ZEvent 2025 : concert, date, streamers, associations… ce qu’il faut retenir

Vous avez besoin d'une séance de rattrapage sur ce qu'est le ZEvent et ce qui est prévu pour l'édition 2025 ? Numerama vous récapitule les principaux points à connaître.
Vous avez besoin d'une séance de rattrapage sur ce qu'est le ZEvent et ce qui est prévu pour l'édition 2025 ? Numerama vous récapitule les principaux points à connaître.

Le célèbre chatbot d'OpenAI met désormais à disposition une option qui permet de créer des dossiers thématiques, dans lesquels on peut appliquer des règles spéciales à ChatGPT, sans polluer toutes les autres discussions.
L’intelligence artificielle (IA) fait couler de l’encre sur LinuxFr.org (et ailleurs). Plusieurs personnes ont émis grosso-modo l’opinion : « j’essaie de suivre, mais c’est pas facile ».
Je continue donc ma petite revue de presse mensuelle. Disclaimer : presque aucun travail de recherche de ma part, je vais me contenter de faire un travail de sélection et de résumé sur le contenu hebdomadaire de Zvi Mowshowitz (qui est déjà une source secondaire). Tous les mots sont de moi (n’allez pas taper Zvi si je l’ai mal compris !), sauf pour les citations : dans ce cas-là, je me repose sur Claude pour le travail de traduction. Sur les citations, je vous conseille de lire l’anglais si vous pouvez: difficile de traduire correctement du jargon semi-technique. Claude s’en sort mieux que moi (pas très compliqué), mais pas toujours très bien.
Même politique éditoriale que Zvi : je n’essaierai pas d’être neutre et non-orienté dans la façon de tourner mes remarques et observations, mais j’essaie de l’être dans ce que je décide de sélectionner ou non.
Petit glossaire de termes introduits précédemment (en lien : quand ça a été introduit, que vous puissiez faire une recherche dans le contenu pour un contexte plus complet) :
We are introducing GPT‑5, our best AI system yet. GPT‑5 is a significant leap in intelligence over all our previous models, featuring state-of-the-art performance across coding, math, writing, health, visual perception, and more. It is a unified system that knows when to respond quickly and when to think longer to provide expert-level responses. GPT‑5 is available to all users, with Plus subscribers getting more usage, and Pro subscribers getting access to GPT‑5 pro, a version with extended reasoning for even more comprehensive and accurate answers.
Traduction :
Nous présentons GPT-5, notre meilleur système d'IA à ce jour. GPT-5 représente un bond significatif en intelligence par rapport à tous nos modèles précédents, offrant des performances de pointe en programmation, mathématiques, rédaction, santé, perception visuelle, et bien plus encore. Il s'agit d'un système unifié qui sait quand répondre rapidement et quand prendre plus de temps pour fournir des réponses de niveau expert. GPT-5 est disponible pour tous les utilisateurs, les abonnés Plus bénéficiant d'une utilisation accrue, et les abonnés Pro ayant accès à GPT-5 pro, une version avec un raisonnement étendu pour des réponses encore plus complètes et précises.
Comme à l’accoutumée chez OpenAI, le modèle est accompagné de sa System Card.
La musique est bien connue à présent : chacun tour à tour, les trois gros acteurs (OpenAI/Anthropic/Google DeepMind) sortent un nouveau modèle qui fait avancer l’état de l’art, prenant la première place… jusqu’à ce qu’un des deux autres la reprenne en sortant le sien. C’est au tour d’OpenAI avec GPT-5.
Le nom a suscité beaucoup d’espoirs et de déceptions, beaucoup anticipant un saut qualitatif du même type que le passage de GPT-3 à GPT-4. Ce qui n’est absolument pas le cas : techniquement parlant, le modèle aurait pu s’appeler o4, représentant une amélioration incrémentale relativement à o3. L’objectif affiché d’OpenAI, derrière cette dénomination, est double : premièrement, de clarifier une offre extrêmement brouillonne (4o/o3/o3-pro/4.1/4.5) en offrant une dénomination unique avec des variantes plus claires, et offrir un modèle bien plus proche de l’état de l’art aux utilisateurs gratuit de ChatGPT.

