Le surinvestissement dans l’IA pourrait passer d’une « explosion » à un « effondrement »
Bubble tea

Un nouveau rapport de la banque des banques centrales analyse dans le détail les conséquences potentielles de la course à l’investissement dans l’IA. Il estime que le secteur est déjà en situation de surinvestissement, et que le mouvement en cours pourrait passer d’une « explosion » à un « effondrement » d’autant plus intense qu’il est financé par de multiples leviers financiers.
La « banque des banques centrales » l’avait laissé transparaître dès son rapport annuel. Lors de la publication du document, fin juin, la directrice adjointe de la Banque des règlements internationaux (BRI) Andrea Maechler avait listé auprès de l’AFP quatre points d’attention pour l’économie planétaire : l’inflation provoquée par le conflit au Moyen-Orient et la hausse des cours du pétrole, des plastiques ou encore des engrais, l’ « appétit exubérant pour le risque » des marchés financiers, les niveaux d’endettement élevés des États et… la course aux investissements dans l’intelligence artificielle.
Quelques jours plus tard, l’institution a publié le travail de l’un de ses économistes, Phurichai Rungcharoenkitkul, entièrement dédié à cette course. Sur 56 pages, celui-ci détaille les dynamiques d’investissement dans l’IA et les effets qu’elles pourraient avoir sur la stabilité financière. Et d’exprimer un constat clair : les surinvestissements constatés « exposent le secteur à une baisse des recettes qui pourrait transformer le boom » du secteur « en effondrement ». Et de préciser que « la course à l’engagement précoce par le biais de l’endettement et du financement circulaire augmente le risque d’effondrement ».
En d’autres termes, l’institution s’inquiète ouvertement de voir la course à l’IA dépasser de précédents booms technologiques qui s’étaient déjà, à l’époque, soldés par d’importantes perturbations de marché. Elle alerte sur le fait que les difficultés d’une seule entreprise pourraient « se répercuter sur d’autres par le biais de chaînes d’expositions financières ».
Des sur-investissements excessivement concentrés
Qu’une innovation technologique produise une vague d’investissements n’a rien de spécifique en soi. L’invention du rail, la multiplication de canaux financés par les États-Unis, même la bulle Internet des années 2000 ont, à des mesures variables, enregistré ce genre d’excitation financière. Le problème, constate néanmoins l’économiste, est qu’elles ont régulièrement enregistré des corrections plus ou moins sévères sur les marchés. Par ailleurs, comparé à « son niveau le plus bas avant le boom, le développement actuel [de l’IA] est en passe de dépasser tous les épisodes précédents en seulement trois ans ».
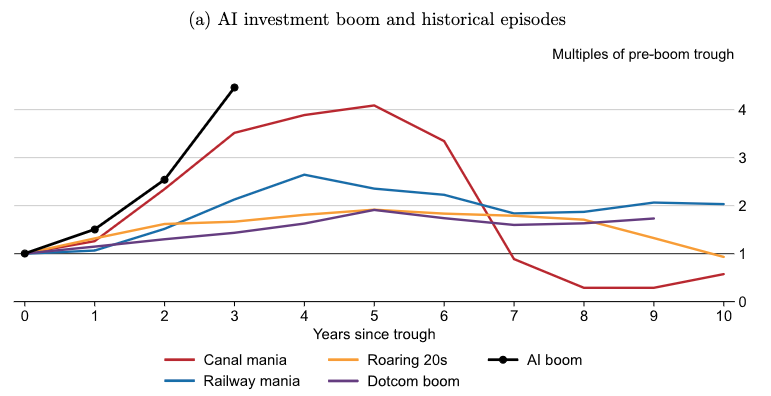
En s’appuyant sur les bilans des entreprises d’IA et les données publiques disponibles sur les transactions, l’économiste cherche à estimer l’ampleur des investissements réalisés. « La concentration du secteur offre une visibilité inhabituelle, bien qu’incomplète, sur la situation financière des entreprises », relève-t-il, avant d’estimer que les investissements réalisés dans l’industrie représentent « environ 1,5 fois l’optimum social », c’est-à-dire la meilleure répartition possible des actifs pour satisfaire au plus grand nombre. Dans certains cas de figure, ce surinvestissement peut grimper jusqu’à trois fois au-dessus du niveau le plus efficace d’allocation de capital, estime la BRI.
