus de 250 W dans le giron du règlement européen de 2019 sur l’écoconception. Pour ces modèles plus puissants et moins nombreux, que le nouveau règlement ne prend pas directement en compte, la Commission estime qu’ils devraient être « alignés avec les régulations et standards internationaux ».
La nouvelle réglementation sera publiée au Journal officiel « dans les semaines à venir » de l’Union européenne, puis entrera en vigueur 20 jours après.
À compter de là, les constructeurs auront trois ans pour s’y faire, car l’entrée en application interviendra fin 2028. Comme on l’a vu, les points de contrôle seront nombreux, mais l’ensemble devrait concourir à faire baisser les déchets électroniques et la consommation générale.
On peut donc s’attendre à une généralisation de certains comportements, comme chez Apple avec les derniers MacBook Pro M5, qui ne sont plus fournis avec le chargeur. Pour d’autres constructeurs qui n’auraient pas commencé à se pencher sur le sujet, il faudra modifier les chaines de production. À terme, la possession d’un ou plusieurs de ces chargeurs devrait effectivement se traduire par une réduction des déchets.
Quels sont les effets attendus par la Commission ? D’ici 2035, elle attend des économies annuelles de 3 % de la consommation d’énergie sur le cycle des alimentations externes, « ce qui correspond à l’énergie utilisée en un an par environ 140 000 voitures électriques » selon la Commission. Sur ce même cycle, les émissions de gaz à effet de serre devraient baisser de 9 % et les émissions de polluants de 13 %. Financièrement, le changement se traduirait par des économies de 100 millions d’euros par an dans l’Union à compter de 2025, par le réemploi des chargeurs déjà possédés.
Surtout, la Commission s’attend à ce que la normalisation stricte de tous les chargeurs induise une hausse significative du confort chez les citoyens européens, puisqu’ils devraient pouvoir à terme utiliser n’importe quel chargeur entre de nombreuses catégories de produits. Ce serait la fin des chargeurs incompatibles.
Pour la Commission européenne, cela devrait notamment conduire « à l’interopérabilité de 35 à 40 % supplémentaires du marché européen des EPS, en plus des quelque 50 % déjà supposés l’être en raison de la directive sur les équipements radioélectriques ».
À la frontière entre la Birmanie et la Thaïlande, le KK Park constitue une véritable usine à arnaquer les internautes, alimentée par le travail forcé de milliers de personnes.
Depuis février, la Chine, la Thaïlande et la Birmanie travaillent conjointement pour stopper ce fléau.

Ce 20 octobre, la junte birmane a opéré une descente sur place et saisi 30 récepteurs Starlink utilisés pour contourner le blocage d’internet imposé par les autorités thaïlandaises.
La police sud-coréenne a, de son côté, émis 59 mandats d’arrêt contre des ressortissants suspectés d’avoir participé à ces activités, rapporte Le Temps.

La fondation Wikimedia lance un signal d’alarme, constatant une baisse du nombre de pages vues par des humains au cours des derniers mois. Elle s’inquiète du fait que cela entraine une baisse du nombre de bénévoles enrichissant l’encyclopédie.
La fondation Wikimedia a publié un billet de blog ce vendredi 17 octobre dans lequel elle décrit une « baisse du nombre de pages vues par les utilisateurs sur Wikipédia au cours des derniers mois, soit une diminution d’environ 8 % par rapport aux mêmes mois en 2024 ».
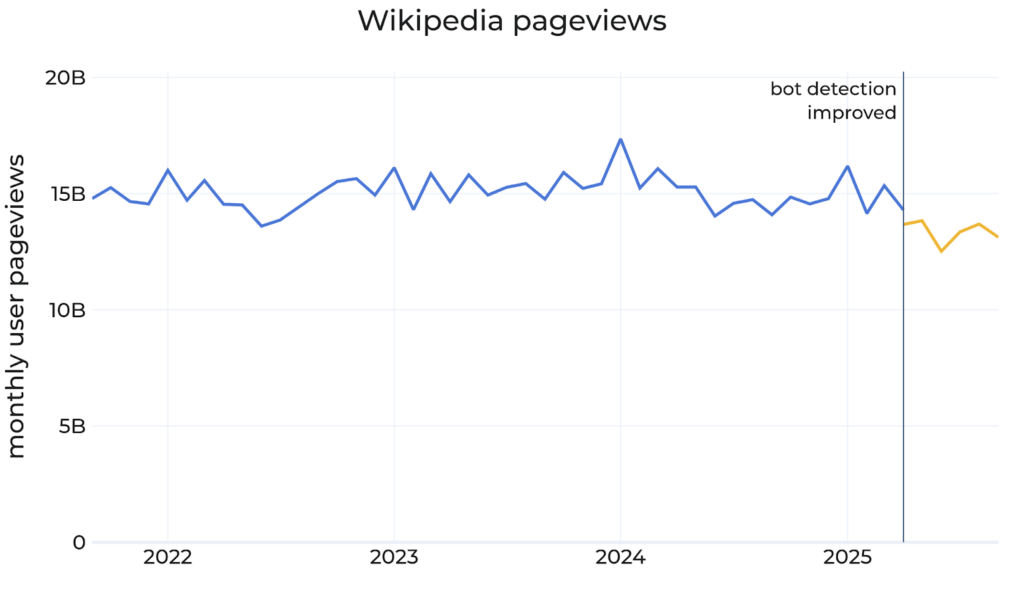
Marshall Miller, directeur de produit, y explique que la fondation a actualisé sa méthode pour identifier si un visiteur est un humain ou un robot. En effet, vers le mois de mai, elle a observé un trafic anormal venant du Brésil que ses systèmes identifiaient jusque là comme des visiteurs humains alors qu’il s’agissait vraisemblablement de consultations par des crawlers de services.
Un petit peu avant, la fondation évoquait déjà le sérieux problème que provoquaient les crawlers d’IA pour le web, en générant un trafic « sans précédent et présentent des risques et des coûts croissants ».
Les crawlers des IA deviennent un sérieux problème pour le web, même pour Wikimédia
Ici, c’est un autre effet de ces services qu’évoque la fondation. « Nous pensons que ces baisses reflètent l’impact de l’IA générative et des réseaux sociaux sur la manière dont les gens recherchent des informations, en particulier avec les moteurs de recherche qui fournissent directement des réponses aux internautes, souvent basées sur le contenu de Wikipédia », explique Marshall Miller.