Les benchmarks et la plupart des retours le placent comme une légère avancée de l’état de l’art, sans être une révolution. L’évaluation de METR résume parfaitement la situation ; une amélioration qui était parfaitement prévisible juste en extrapolant les tendances existantes :

Une amélioration notable est sur le taux d’hallucinations. Rappelons que o3 avait été un des seuls modèles à voir son taux d’hallucinations augmenter relativement à son prédécesseur ; avec GPT-5, OpenAI semble avoir corrigé le tir :

Sur la sécurité des modèles, aucune nouveauté notable relativement à o3. Les mitigations relatives aux risques biologiques/chimiques sont toujours en place, et comme à l’accoutumé OpenAI a fait appel à divers organismes tiers pour mesurer les risques posés par le modèle dans différentes catégories.
Et comme à l’accoutumée, Pliny the Liberator a jailbreak le modèle en quelques heures.
À noter que sur ChatGPT, OpenAI comptait complètement retirer l’accès aux anciens modèles, mais est revenu sur sa décision suite aux retours de beaucoup d’utilisateurs préférant le style plus chaleureux de 4o.
Un mois prolifique pour Google, qui publie trois nouveaux modèles / modes de fonctionnement.
Google Genie 3 est présenté comme un « World Model » (modèle du monde ?). À partir d’un prompt textuel, et d’actions de navigation de l’utilisateur, il génère en temps réel la vue de l’utilisateur, frame par frame (à la manière d’un jeu vidéo). Il n’y a pas de représentation explicite externe de l’état du monde : c’est le modèle qui se charge de garder une certaine cohérence d’une frame à l’autre (comme la persistance des objets). Au delà de la preuve de concept, l’objectif affiché est de créer des environnements d’entraînement virtuels pour la robotique.
Autre publication, celle de Gemini 2.5 Flash Image, le modèle de génération d’images de Google. S’il ne semble pas avancer l’état de l’art de manière générale, sa grande force semble être le suivi d’instructions (et de respect des références) pour l’édition d’images.
Le mois précédent, DeepMind avait reporté avoir décoché un score correspondant à une médaille d’or aux Olympiades Internationales de Mathématiques, une avancée permise notamment par une utilisation plus stratégique de la chaîne de pensée (et d’avancées correspondantes sur la partie entraînement par renforcement). Google publie une version plus rapide, moins coûteuse et moins performante (cette version n’obtient « que » un score correspondant à la médaille de bronze sur les mêmes Olympiades), sous la dénomination Gemini 2.5 Deep Think. Le modèle a sa propre System Card ; tout comme OpenAI et Anthropic, les capacités de ce modèle dans le domaine CBRN (biologie/nucléaire) a conduit Google à placer des gardes-fous supplémentaires pour empêcher des usages malveillants.
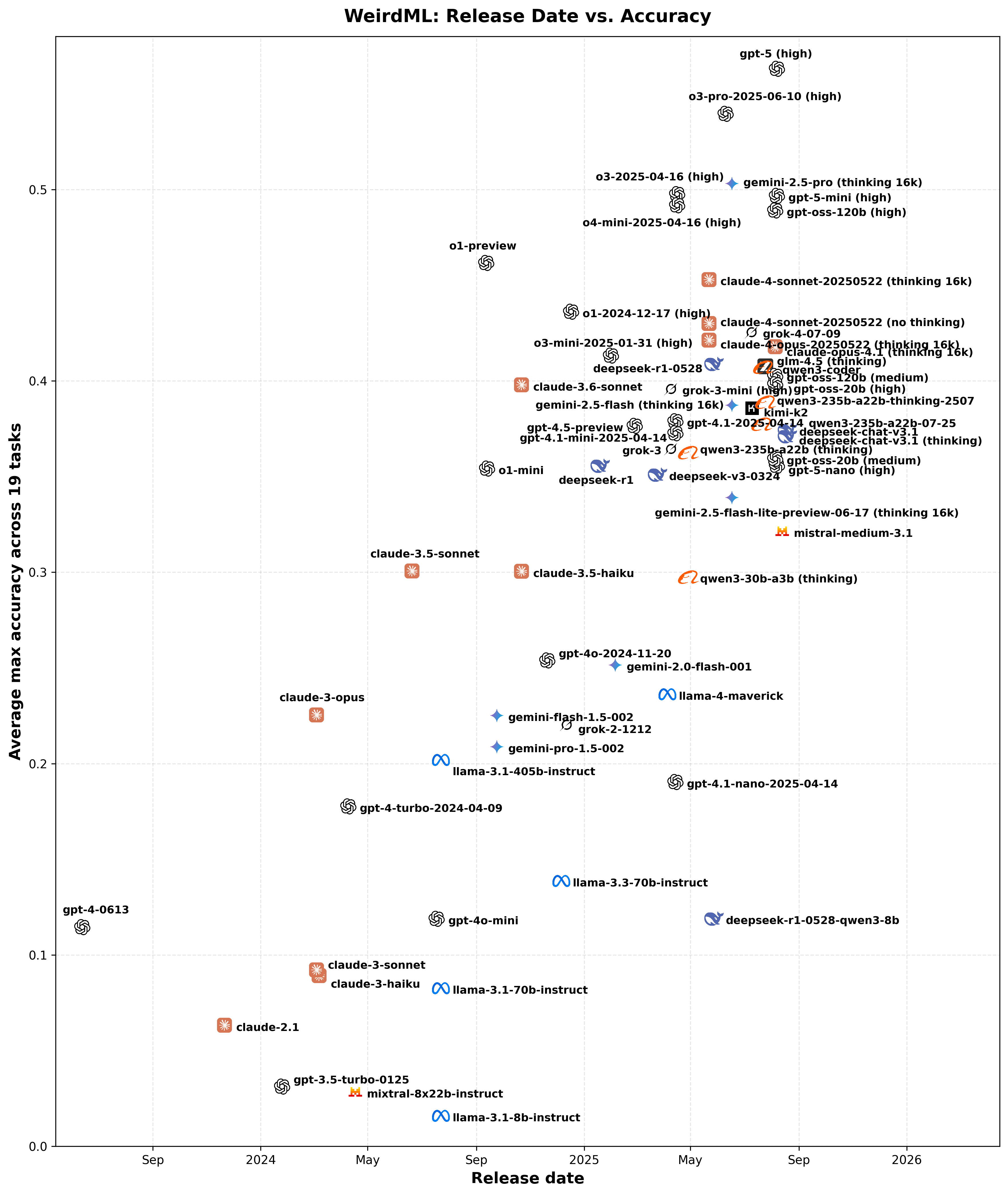
OpenAI publie son premier (depuis GPT-2, en 2019) modèle open-weight, gpt-oss. Au niveau des performances, il se placerait dans le peloton de tête des modèles open-weight, en compagnie de DeepSeek, Kimi, Qwen, GLM et Gemma, c’est à dire à peu près au niveau de la génération précédente des modèles entièrement fermés (comme Sonnet 3.6) / des versions rapides de la génération actuelle (Gemini 2.5 flash, o3-mini). WeirdML propose une visualisation intéressante sur leur propre benchmark pour vous donner un ordre d’idée. Rien de novateur au niveau de l’architecture, OpenAI s’en tient à la recette (maintenant universelle dans les modèles open-weight) d’une mixture d’experts. gpt-oss vient en deux variantes, la version complète, gpt-oss 120B, et une version plus légère et rapide, 20B.