Cette lecture au prisme de l’efficacité économique fait écho à des travaux menés au prisme environnemental. Ainsi d’une récente étude menée par l’analyste Ketan Joshi sur les activités de Google dans le domaine de l’IA : début juillet, ce dernier calculait qu’en quelques années à peine, Google avait multiplié par 1,5 ses dépenses énergétiques pour dégager le même volume de chiffre d’affaires. Une explosion directement liée aux besoins d’infrastructures (des puces jusqu’aux centres de données) de l’IA.
Risque de « récession à l’échelle de l’ensemble de l’économie »
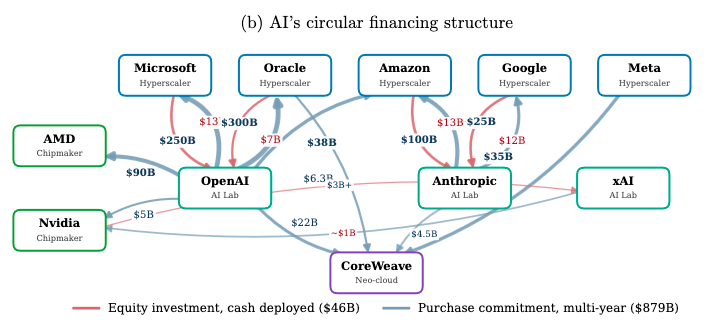
De fait, la concentration du secteur implique que les difficultés touchant l’une des sociétés de l’IA se répercutent à plusieurs niveaux de la chaîne de valeur : elles pourraient s’étendre aux constructeurs de centres de données, aux laboratoires d’IA, aux fabricants de puces ou encore aux fournisseurs de services cloud, pour commencer. D’après la BRI, cette dynamique constitue une vulnérabilité à part entière puisqu’un « choc subi par une société pourrait se propager et devenir systémique ».
L’explosion de l’IA « partage de nombreuses caractéristiques clé » observées dans des booms technologiques historiques, rappelle Phurichai Rungcharoenkitkul : les entrepreneurs investissent lourdement dans la nouvelle technologie dans l’espoir de « gagner » la course, leurs sociétés cherchant à obtenir des effets de levier capitalistique en recourant à de multiples modes de financement, tandis que l’important recours au financement spécialisé (le capital-risque) pourrait aggraver l’ampleur des pertes en cas de ralentissement économique.
Les cinq plus grands hyperscalers devraient allouer plus de mille milliards de dollars à de l’investissement dans l’IA sur la seule année 2026, calculait la BRI dans son rapport annuel (.pdf), un montant tiré à la fois par la surenchère entre concurrents et par la hausse du prix des mémoires. Or, ces montants dépassent largement leurs bénéfices comme leurs flux de trésorerie, ce qui les conduit à se tourner de plus en plus vers l’émission de titres de créance.
En définitive, la différence la plus notable entre la bulle actuelle et les précédentes se situe dans l’ampleur du phénomène actuellement à l’œuvre. Or, plusieurs des précédentes bulles de ce type ont entraîné « des récessions à l’échelle de l’ensemble de l’économie », alerte la BRI. Et d’insister sur le fait que la course actuelle présente des « risques de ralentissement à court terme ».
Le rapport est publié alors qu’aux États-Unis, terre d’origine de la poignée des sociétés les plus engagées dans cette course à l’investissement, la Réserve fédérale a créé un groupe de travail « Productivité et emplois » dédié notamment à étudier les impacts de l’IA générative sur ces domaines. Celui-ci intègre notamment plusieurs leaders du secteur, dont le capital-risqueur Marc Andreessen, l’ancien directeur de Microsoft CoreAI et l’économiste Charles Irving Jones, détaché chez Anthropic. Autant de liens directs avec l’industrie de l’IA qui interrogent sur l’indépendance réelle de la banque centrale des États-Unis.