Tout ça n’est pas une surprise pour la fondation qui ajoute que « cette évolution progressive n’est pas propre à Wikipédia ». « De nombreux autres éditeurs et plateformes de contenu font état de changements similaires, les utilisateurs passant davantage de temps sur les moteurs de recherche, les chatbots IA et les réseaux sociaux pour trouver des informations. Ils subissent également la pression que ces entreprises exercent sur leur infrastructure ». En juin dernier, nous relayions les inquiétudes de responsables de sites web (notamment scientifiques et/ou bénévoles).
Les fichiers robots.txt sont les premiers boucliers des sites web contre les crawlers intempestifs. Et Wikipédia ne s’en prive pas. La version anglophone de l’encyclopédie a un fichier robots.txt très détaillé, avec des commentaires. Ainsi, on peut y trouver, par exemple, une section listant des user-agents comme HTTrack ou Microsoft.URL.Control surmontée du commentaire : « Certains robots sont connus pour causer des problèmes, en particulier ceux conçus pour copier des sites entiers. Veuillez respecter le fichier robots.txt ». On peut y voir aussi que les crawlers Mediapartners-Google, utilisés par Google pour son service Adsense, sont bloqués avec juste comme commentaires le fait qu’ils sont reliés à de la pub. La partie francophone a peu ou prou la même liste avec quelques ajouts dans son robots.txt.
Mais cette première protection ne suffit plus. Comme l’expliquait Cloudflare en août dernier, Perplexity utilisait deux types de bots en fonction des autorisations des éditeurs concernant l’IA. L’entreprise déguisait ainsi parfois ses crawlers utilisés à des fins d’entrainement d’IA en navigateurs tout ce qu’il y a de plus classique.
La fondation Wikimedia rappelle que « presque tous les grands modèles linguistiques (LLM) s’entraînent sur les jeux de données de Wikipédia, et les moteurs de recherche et les plateformes de réseaux sociaux donnent la priorité à ses informations pour répondre aux questions de leurs utilisateurs ». Et elle y voit du positif pour le projet qu’elle chapote : « cela signifie que les gens lisent les connaissances créées par les bénévoles de Wikimedia partout sur Internet, même s’ils ne visitent pas wikipedia.org. Ces connaissances créées par l’homme sont devenues encore plus importantes pour la diffusion d’informations fiables en ligne ».
Mais elle y voit aussi un risque, et pas seulement sur ses infrastructures : « avec moins de visites sur Wikipédia, moins de bénévoles vont développer et enrichir le contenu, et moins de donateurs individuels vont soutenir ce travail ».
Défendant le projet Wikipédia, la fondation en donne, sans surprise, une vision opposée de celle récemment véhiculée par Elon Musk annonçant son projet personnel Grokipedia. « Wikipédia est le seul site de cette envergure à appliquer des normes de vérifiabilité, de neutralité et de transparence qui alimentent l’information sur tout Internet, et elle continue d’être essentielle pour répondre aux besoins quotidiens des gens en matière d’information, d’une manière invisible », assure-t-elle.
Le défi pour la fondation est donc que les lecteurs sachent que ce contenu vient bien de Wikipédia et qu’ils continuent à y contribuer. Le programme Wikimedia Enterprise est censé pousser les entreprises à attribuer correctement les contenus. La fondation assure travailler sur des manières d’amener les générations qui sont plus sur YouTube, TikTok, Roblox, et Instagram à collaborer à l’encyclopédie.

Depuis son compte et son réseau social personnel Truth, comme depuis les outils de la Maison Blanche, Donald Trump a de nouveau recouru à l’IA pour commenter les vastes manifestations organisées aux États-Unis contre son gouvernement et sa politique.
L’avion est signé « King Trump ». Aux commandes, un faux Donald Trump coiffé d’une couronne. Sur fond de rock’n’roll – en l’occurrence, le générique de Top Gun par Kenny Loggins –, l’engin vole au-dessus des manifestations contre le gouvernement actuel pour y larguer une pluie de déjections. Telle est la direction artistique choisie par le président des États-Unis pour signifier ce qu’il pense des manifestations qui secouent les États-Unis.
Ce samedi, près de 3 000 rassemblements étaient organisés à travers le pays pour s’opposer à la « prise de pouvoir autoritaire » de son président. « No Kings » (pas de rois) était le mot d’ordre retrouvé dans chacune de ces manifestations. Selon les organisateurs, 7 millions de personnes auraient ainsi défilé dans diverses villes d’États démocrates comme républicains, y compris aux abords de la résidence trumpienne de Mar-a-Lago, en Floride.
Sur son réseau Truth Social, ce dernier a critiqué ces mobilisations avec une vidéo scatologique générée par IA. En 2018, son conseiller Steve Bannon lui intimait d’« inonder la zone de merde », c’est-à-dire de créer la confusion dans le débat public en y projetant indistinctement tout élément d’information, de désinformation et de contenus irritants susceptibles de créer des polémiques. Depuis quelques mois, le chef des États-Unis semble appliquer la consigne toujours plus littéralement, que ce soit sur son réseau personnel ou sur des plateformes plus grand public.
Car cet épisode d’aéronautique insultante est loin d’être le premier cas dans lequel Donald Trump recourt à l’IA générative pour passer ses messages politiques. Début 2025, l’homme d’État diffusait une vidéo étrange, pensée comme satirique par ses créateurs, d’une hypothétique « riviera » créée à Gaza. Donald Trump, Elon Musk et Benjamin Netanhyahou y étaient représentés sous des pluies de dollars ou face à une femme exotisée, habillée en danseuse du ventre.
À la même époque, différents groupes de défense des droits de la population latino avaient critiqué le président des États-Unis pour son recours à des mèmes et des images générées par IA visant à décrédibiliser les représentants démocrates du Congrès. Parmi les images produites, l’une visait notamment le représentant de New-York Hakeem Jeffries. Premier homme noir élu au poste de Minority Leader, le poste le plus important à la tête de l’opposition à la Chambre des représentants, Jeffries était représenté avec un sombrero de style mexicain et son discours recouvert d’une musique de mariachis.