Google publie un rapport sur l’impact environnemental de l’utilisation de Gemini. Cela exclu l’entraînement, mais les auteurs tentent de prendre en compte des coûts précédemment ignorés. Le résultat : 0,24 Wh d’électricité et 2,76 mL d’eau (le rapport initial mentionne 0,26 mL, mais sans comptabiliser l’eau utilisée pour générer les 0,24 Wh d’électricité) pour le prompt median (et l’équivalent de 0,03g de carbone émit).
Anthropic publie une nouvelle version de Opus, Opus 4.1. Comme la numérotation l’indique, il s’agit d’améliorations mineures — apparemment, un peu plus d’entraînement sur les tâches « agentiques » (utilisation d’outil) pour rendre Opus plus efficace sur ce type de tâches.
Similairement, DeepSeek publie une mise à jour « mineure » de son IA, DeepSeek v3.1. Les benchmarks fournis par DeepSeek semblent montrer un grand bond en avant, mais les quelques retours et benchmarks tiers ne corroborent pas ces prétentions — il s’agit probablement d’une mise à jour relativement mineure, comme la numérotation semble l’indiquer.
Nouvelle évaluation de l’IA, Prophet Arena. L’objectif est de permettre à l’IA de placer des positions virtuelles sur des marchés de prédiction, et de regarder ses performances. L’avantage de cette approche est de rendre complètement impossible la stratégie de juste mémoriser lors de l’apprentissage et régurgiter lors de l’évaluation : tout tâche est par essence nouvelle (car portant sur le futur). De plus, les résultats des marchés de prédiction forment un comparatif avec des prédictions par des utilisateurs humains. Résultat : les modèles les plus avancés (GPT-5, o3 Gemini 2.5 pro et Grok 4) dépassent les êtres humains sur le score de calibration, mais aucun n’arrive à traduire ça en de meilleurs retours financiers.
Anthropic se prépare à lancer Claude for Chrome, un plugin pour Google Chrome permettant à Claude d’interagir avec votre navigateur, à vos risques et périls.
En parallèle, les discussions sur claude.ai seront maintenant par défaut utilisées pour l’entraînement des versions suivantes de Claude, sauf si l’utilisateur désactive un paramètre sur son compte. Anthropic gardera les conversations pendant 5 ans.
Une nouvelle évaluation intéressante : TextQuests, qui évalue les modèles sur des jeux d’aventure textuels tels que Zork I. Cela a l’avantage de réellement tester les capacités de planification/raisonnement des modèles hors du domaine d’entraînement typique (mathématiques/programmation), tout en restant dans le domaine textuel (au contraire des évaluations multimodales, qui ont l’inconvénient de trop lier les résultats aux capacités perceptuelles des modèles).
Nouvelle technique d’interprétation des modèles, Model Diff Amplification. Elle consiste à amplifier les différences entre le pré-entraînement et le post-entraînement au moment de la génération, afin d’éliciter des comportements rares causés par le post-entraînement, ou tout simplement utiliser cette technique très tôt dans le post-entraînement pour se donner une idée des conséquences (prévues ou non) du post-entraînement complet.
