Freiner l’installation des data centers en France, pays de l’électricité bas carbone ? C’est le projet du Shift qui, après des prédictions ratées sur la 5G et le streaming, récidive avec de nouveaux scénarios alarmistes. Pourtant, le numérique tricolore est une opportunité pour la décarbonation de notre économie.
Le Shift Project persiste et signe. Dans son dernier rapport, le think tank fondé par Jean-Marc Jancovici estime que l’explosion mondiale de l’intelligence artificielle et de ses infrastructures va lourdement contribuer au réchauffement climatique. Et ses hypothèses ne lésinent pas sur les chiffres pharaoniques et anxiogènes. « Sans évolution majeure des dynamiques actuelles », il prédit un triplement de la consommation électrique des data centers à 1 250, voire 1 500 TWh à l’horizon 2030 (contre 400 TWh en 2020).
Des projections maximalistes, bâties sur les annonces des géants de l’intelligence artificielle et intégrant même le minage de cryptomonnaies, pourtant sans lien avec l’IA. Ainsi, le scénario le plus optimiste du Shift équivaut au plus pessimiste de l’Agence internationale de l’énergie, qui estime la fourchette entre 700 et 1 250 TWh.
Principal moteur : l’explosion de l’IA générative (700 millions d’utilisateurs hebdomadaires pour le seul ChatGPT, modèle d’OpenAI). Une situation qui conduirait, selon le think tank, à une augmentation des émissions de gaz à effet de serre (GES) de 9 % par an de la filière centres de données (au lieu d’une baisse annuelle de 5 % pour respecter les objectifs climatiques), dont l’essor repose encore massivement sur le gaz fossile, aux États-Unis et en Chine.
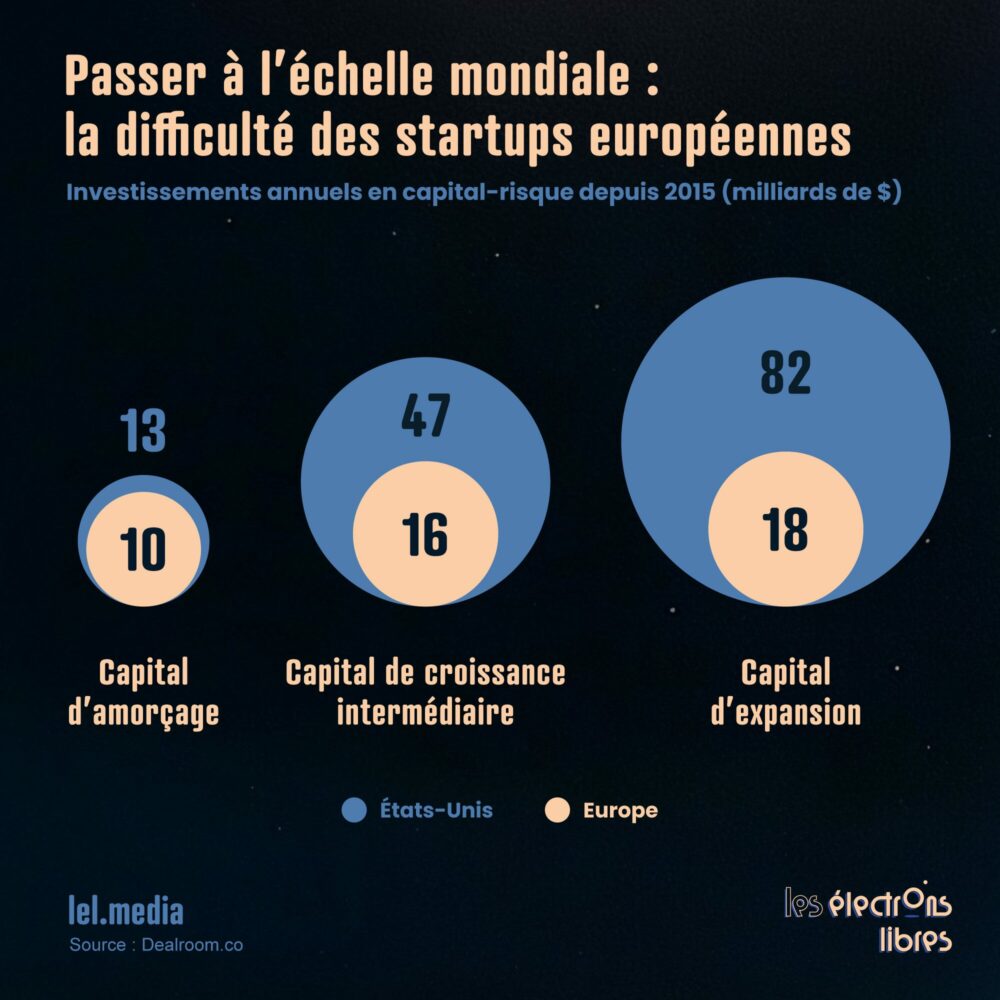
Le Shift estime donc « insoutenable » le développement mondial de ces infrastructures, à moins d’énormes efforts de décarbonation. Même prédiction pour l’Europe. Hugues Ferreboeuf, chef de projet Numérique, s’appuie sur le cas de l’Irlande où, suite à des incitations fiscales, la consommation des data centers est passée de 5 % à 20 % de l’électricité disponible. Un cas spectaculaire mais exceptionnel. À l’échelle de l’Union, cette part reste dix fois plus faible. Au point que le recours à cet exemple, peu représentatif des trajectoires européennes, interroge. D’autant que le Shift oublie de mentionner le Celtic Interconnector, qui permettra à la France d’exporter vers l’Irlande 700 MW de mix décarboné dès 2028, soit jusqu’à 6 TWh par an : l’équivalent de la consommation actuelle totale des data centers irlandais.