L’Hispanic Federation, la Latino Victory Foundation, la League of United Latin American Citizens et divers autres organismes avaient alors souligné que l’usage « préoccupant de l’IA pour amplifier les stéréotypes haineux est non seulement irresponsable, mais constitue aussi un acte de désinformation visant à stigmatiser encore plus les Latinos ».
Cet été, il relayait encore une vidéo Gen AI d’une fausse arrestation de Barack Obama. L’IA a aussi été utilisée pour attaquer Trump et sa politique. Alors qu’il lançait une guerre tarifaire contre l’essentiel de la planète, des usagers chinois ont inondé TikTok, Douyin et d’autres réseaux de vidéos supposées représenter des Américains obèses, voire Donald Trump, J.D. Vance ou Elon Musk, à l’usine.
L’emploi que fait le président des États-Unis d’IA générative s’inscrit par ailleurs dans une tendance plus large de multiplication des contenus dits d’« AI slop », c’est-à-dire de « boue » d’IA. Une nouvelle pollution des espaces numériques qui a émergé avec le succès des outils comme ChatGPT, Claude ou Midjourney, et que divers observateurs accusent désormais de « tuer internet ».
Après s’être penché sur 65 000 articles de langue anglaise publiés entre janvier 2020 et mai 2025, le spécialiste du SEO Graphite vient de publier un rapport constatant que depuis quelques mois, la moitié des publications recensées avaient été générées par IA. Si Donald Trump n’utilise pas le format article, ses publications de vidéos et de mèmes adaptés aux réseaux sociaux contribuent, eux aussi, à la tendance.
Ce week-end, les comptes officiels de la Maison-Blanche ont diffusée d’autres images générées par IA représentant Donald Trump et J.D. Vance affublés de couronnes, et leurs opposants, de nouveau, coiffés de sombrero.
Erebor, le projet de banque fondé par plusieurs acteurs de l’industrie technologique américaine et nommé d’après l’œuvre de J.R.R. Tolkien, a reçu une première approbation de l’administration Trump.
Porté par Palmer Lucker, cofondateur de la société de technologies militaires Anduril, et le Founders Fund de Peter Thiel, le projet vient de recevoir une autorisation conditionnelle pour obtenir le statut de banque nationale.
Cette approbation dépend de l’obtention, par la banque, d’actions dans une banque de la Réserve fédérale et d’une assurance-dépôts auprès de la Federal Deposit Insurance Corporation.
En pratique, Erebor pourrait avoir pour mission de combler le vide laissé par le dépôt de bilan de la Silicon Valley Bank (SVB) en 2023, et de financer des projets risqués, de start-ups voire de l’écosystème des cryptoactifs.

La sénatrice démocrate Elizabeth Warren sonne d’ailleurs l’alarme sur le projet, s’inquiétant de le voir servir les intérêts de la famille Trump dans les crypto-actifs.
Dans un communiqué, elle critique le fait que les « régulateurs financiers de Trump viennent d’accélérer l’approbation de cette entreprise risquée qui pourrait entraîner un nouveau plan de sauvetage financé par les contribuables américains et déstabiliser notre système bancaire », rapporte MSNBC.
Le Privacy Sandbox était une initiative lancée en 2019. À l’époque, Google annonçait son intention de répondre aux demandes liées à la vie privée sur les cookies tiers. Il s’agissait alors de remiser ces derniers graduellement, au profit d’une approche basée sur des cohortes. Objectif, obtenir des statistiques permettant de personnaliser les publicités, tout en réduisant les données personnelles absorbées dans l’opération.
Dans un billet publié le 17 octobre, Anthony Chavez, vice-président de Google, annonce que l’initiative s’arrête. C’est tout le projet qui tombe à l’eau, même si certaines technologies développées dans ce cadre, comme CHIPS et FedCM, « ont été largement adoptées ». Selon le responsable, la décision a été prise suite aux retours de l’industrie : « Les commentaires que nous avons reçus nous ont permis de mieux comprendre ce qui peut générer le plus de valeur pour les entreprises, les développeurs et les utilisateurs ».

Si certaines fonctions demeurent, l’essentiel du développement s’arrête : les API de rapport d’attribution, la protection de la propriété intellectuelle, la personnalisation sur l’appareil, l’agrégation privée, l’audience protégée, les signaux d’application protégés ou encore les ensembles de sites associés.
Cet abandon n’est pas vraiment une surprise. Le développement de la Privacy Sandbox a dû affronter de nombreuses critiques, dont des critiques d’instances comme la Competition and Markets Authority (CMA) au Royaume-Uni et le ministère américain de la Justice. En 2024, Google plantait un gros clou dans le cercueil de son initiative en annonçant que les cookies tiers allaient finalement rester en place, mais que Chrome serait modifié pour permettre « un choix éclairé » sur leur comportement. Mais en avril dernier, Google a confirmé que tout continuerait de fonctionner comme aujourd’hui.
Dans son communiqué, Anthony Chavez précise cependant que certains aspects de la Privacy Sandbox vont continuer à infuser au sein de l’éditeur. Google assure par exemple que les commentaires des entreprises qui se sont appuyées sur l’API de rapport d’attribution l’aideront à « éclairer » son travail sur une norme interopérable au sein du W3C.
Mise à jour du 21 octobre à 8H10 : Dans un message publié à 00h53 (heure française) cette nuit, AWS a informé que sa panne était résolue. La société explique que tout est parti de problèmes de résolution DNS pour les points de terminaison DynamoDB dans la région US-EAST-1. À cause de certaines dépendances à cette région (Virginie du Nord), d’autres ont été touchées.
Après quoi, le sous-système EC2 a lâché, entrainant une cascade de problèmes dans les instances liées. La panne s’est ensuite étendue au Network Load Balancer (équilibrage de charge), entrainant « des problèmes de connectivité réseau dans plusieurs services tels que Lambda, DynamoDB et CloudWatch ».
Tout est rentré dans l’ordre, même si un arriéré de messages était encore constaté dans des services comme AWS Config, Redshift et Connect au moment de la dernière mise à jour.
Mise à jour de 15h30 : AWS dit avoir trouvé la cause de la panne et les réparations seraient bien avancées. Certains services, notamment Signal, fonctionnent de nouveau.