Dr. Chistoph Heilig, chercheur en littérature et études bibliques, s’intéressant beaucoup aux capacités littéraires de l’IA, se met en tête d’évaluer GPT-5. Il se retrouve extrêmement surpris par la médiocrité de la prose produite par le modèle. De manière plus surprenante, un modèle complètement différent (Opus 4.1) juge le résultat comme étant de bonne qualité. La théorie qu’il propose est que ChatGPT 5 a été entraîné à l’aide d’un juge IA, et a appris à exploiter des constructions « peu humaines » que les modèles jugent systématiquement comme étant signes de qualité.
En parallèle de la sortie de GPT-5, OpenAI publie un guide sur comment créer un prompt, et un outil d’optimisation des prompts.
Anthropic et OpenAI font une tentative de coopération, où l’équipe d’évaluation de la sécurité des modèles d’OpenAI évalue les modèles d’Anthropic avec leurs outils, et vice-versa. Aucune trouvaille surprenante (si ce n’est l’incapacité des deux équipes de détecter la flagornerie flagrante de 4o), mais le concept est intéressante.
xAI publie la version précédente de son IA, Grok 2, en open-weight.
Une étude d’Anthropic développe un moyen pour identifier un sous-ensemble d’un modèle associé à un « trait de personnalité » particulier. Cela permet d’amplifier ou de supprimer ce trait, ou encore de détecter son activation.
« L’IA a-t-elle la qualité de patient moral » (en d’autres termes : devons-nous tenir compte de son bien-être pour des raisons morales) ? Anthropic commence à prendre la question au sérieux, avec comme première décision de permettre à son IA, Claude, d’unilatéralement mettre fin à une conversation qu’il jugerait abusive.
GPT-5 finit Pokémon Rouge en trois fois moins de temps que o3. La réduction du taux d’hallucinations serait la principale source de ce gain de performances. Gemini a également terminé sa partie de Pokémon Jaune. Claude, par contre, peine toujours à aller plus loin que Celadon…
La Chine continue à appeler à la coopération internationale pour la régulation du développement de l’IA, que ce soit par la voix du premier ministre ou d’universitaires.
Lors du sommet sur l’intelligence artificielle de Seoul de 2024, la plupart des acteurs, incluant Google, s’étaient volontairement engagés à suivre certaines actions relatives à la sécurité des modèles. Essentiellement, ce que le plupart faisaient déjà : publier une politique de sécurité des modèles, et s’engager à la suivre. Google se trouve aujourd’hui critiqué pour ne pas avoir suivi ses propres engagements. En cause, la publication de Gemini 2.5 Pro sans sa System Card associée, qui est arrivée plusieurs semaines après la publication du modèle. Google se défend en affirmant que la publication était clairement mentionnée comme « expérimentale ».
Entraîner l’IA à être chaleureuse et empathique réduit ses performances.
Sur le sujet de la flagornerie de l’IA, un internaute s’attelle à une évaluation des différents modèles.
Le gouvernement Danois veut faire rentrer l’apparence physique et la voix dans le cadre du copyright afin de lutter contre les deepfakes.
Voici d'autres ressources, qui n'ont pas été abordées dans cet article.
Commentaires : voir le flux Atom ouvrir dans le navigateur