Le Shift y voit néanmoins un signal annonciateur et anticipe un doublement de la consommation électrique de la filière data centers européenne d’ici 2030, à 200 TWh. Ce qui, selon lui, risquerait de prolonger la dépendance de l’UE au GNL américain, que l’Europe importe pour compenser l’intermittence des énergies renouvelables. Que faire pour s’en prémunir ? Son constat est sans appel : il faut limiter le déploiement de l’IA « pour des usages ciblés et prioritaires ». Voire même l’interdire : « si ça ne suffit pas, on abandonne les fonctionnalités IA », assène sans trembler Maxime Efoui-Hess, coordinateur du programme « Numérique ».
Pourquoi cibler le champion français ?
À première vue, le raisonnement peut sembler logique. Mais le Shift ignore l’éléphant dans la pièce. Nous n’avons aucun moyen d’enrayer l’essor mondial des data centers, pas davantage que nous avons de prise sur l’empreinte carbone chinoise. Au mieux, ce lobbying peut freiner leur implantation en France. Or, avec une électricité parmi les plus décarbonées du monde et une obligation normative sur l’adoption de modèles économes en eau, notre pays figure parmi les meilleurs endroits pour les accueillir. Chaque data center installé ici, c’est un de moins qui tournera au charbon ou au gaz. Car leur nombre ne sera pas infini et qu’il s’agit d’un jeu à somme nulle.
Pauline Denis, ingénieure de recherche « Numérique » du Shift, pointe le risque de conflits d’usage. Selon elle, l’électricité captée par les data centers ne pourra pas servir à décarboner l’industrie. Pourtant, de l’électricité bas carbone, nous en avons plus qu’il n’en faut. La France a ainsi exporté 89 TWh en 2024, alors que ses centrales nucléaires étaient loin d’utiliser leur pleine capacité : 361 TWh, contre 430 en 2005 (418 en excluant Fessenheim).
Même si tous les projets annoncés lors du Sommet de l’IA voyaient le jour (109 milliards d’euros d’investissements), la consommation des data centers n’augmentera que de 25 TWh d’ici 2035, selon le Shift. Soit à peine 28 % de nos exportations actuelles. De quoi préserver, entre autres, la décarbonation des transports. Ainsi, les 40 à 50 TWh prévus pour les véhicules électriques resteraient couverts par notre excédent.