Article original de 10h54 :
La région Virginie du Nord rencontre actuellement de gros problèmes chez Amazon Web Services. Sur le site dédié, on peut lire effectivement :
« Nous pouvons confirmer des taux d’erreur significatifs pour les demandes adressées au point de terminaison DynamoDB dans la région US-EAST-1. Ce problème affecte également d’autres services AWS dans la région US-EAST-1. Pendant ce temps, les clients peuvent ne pas être en mesure de créer ou de mettre à jour des demandes d’assistance. Les ingénieurs ont été immédiatement mobilisés et travaillent activement à atténuer le problème et à en comprendre pleinement la cause profonde »

Comme on s’en doute, cette panne chez AWS entraine de multiples défaillances, tant les entreprises et autres organisations recourent massivement aux services cloud d’Amazon. C’est le cas par exemple chez Signal, dont le service est inaccessible pour de nombreux utilisateurs. Meredith Whittaker a confirmé le problème sur Bluesky et sur Mastodon.
Confirmation également pour Perplexity, dont les services IA ne sont plus disponibles. Selon les régions, Alexa, Asana, Snapchat, Fortnite, Epic Games Store et même ChatGPT sont également en panne.
Un problème est également signalé chez Cloudflare, sans que l’on sache pour le moment si les deux situations sont liées. Sur son site, l’entreprise indique que le problème a été identifié et qu’un correctif est en préparation, là où Amazon précise dans son bulletin que ses équipes cherchent la cause profonde.
Dans un communiqué daté du 17 octobre, Europol avertit du démantèlement d’une infrastructure comprenant 1 200 appareils de type SIM-box, qui géraient un total de 40 000 cartes SIM. Ce réseau pouvait être utilisé pour des activités criminelles comme le phishing et le smishing (contraction de SMS et phishing).
L’opération, baptisée SIMCARTEL, a été menée par les polices autrichienne, estonienne et lettone, soutenues par Europol et Eurojust. Elle a donné lieu à 26 perquisitions et à l’arrestation de 7 personnes, dont 5 lettones. Les 1 200 appareils ont été saisis, de même que les 40 000 cartes SIM qu’ils contenaient et plusieurs centaines de milliers d’autres cartes qui attendaient d’être utilisées.
Les forces de l’ordre ont également saisi cinq serveurs, pris le contrôle de deux domaines (gogetsms.com et apisim.com), gelé 431 000 euros sur des comptes bancaires et 333 000 dollars en cryptomonnaies, et saisi quatre véhicules de luxe.
« Le service en ligne créé par le réseau criminel offrait des numéros de téléphone enregistrés à des personnes de plus de 80 pays pour les utiliser dans des activités criminelles. Il a permis aux auteurs de créer de faux comptes sur les réseaux sociaux et les plateformes de communication, qui ont ensuite été utilisés pour des cybercrimes tout en masquant leur véritable identité et leur emplacement », explique Europol.
Parmi les activités criminelles citées, on trouve la fraude, l’extorsion, le passage de clandestins et la distribution de matériel pédopornographique. Europol donne plusieurs exemples de fraudes : faux comptes sur le marché de la seconde main, escroqueries fille-fils (votre enfant vous annonce avoir changé de numéro de téléphone et prétexte des problèmes urgents pour se faire envoyer de l’argent), des fraudes à l’investissement, de fausses boutiques, de faux sites bancaires, etc.
La structure est décrite comme sophistiquée avec un haut niveau d’organisation. Toujours selon Europol, elle est responsable de 1 700 cas de fraude en Autriche et 1 500 en Lettonie. Dans la seule Autriche, le montant des pertes financières s’élève à 4,5 millions d’euros. Europol indique cependant que l’ampleur exacte du réseau criminel reste à déterminer.
Ce type d’opération est courant, comme on avait pu le voir fin septembre aux États-Unis.
Le gestionnaire d’archives bien connu 7-Zip est touché par deux failles importantes, mais non critiques. Estampillées CVE-2025-11001 et CVE-2025-11002, elles sont de type « path traversal » et résident dans la manière dont l’application gère les liens symboliques de type Unix sur Windows lors de l’extraction d’un fichier Zip.
Les failles ne peuvent être exploitées que sous Windows et résident dans le module ArchiveExtractCallback.cpp. 7-Zip ne gère pas les liens symboliques de manière assez rigoureuse : si un lien pointe vers un chemin d’accès absolu (par exemple c:\users), le logiciel le considère comme un lien relatif. Les mécanismes de sécurité associés peuvent alors être ignorés, le lien symbolique pouvant dès lors se résoudre hors du répertoire d’extraction. Les failles sont donc exploitables avec des archives spécifiquement conçues et des prototypes d’exploitation existent déjà.
Découvertes par Ryota Shiga de GMO Flatt Security, elles ont été révélées par la Zero Day Initiative le 7 octobre. Elles ont toutes deux un score CVSS de 7 sur 10 et sont donc considérées comme importantes. Principale limite à l’exploitation automatisée, la nécessité de disposer de droits élevés, un mode développeur ou un contexte de service élevé, comme l’explique Cybersecurity News.
Les deux vulnérabilités sont exploitables dans toutes les versions de 7-Zip allant de la 21.02 à la 25.00. Seule solution, mettre à jour le logiciel pour la version 25.01 au moins, la gestion des liens y étant plus stricte. Cette version est sortie en juillet, mais 7-Zip ne possède aucun mécanisme de mise à jour automatique. À moins d’utiliser des outils tels que UniGetUI, il faut donc se rendre sur le site du gestionnaire d’archives pour y récupérer la dernière version, la 25.01 sortie le 3 aout.
Ce week-end, le Centre hospitalier intercommunal de Haute-Comté à Pontarlier a été victime d’une cyberattaque de type cryptolocker, « ayant conduit au chiffrement d’une partie de ses données informatiques », explique l’hôpital dans un communiqué obtenu par Ici Besançon.
Rapidement, les services informatiques ont été coupés et l’hôpital a prévenu l’Agence du Numérique en Santé (ANS), l’Agence Régionale de Santé Bourgogne-Franche-Comté, ainsi que l’Agence Nationale de la Sécurité des Systèmes d’Information (ANSSI). Il a aussi déposé plainte.
Selon l’Est Républicain, les services de l’hôpital ont détecté des anomalies à 1h45 du matin dans la nuit du samedi 18 au dimanche 19 octobre, puis ils ont trouvé un message expliquant que les données de l’hôpital étaient chiffrées avec une demande de rançon.