Un démonstrateur d'arme laser d'une nouvelle génération sera bientôt fabriqué. D'abord destiné à détruire les drones menaçants, il sera aussi amené à terme à traiter des menaces plus dangereuses, comme les missiles.
Approuvé le 26 août 2025 par la Commission européenne, après un avis favorable du Comité des médicaments à usage humain (CHMP) de l’Agence européenne des médicaments (EMA), ce traitement injectable change la donne dans la prévention du VIH. Il est le fruit du développement du Sunlenca, également fondé sur le lenacapavir. Un traitement contre le sida commercialisé depuis août 2022 en Europe. C’est un inhibiteur de capside, qui bloque la réplication du VIH en s’attaquant à sa coque protectrice. Les essais cliniques, lancés en 2022, ont démontré son efficacité en prévention.
Le lenacapavir est administré par injection sous-cutanée tous les six mois, une révolution par rapport aux pilules quotidiennes de la PrEP (prophylaxie pré-exposition) classique, comme le Truvada. Les essais ont montré une efficacité impressionnante : 100 % de protection chez 5 300 jeunes femmes en Afrique du Sud et en Ouganda, et 96 % chez des hommes.
Lors du premier essai clinique, aucune infection n’a été enregistrée parmi les participantes sous lenacapavir, contre 2 % dans le groupe sous PrEP orale. En Europe, où entre 20 et 30 000 nouveaux cas de séropositivité sont diagnostiqués chaque année, ce traitement serait capable de les réduire drastiquement, notamment chez les populations vulnérables et à risques. En France, où près de 6 000 cas annuels persistent, le lenacapavir pourrait combler les lacunes de la prévention actuelle.
Malgré son potentiel, le lenacapavir n’est pas parfait. L’administration nécessite une infrastructure médicale pour les injections, un défi dans les zones rurales. De plus, des effets secondaires comme des nausées ou des nodules au site d’injection ont été rapportés.
Mais le principal obstacle à sa diffusion réside dans son coût. Aux États-Unis, les injections coûtent 28 000 à 42 000 dollars par an, rendant le traitement inabordable pour beaucoup. Une étude de l’université de Liverpool estime qu’une version générique pourrait coûter 40 dollars par an avec une production massive. Et Gilead est critiqué pour restreindre ces types de licences, limitant l’accès dans les pays à faibles revenus. L’ONG Médecins Sans Frontières et l’ONUSIDA exigent des licences ouvertes via le Medicines Patent Pool pour démocratiser l’accès. En Europe, où les systèmes de santé publics pourraient absorber les coûts, l’inégalité d’accès reste une préoccupation, notamment pour les populations marginalisées. Mais malgré son coût et les freins à la production de génériques, le lenacapavir s’annonce comme une réelle révolution dans la prévention du VIH. Enfin…
L’article VIH ! Go Yeztugo ! est apparu en premier sur Les Électrons Libres.