Lors d’une conférence de presse dimanche soir et à laquelle a assisté l’Est Républicain, le directeur du centre hospitalier, Thierry Gamond Rius, a affirmé : « on peut considérer que la situation est sous contrôle. Difficile, mais sous contrôle et surtout transparente pour les patients ».
« On revient au fonctionnement papier pour les prescriptions des patients, pour les commandes, la gestion, etc. Ce dimanche matin, nous avons fait le tour des services, afin de voir si tout était bien mis en œuvre », a-t-il quand même ajouté. Mais aucun patient ne sera transféré ailleurs et le directeur prévoit de garder la même activité opératoire.
« Les serveurs sont compromis, il faut repartir sur une infrastructure vierge », explique-t-il encore, estimant en avoir pour plusieurs semaines.
Un numéro vert pour les patients du centre hospitalier a été mis en place : 0 805 090 125.

En plus de pousser au doomscrolling, Sora est massivement utilisée pour créer des deepfakes. De Robin Williams à Martin Luther King en passant par Whitney Houston, l’application a permis à des utilisateurs de créer des vidéos détournant l’image de personnalités historiques, notamment à des fins sexistes et racistes.
C’est dans un message sur le réseau social X qu’OpenAI a annoncé ce matin qu’elle avait « suspendu la génération d’images représentant le Dr King [Martin Luther King] afin de renforcer les mesures de protection des personnages historiques ». L’entreprise affirme le faire après avoir « abordé la question de la représentation de l’image du Dr Martin Luther King Jr. dans les générations Sora » avec les descendants de la figure noire du mouvement des droits civiques.
Sora 2, l’application de doomscrolling de vidéos générées par IA d’OpenAI est sortie récemment aux États-Unis mais pas encore en Europe.
Bernice King avait publié sur Instagram la semaine dernière un post demandant aux gens d’arrêter de lui envoyer des vidéos générées par IA utilisant l’image de son père. Elle y fait référence à la même demande faite par Zelda Williams, la fille de Robin Williams. Celle-ci implorait : « Arrêtez de croire que je veux voir ça ou que je vais comprendre, ce n’est pas le cas et ça ne changera pas ». Et elle ajoutait : « Si vous essayez juste de me troller, j’ai vu bien pire, je vais restreindre l’accès et passer à autre chose. Mais s’il vous plaît, si vous avez un minimum de décence, arrêtez de lui faire ça, à lui, à moi, à tout le monde même, point final. C’est stupide, c’est une perte de temps et d’énergie, et croyez-moi, ce n’est PAS ce qu’il voudrait ».
Mais le Washington Post raconte que le problème n’est pas seulement le fait que des personnes connues soient visibles dans des vidéos générées par IA photoréalistes, mais aussi que l’outil est utilisé contre ces personnes de façon dégradante, sexiste, ou raciste. Ainsi, une vidéo montrait par exemple Whitney Houston ivre, comme si elle était filmée par une caméra corporelle de police. Une autre montrait Martin Luther King faisant des cris de singe pendant son célèbre discours « I have a dream ».
D’autres vidéos montrent des deepfakes de Malcolm X, une autre figure noire du mouvement des droits civiques aux États-Unis, faisant des blagues salaces, se battant avec Martin Luther King ou déféquant sur lui-même. « Il est profondément irrespectueux et blessant de voir l’image de mon père utilisée de manière aussi cavalière et insensible alors qu’il a consacré sa vie à la vérité », déplore sa fille, Ilyasah Shabazz, auprès du Washington Post, qui rappelle qu’elle a assisté à l’assassinat de son père en 1965 alors qu’elle n’avait que deux ans. Et elle pose la question : pourquoi les développeurs n’agissent pas « avec la même moralité, la même conscience et le même soin […] qu’ils le souhaiteraient pour leur propre famille ».
Comme nous l’expliquions fin septembre, l’application dispose d’une fonctionnalité censée limiter les deepfakes. Une personne qui a vérifié son identité peut utiliser son image dans des vidéos et d’autres peuvent faire le faire à condition qu’elle donne son consentement. La journaliste Taylor Lorenz a déjà témoigné qu’une personne qui la harcèle avait créé des deepfakes d’elle, mais qu’elle avait pu les faire supprimer en utilisant ce système. Par contre, au lancement de l’application, OpenAI a décidé de ne pas mettre en place de restriction sur les « personnages historiques ».
Ne réagissant qu’après les divers témoignages de descendants célèbres et en ne citant que le cas de Martin Luther King, OpenAI affirme dans son tweet de ce matin : « Bien qu’il existe un intérêt certain pour la liberté d’expression dans la représentation de personnages historiques, OpenAI estime que les personnalités publiques et leurs familles devraient avoir le contrôle final sur l’utilisation de leur image. Les représentants autorisés ou les ayants droit peuvent demander que leur image ne soit pas utilisée dans les caméos [nom utilisé par OpenAI pour sa fonctionnalité de deepfake] de Sora ». En bref, l’entreprise choisit de proposer une option d’opt-out pour les représentants des personnalités historiques qui ne voudraient pas que leur image soit utilisée dans Sora.
Pour éviter que les vidéos générées par IA soient repartagées en dehors de son réseau pour désinformer, OpenAI a mis en place un watermark qui se déplace au cours de la lecture. Mais, comme l’a remarqué 404 Media, de nombreux systèmes de suppression de ces filigranes ont rapidement pullulé sur le web, rendant rapidement cette protection contre la désinformation peu efficace.
Tout ça a permis d’avoir un certain succès. Mais, comme le souligne notre consœur Katie Notopoulos de Business Insider, la plupart des utilisateurs semblent être des garçons adolescents, contre « très, très peu de femmes ». « De manière générale, si une plateforme sociale est un endroit effrayant pour les femmes… mon ami, tu as un problème », commente-t-elle.
Pendant ce temps-là, comme nous l’évoquions aussi, Meta a sorti Vibes, un équivalent de Sora mais sans cette possibilité de deepfake. Celui-ci semble avoir beaucoup moins de succès. Pour notre confrère de Wired, Reece Rogers, ses premières expériences sur l’application de Meta étaient « ennuyeuses et sans intérêt ». Pour lui, le flux de Sora, « avec sa prolifération de deepfakes souriants, était beaucoup plus électrique… et inquiétant ».
On n’en a en tout cas pas fini avec les vidéos générées par IA plus photoréalistes les unes que les autres, puisque Google vient d’annoncer ce jeudi 15 octobre la sortie de Veo 3.1. L’entreprise promet aux utilisateurs plus de contrôle dans son outil d’édition de vidéos générées par IA Flow : « Nous sommes toujours à l’écoute de vos commentaires, et nous avons compris que vous souhaitez avoir davantage de contrôle artistique dans Flow, avec une prise en charge audio améliorée dans toutes les fonctionnalités », affirme l’entreprise. Elle promet, entre autres, une génération de vidéos plus rapidement proche des demandes des utilisateurs et une « qualité audiovisuelle améliorée lors de la conversion d’images en vidéos ».
Anthropic a procédé à plusieurs annonces autour de ses modèles Claude. D’abord, l’arrivée d’une version 4.5 de Haiku, son modèle plus léger. Ensuite, le lancement d’une intégration dans Microsoft 365. Enfin, la possibilité d’ajouter des Skills pour renforcer la précision des modèles dans des tâches spécifiques.
Le 15 octobre, Anthropic a présenté la dernière version de son modèle le plus petit, Haiku. Ces modèles sont souvent attendus, car ils permettent en général une baisse significative de l’énergie nécessaire pour l’inférence, au prix d’une baisse plus ou moins contenue de la précision.
Dans le cas de Haiku 4.5, presque un an après la précédente mouture du modèle (3.5), Anthropic revendique des résultats similaires à son grand frère Sonnet 4, mais pour « un tiers du coût et une rapidité multipliée par deux ». On peut aussi espérer une baisse de consommation électrique lors de l’inférence.
Sans surprise, l’entreprise met en avant le développement logiciel, avec un score de 73,3 % sur SWE-bench Verified. Un score inférieur à Sonnet 4.5 (77,2 %) et GPT-5 Codex (74,5 %), mais supérieur à Sonnet 4 (72,7 %), à la version classique de GPT-5 (72,8 %) et Gemini 2.5 Pro (67,2 %).
Dans son tableau de scores, Anthropic montre surtout que son Haiku 4.5 est meilleur que Sonnet 4 dans pratiquement tous les domaines. Sonnet 4.5 garde bien sûr la couronne, mais Haiku présente un gros avantage sur le prix : 1 dollar le million de jetons en entrée et 5 dollars par million de jetons en sortie.

Selon Anthropic, Haiku 4.5 est le modèle idéal pour les versions gratuites d’essai d’applications ou services. Sa taille réduite permet l’exécution de plusieurs agents Haiku en parallèle ou dans des scénarios présentant une puissance limitée ou une sensibilité à la latence.
« Historiquement, les modèles ont sacrifié la vitesse et le cout pour la qualité. Claude Haiku 4.5 brouille les lignes sur ce compromis : il s’agit d’un modèle de frontière rapide qui maintient l’efficacité des couts et signale la direction que prend cette classe de modèles », a déclaré Jeff Wang, CEO de Windsurf. Chez GitHub, le chef de produit Matthew Isabel évoque lui aussi « une qualité comparable à celle de Sonnet 4, mais à une vitesse plus rapide ».
Anthropic fournit désormais son propre connecteur pour Microsoft 365, via MCP. Pour l’instant, ce connecteur permet de mettre en contact les services suivants avec Claude :
Le connecteur peut également être utilisé pour créer une réserve de toutes les informations librement accessibles en interne pour obtenir un catalogue de ressources. Anthropic donne l’exemple d’une personne qui poserait alors une question sur la position de son entreprise sur le travail à distance et obtiendrait une réponse basée sur les documents issus des ressources humaines.
Le nouveau connecteur n’est disponible que pour les personnes ayant un abonnement Claude Team ou Enterprise. Pour ce dernier, les administrateurs doivent avoir activé le connecteur dans l’ensemble de l’organisation avant que les utilisateurs individuels puissent s’en servir.
Pour les personnes n’ayant que faire d’une intégration à Microsoft 365, Anthropic vient d’annoncer une nouveauté à fort potentiel : les Agents Skills. De manière générale, il s’agit de renforcer Claude sur des tâches spécialisées à l’aide de fichiers spécifiques.
Anthropic indique dans son billet de blog que l’on peut désigner à Claude un dossier contenant diverses ressources, comme des scripts, des fichiers contenant des instructions, des modèles ou encore un exemple de ce que l’on peut obtenir. On peut demander à l’IA de s’en servir pour accomplir des tâches spécifiques plus rapidement ou en orientant les résultats de manière précise.
Selon l’entreprise, les Skills permettraient à Claude d’être beaucoup plus efficace sur des missions particulières, comme la création de tableaux Excel avec des formules, la préparation de présentations, ou encore un respect plus strict des directives de l’organisation sur sa marque.
Anthropic évoque également un système de « composition », qui permet à Claude de gérer plusieurs sources de Skills pour des flux de travail plus complexes. Les Skills sont aussi « portables », car une fois créées, elles peuvent être partagées avec d’autres personnes ou structures, sans modification.
Au sein des entreprises, la fonction doit avoir été activée par les administrateurs. Côté utilisateurs, il faut en outre se rendre dans les paramètres de Claude pour activer les Skills. Par défaut, Claude n’en propose qu’une, qui pose des questions sur le flux de travail de l’utilisateur, génère une structure de dossiers, regroupe les ressources pointées et formatera un fichier SKILL.md en conséquence.
Les Skills pourront également être intégrées dans des plugins et donc récupérables depuis la place de marché d’Anthropic. Elles sont en outre disponibles pour les agents, via le SDK Claude Agent, toujours dans l’idée de personnaliser leur fonctionnement.
Anthropic et Salesforce viennent de signer un important partenariat autour de Claude, qui marque une victoire pour Anthropic. Salesforce va en effet positionner Claude comme modèle de référence dans sa plateforme Agentforce (via Amazon Bedrock), « permettant aux clients de Salesforce dans les secteurs des services financiers, de la santé, de la cybersécurité et des sciences de la vie d’utiliser une IA de confiance tout en assurant la sécurité des données sensibles », claironne Anthropic.
S’agissant de secteurs réglementés, l’utilisation de Claude se fait dans une infrastructure spécifique. L’exécution du LLM se fait au sein du « périmètre de confiance » de Salesforce. Tout le trafic lié est en fait contenu dans le cloud virtuel privé de Salesforce.