Des cas de suicide impliquant ChatGPT amènent OpenAI à revoir le fonctionnement du chatbot. Outre des efforts pour recadrer la façon dont le service traite de certaines discussions sensibles et difficiles, l'entreprise prévoit un contrôle parental.

Fruitz rebondit. L'application de rencontre, initialement condamnée à la nuit sur décision de son ancien propriétaire Bumble, va survivre. Les trois fondateurs reprennent la main.

La touche « Retour arrière » sur le clavier est bien pratique pour effacer ce que vous avez écrit. Mais si vous voulez supprimer beaucoup de texte, il y a une combinaison qui permet d'aller très vite.
Version 25.08 of the niri scrollable-tiling Wayland compositor has been released. Notable changes include xwayland-satellite integration, modal exit confirmation, and the introduction of basic support for screen readers:
A series of posts by fireborn earlier this year on the screen reader situation in Linux got me curious: how does one support screen readers in a Wayland compositor? The documentation is unfortunately scarce and difficult to find. Thankfully, @DataTriny from the AccessKit project came across my issue, pointed me at the right protocols, and answered a lot of my questions.
So, as of this release, niri has basic support for screen readers! We implement the org.freedesktop.a11y.KeyboardMonitor D-Bus interface for Orca to listen and grab keyboard keys, and we expose the main niri UI elements via AccessKit. [...]
The current screen reader support and further considerations are documented on the new Accessibility wiki page.
LWN covered niri in July.
Version 12.4 of Linux From Scratch (LFS) and Beyond Linux From Scratch (BLFS) have been released. LFS provides step-by-step instructions on building a customized Linux system entirely from source, and BLFS helps to extend an LFS installation into a more usable system. Notable changes in this release include updates to GNU Binutils 2.45, GCC 15.2, GNU C Library (glibc) 2.42, and Linux 6.15.1. See the Changelog for all updates since 12.3.
Des cas de suicide impliquant ChatGPT amènent OpenAI à revoir le fonctionnement du chatbot. Outre des efforts pour recadrer la façon dont le service traite de certaines discussions sensibles et difficiles, l'entreprise prévoit un contrôle parental.
Fruitz rebondit. L'application de rencontre, initialement condamnée à la nuit sur décision de son ancien propriétaire Bumble, va survivre. Les trois fondateurs reprennent la main.

Cet été, les équipes de Google ont publié deux alertes au sujet d’un nouveau type d’attaques d’utilisateurs du cloud. Alors qu’elles ciblaient les identifiants de salariés de Salesforce et Salesloft, et que les identifiants de 700 de leurs clients auraient été affectés, de nombreux médias les ont présentées à tort comme affectant l’ensemble des utilisateurs de Gmail. Debunk d’une rumeur.
La semaine passée, de nombreux médias ont repris une rumeur affirmant que Google aurait été victime d’une « cyberattaque » ayant « compromis » tout ou partie des 2,5 milliards de comptes Gmail et ayant entraîné une « fuite massive » de données. Ils enjoignaient les utilisateurs de Gmail à changer de mots de passe « en urgence ». Pour les articles francophones, cette thèse semble émaner de sites d’information générés par IA (GenAI, cf la colonne de gauche), qui avaient traduit en français des articles initialement parus en anglais.