Les deux sociétés renforcent également l’utilisation de leurs outils respectifs. Salesforce va ainsi déployer Claude Code pour l’ensemble de ses développeurs, tandis qu’Anthropic va renforcer son utilisation de Slack. Pour les clients, les intégrations bidirectionnelles Claude et Slack viennent d’être mises à disposition.
Elles vont aussi collaborer sur des solutions IA spécifiques à l’industrie, à commencer par le secteur financier avec l’intégration de Claude for Financial Services dans Agentforce Financial Services. « Par exemple, un conseiller financier utilisant Agentforce peut demander à son agent IA, propulsé par Claude, de résumer les portefeuilles des clients, de signaler les nouvelles exigences de l’industrie affectant les régimes de retraite et d’automatiser le suivi du consentement et la sensibilisation des clients », indique Anthropic en exemple.
La Fédération internationale de l’industrie phonographique (IFPI) marque un point dans sa croisade contre les sites dédiés au téléchargement des œuvres diffusées via des plateformes de streaming comme YouTube, Deezer et consorts. L’organisation, qui représente pour mémoire les intérêts des grandes majors de la musique, a en effet annoncé mardi 14 octobre avoir obtenu la fermeture d’un réseau de douze sites dédiés au stream ripping.
D’après l’IFPI, les douze sites représenteraient un trafic de l’ordre de 620 millions de visites sur les douze derniers mois. Dans le lot figure notamment Y2mate.com, connu pour permettre le téléchargement de vidéos YouTube aux formats mp4 (vidéo) ou mp3 (audio uniquement).
Les douze sites concernés affichent désormais le logo de l’IFPI ainsi qu’un message de sensibilisation. « Les sites qui convertissent des flux sous licence en téléchargements gratuits sont illégaux. Leur utilisation ou leur exploitation peut entraîner de graves conséquences, y compris une condamnation pénale », indique l’IFPI.

L’organisation rappelle qu’elle a déjà tenté à plusieurs reprises d’obtenir le blocage de ces sites, avec des actions intentées dans treize pays. La mise hors ligne des sites et la saisie des noms de domaine montrent que l’action s’est cette fois concentrée sur les exploitants de ces services.
L’IFPI ne donne pour l’instant aucun détail sur la façon dont ces sites ont été mis hors ligne, ni sur les poursuites qui pourraient être engagées à l’encontre de leurs administrateurs. Elle révèle en revanche que la plupart d’entre eux étaient opérés depuis le Vietnam.
« L’opérateur de Y2mate et les 11 autres sites ont accepté de fermer définitivement et de cesser toute atteinte aux droits des membres de l’IFPI. La plupart des domaines sont désormais détenus par l’IFPI, notamment Y2mate.com, Yt1 s.com, Utomp3.com, Tomp3.cc et Y2mate.gg », affirme l’organisation. De nombreux noms de domaine jouant de la proximité avec les sites fermés restent cependant accessibles en ligne, ouvrant aisément la voie à des services miroir. D’après nos constatations, le nom « Y2mate » est en effet déposé sur 140 extensions de nom de domaine différentes.
En 2017, l’IFPI avait réussi à obtenir la fermeture d’un autre service de stream ripping très populaire, YouTube-mp3, au terme d’une longue bataille. En France, le sujet s’est déjà invité dans les débats et réflexions liés à la copie privée.

En septembre, on apprenait que Google avait revu sa manière de distribuer les correctifs pour les failles de sécurité sur Android. Ce changement a un impact important sur LineageOS, une ROM personnalisée pour les smartphones. L’équipe de développement explique le problème et assure qu’elle s’adapte.
Le 16 septembre, nous expliquions que Google avait – assez silencieusement – modifié sa manière de distribuer ses bulletins de sécurité mensuels. Les fameux ASB (Android Security Bulletins) étaient depuis des années distribués une fois par mois, avec à leur bord des informations sur les failles de sécurité corrigées. Il appartenait ensuite à chaque vendeur (OEM) d’appliquer ces changements. Quand le travail est fait, les utilisateurs reçoivent ainsi une mise à jour de sécurité par mois, les paramètres d’Android donnant le mois et l’année de la plus récente.
Avec le changement, ils sont toujours publiés mensuellement, mais leur contenu évolue de manière drastique. Seules sont renseignées les failles présentant un haut risque, notamment les vulnérabilités critiques qui présentent un fort risque d’être exploitées ou qui le sont déjà. Tout le reste est rassemblé dans un bulletin publié tous les trois mois.
Ce calendrier est désormais synchronisé avec les QPR (Quarterly Platform Releases), ces mises à jour fournies par Google pour améliorer et enrichir Android. Ce qui n’est pas sans causer des problèmes pour les ROM personnalisées, comme l’a expliqué LineageOS dans une publication du 11 octobre.
L’équipe de développement commence par une bonne nouvelle : pour une fois, elle est en avance. Elle indique que bon nombre des améliorations d’Android 16 sont en fait périphériques et ne touchent pas profondément le cœur du système. Le gros travail d’adaptation fait avant a payé et LineageOS 23.0 a donc été publié.
Pour prévenir les réactions sur cette numérotation, l’équipe prend les devants : pourquoi 23.0 et pas 23.1, puisque la QPR1 d’Android est sortie ?
C’est justement là qu’est le problème. L’équipe réexplique le fonctionnement des bulletins de sécurité et de leur changement de rythme, et note l’alignement des gros bulletins trimestriels avec les QPR. Or, la QPR1 d’Android 16 a beau avoir été distribuée (diffusée immédiatement aux Pixel et envoyée aux constructeurs pour intégration), son contenu n’a pas été reversé à AOSP (Android Open Source Project), la branche open source sur laquelle le système de Google est basé et dans laquelle puisent les ROM personnalisées.
L’équipe pointe ainsi un bulletin de juillet vide, pour la toute première fois. Le bulletin d’aout ne contenait qu’un seul correctif, tandis que celui de septembre « a omis des correctifs pour plusieurs vulnérabilités, avec des correctifs partagés en privé avec des partenaires sous embargo ». C’était effectivement ce qu’annonçait Android Authority le mois dernier. L’équipe précise d’ailleurs que c’est la raison pour laquelle LineageOS 22.2 affichait un niveau de sécurité d’aout 2025 jusque tard en septembre.