Si Google avait bien communiqué, en décembre 2024, que Gmail comptait « plus de 2,5 milliards », il a fallu attendre ce 1er septembre pour que l’entreprise évoque cette supposée cyberattaque et compromission, en mode « damage control ».
« Nous voulons rassurer nos utilisateurs sur le fait que les protections de Gmail sont fortes et efficaces », souligne l’entreprise dans un court billet de blog intitulé « Les protections de Gmail sont solides et efficaces, et les allégations d’un avertissement de sécurité majeur de Gmail sont fausses » :
« Plusieurs affirmations inexactes ont récemment fait surface, affirmant à tort que nous avions émis un avertissement général à tous les utilisateurs de Gmail concernant un problème majeur de sécurité de Gmail. C’est entièrement faux. »
« Nos protections continuent d’empêcher plus de 99,9 % des tentatives de phishing et de logiciels malveillants d’atteindre les utilisateurs », ajoute Google, reprenant un chiffre évoqué fin 2024. Évoquant son investissement dans la cybersécurité, l’entreprise souligne qu’« Il est crucial que la conversation dans cet espace soit exacte et factuelle ». Ce qui n’a donc pas été le cas.
Après avoir renoncé à deux reprises à consacrer un article à cette fuite, faute d’éléments permettant de la confirmer, profitons de l’occasion pour revenir sur l’itinéraire de cette infox’, maintenant que nous en savons plus sur les entreprises réellement affectées.
Google ne le précise pas, mais la rumeur remonte à une alerte initialement publiée en juin dernier. Le Google Threat Intelligence Group (GTIG) y détaillait le modus operandi du groupe de pirates informatiques ShinyHunters (ou UNC6040). Accusé d’avoir « pompé l’équivalent de 200 millions de données d’une dizaine d’entreprises dans le monde », ce groupe serait en partie composé de Français.
L’un d’entre eux, extradé aux États-Unis, y a été condamné à trois ans de prison pour avoir volé les données d’une soixantaine d’entreprises, dont GitHub, Microsoft et AT&T, pour les revendre en ligne.
Cary Coutant has announced a draft for version 4.3 of the Executable and Linking Format (ELF) object file format. The specification was formerly part of the Unix System V Release 4 (SVR4) gABI document:
The last published gABI documents were the Fourth Edition and a draft of Edition 4.1, both published in March 1997. The ELF portions of the document were updated several times between 1998 and 2015, published online [...]
I've published the last draft from 2015 as Version 4.2, and collected the several changes since then, along with new e_machine values, as Version 4.3.
The source for the draft is on GitHub in reStructuredText format, and Coutant has collected the mailing list discussions for changes in 4.3 as GitHub issues. Thanks to Jose E. Marchesi for the tip.

Le démantèlement de Google et la dénonciation de certains contrats pouvaient constituer une menace existentielle pour l'avenir de Firefox, le navigateur web de Mozilla. Mais le verdict du procès antitrust visant le géant du web éloigne ce risque.

ChatGPT occupe désormais une place notable dans notre quotidien. Le chatbot d'OpenAI excelle pour des tâches parfois chronophages et permet de gagner beaucoup de temps. Mais il n'est pas la seule IA générative performante, une bonne nouvelle puisque ChatGPT n'est pas infaillible. En cas de panne, il existe plusieurs alternatives à ChatGPT à considérer. Voici les meilleures.

Une semaine après le 10e vol d'essai de sa fusée géante Starship, SpaceX a partagé des clichés supplémentaires du vaisseau dans l'espace.
La touche « Retour arrière » sur le clavier est bien pratique pour effacer ce que vous avez écrit. Mais si vous voulez supprimer beaucoup de texte, il y a une combinaison qui permet d'aller très vite.

Ce mercredi 3 septembre au matin, plusieurs centaines de signalements ont été faits sur la plateforme Down Detector pour une panne d'OpenAI et plus précisément, de ChatGPT. La panne a été confirmée par OpenAI.
{kind=link}