L’équipe affirme que l’adaptation est nécessaire et qu’elle n’a pas le choix.
Dans un premier temps, elle a pris la décision de lancer LineageOS 23.0, correspondant donc à la version initiale d’Android 16, ce qu’elle nomme « QPR0 ». Pour le reste, le développement de la ROM devra suivre le nouveau rythme de publication des bulletins de sécurité. Pas le choix, il faudra prendre son mal en patience et subir un décalage entre la publication des correctifs et leur arrivée effective dans AOSP.
Ce décalage sera également fonctionnel. Dans la QPR1 par exemple, Google a déployé son langage graphique Material 3 Expressive. Comme l’indique l’équipe dans son annonce, il faudra donc patienter pour le voir dans LineageOS. Il ne s’agit que d’un exemple, mais ce décalage se répercutera à l’ensemble des nouveautés dans les QPR et – sans doute plus grave – dans les bulletins de sécurité. Car comme nous l’indiquions dans notre précédente actualité, plus l’attente est grande entre la découverte d’une faille et sa correction, plus les risques d’exploitation sont grands.
L’équipe se veut quand même rassurante : le travail va continuer. LineageOS 23.0 comporte une longue série de mises à jour de ses composants, ainsi que plusieurs évolutions importantes dans les applications, répercutées sur les versions plus anciennes du système. Aperture, dédiée à la prise de photos, a ainsi été intégralement réécrite. La maintenance en sera beaucoup plus simple selon l’équipe, et plusieurs fonctions ont été ajoutées, dont le support du JPEG Ultra HDR, du RAW et de la capture RAW+JPEG.
Le lecteur musical Twelve gagne plusieurs nouveautés lui aussi, dont un bouton pour lancer directement des musiques aléatoires, l’ajout d’informations supplémentaires sur l’écran de lecture, le support du MIDI (oui oui) ou encore la possibilité de relancer l’analyse de la base, pour détecter des titres ajoutés récemment.
L’Arcep, l’Autorité de régulation des télécoms, vient de mettre à jour plusieurs de ses cartes avec des données actualisées. C’est le cas de l’état de la couverture mobile par département en France avec des chiffres du deuxième trimestre, celle pour la France métropolitaine arrive.
Sur l’IPv6, le régulateur « enrichit et met à jour sa carte interactive de l’IPv6 dans le monde : plus de données, plus de précision, plus de transparence ». L’historique remonte désormais à octobre 2013, la couverture est élargie à 229 pays (au lieu de 100) et les données sont actualisées tous les mois (au lieu de tous les deux mois). Enfin, la méthodologie et la fiabilité du classement IPv6 des 100 pays avec le plus grand nombre d’internautes « ont été revues et renforcées ».
La France est maintenant à la deuxième place, avec un taux de 71,8 % derrière l’Inde à 75,4 %. Toujours selon l’Arcep, l’Hexagone était en tête en juin 2025.

L’Autorité publie également cette semaine les résultats de son enquête 2025 sur la qualité de service à la Réunion, issus de plus de 177 000 mesures pour quatre opérateurs mobiles : Orange, SRR, Zeop Mobile et Telco OI.
Pour la voix, SRR arrive en tête, suivi par Zeop mobile et Orange pour les appels maintenus sans perturbation. Orange est par contre en première position sur la qualité des appels, suivi de Zeop mobile, puis de SRR. « Telco OI se situe en retrait sur ces deux indicateurs ». Sur l’Internet mobile, Zeop est en tête, Orange et SRR deuxièmes ex aequo. « Telco OI se situe derrière les autres opérateurs ».

L’information a été publiée par le généralement très bien informé Mark Gurman pour Bloomberg. Ke Yang, arrivé chez Apple il y a six ans, quitterait l’entreprise pour Meta. Il venait de prendre la direction de l’équipe « Answers, Knowledge and Information, ou AKI, en charge de développer des fonctionnalités pour rendre l’assistant vocal Siri plus proche de ChatGPT en ajoutant la possibilité d’extraire des informations du Web ».
Ce départ est le dernier d’une longue série, comme le rappelle à juste titre TechCrunch : « Ruoming Pang, ancien responsable des modèles d’IA d’Apple, est parti pour Meta plus tôt cette année. Environ une douzaine de membres de l’équipe AIML (AI et Machine Learning) d’Apple ont également quitté l’entreprise. Plusieurs membres ont rejoint les nouveaux Superintelligence Labs de Meta ». Toujours selon Bloomberg, d’autres départs pourraient arriver.

Apple devrait lancer une refonte de Siri en mars, selon notre confrère. Une évolution attendue de pied ferme car l’assistant est clairement en retard sur ses concurrents. « Siri est complètement con », lâchait même la semaine dernière Luc Julia aux Assises de la cybersécurité de Monaco.
Meta vient d’annoncer qu’elle renonçait à son application Messenger indépendante sur les PC Windows et les Mac. Une fois Messenger abandonné, « vous ne pourrez plus vous connecter à cette application et serez automatiquement redirigé·e vers le site web de Facebook pour les messages », prévient l’éditeur dans une note.
Meta ajoute qu’une notification est en cours d’envoi chez l’ensemble des personnes concernées. Celles-ci disposent de 60 jours pour se préparer au changement, portant la date officielle de l’abandon au 16 décembre. Une fois le délai écoulé, il ne sera plus possible de se connecter au service depuis l’application.
Quelles solutions ? Meta en donne deux : soit passer par Facebook, puisque Messenger y est intégré, soit en passant par le site dédié, Messenger.com. Notez que pour ce dernier, il reste possible selon les navigateurs de le déclarer comme application, pour garder une fenêtre indépendante.
La fiche indique qu’il est possible de garder l’historique de ses conversations, à condition d’avoir activé le stockage sécurisé et défini un code PIN. Sans cette option, les échanges ne se retrouveront pas sur les autres accès, qu’il s’agisse de Facebook, Messenger.com ou des applications mobiles Messenger (qui, elles, restent en place).
L’activation du stockage sécurisé se fait dans les paramètres de l’application, dans la section « Confidentialité et sécurité », puis dans « Discussions chiffrées de bout en bout ». Il faut alors se rendre dans « Stockage des messages » et activer l’option.