Malgré tout, ce surplus va-t-il vraiment « compromettre notre capacité à décarboner l’industrie » ? Ce pourrait bien être l’inverse. Faute de demande suffisante, nos centrales nucléaires fonctionnent en sous-régime, alors que leurs coûts fixes restent identiques. Résultat : des prix plus élevés qui freinent l’activité industrielle. Car, en réalité, notre consommation d’électricité recule année après année (–14 % en 20 ans), à rebours des scénarios de RTE et du Shift, qui n’en sont pas à une erreur prédictive catastrophiste près. Une hausse de la demande pourrait au contraire faire baisser les prix et enclencher un cercle vertueux d’électrification et de relocalisation.
Alors, vive les data centers made in France ? Toujours pas, selon Pauline Denis. Pour elle, « il faudrait prouver qu’installer 1 GW de data centers en France empêche l’installation d’1 GW ailleurs ». Sérieusement ?
Une longue tradition pessimiste et des scénarios fantaisistes
La méfiance du Shift Project envers le numérique ne date pas d’hier. Mais certaines de ses prédictions arrivent à échéance, et le constat est sévère. Début 2020, il annonçait que la 5G provoquerait 10 TWh de consommation supplémentaire en cinq ans, soit un doublement de toute l’activité des opérateurs français — fixe, mobile et data centers — et 2 % de la consommation nationale en plus. La réalité est toute autre. La hausse a été dix fois moindre et essentiellement liée à l’extension de la couverture en zones blanches, sans lien direct avec la 5G.
Même excès de sensationnalisme avec le streaming. Le Shift a relayé l’idée qu’une heure de visionnage équivalait à 12 km en voiture ou 30 minutes de four électrique. Une estimation huit à cinquante fois trop élevée selon l’IEA. Une erreur massive minimisée par le think tank. Faute d’erratum visible sur la page principale du rapport, le chiffre continue d’être repris dans les médias français.
L’efficacité exponentielle de l’IA
Après ces errements, faire des prévisions sur une technologie aux progrès aussi foudroyants que l’IA semble bien téméraire. Charles Gorintin, cofondateur des start-up Alan et Mistral AI, soulignait déjà en janvier dernier la double révolution du secteur : « l’efficacité des modèles d’IA a été multipliée par 1 000 en trois ans et celle des puces par 100 depuis 2008 ».
En deux mois, une simple mise à jour des drivers a permis à Nvidia de doubler les performances de ses GB200, avec un nouveau gain attendu en décembre, où ils ne seront alors exploités qu’à 42 % de leur capacité (contre 22 % aujourd’hui) ! Le modèle chinois Deepseek V 3.2 a multiplié par 50 en un an la vitesse de l’attention, phase clé de l’inférence (utilisation) qui pèse 40 à 60 % du coût d’une requête. Google mise sur des modèles « QAT » (Quantization-Aware Training), entraînés et utilisés en 4 bits plutôt qu’en 16. De son côté, Alibaba a conçu Qwen3 Next, aussi performant que les géants du secteur, mais capable de tourner sur une seule carte de calcul.
Même en ignorant les évolutions matérielles, les performances des modèles permettent de baisser à vitesse grand V leur consommation de ressources, donc d’énergie et d’émissions de CO₂, à l’entraînement comme à l’utilisation. Des optimisations qui ne sont pas prises en compte par les règles de trois de nos amoureux de la décroissance.
Numérisons les usages !
Le rapport du Shift surprend aussi par le peu d’analyse des externalités positives du numérique. La visioconférence, par exemple, a réduit les déplacements et les émissions associées. Interrogé sur ce point, Maxime Efoui-Hess affirme que « ce n’est pas mesurable » et que « rien ne montre que le numérique a permis de décarboner le monde », puisque « les émissions des pays numérisés augmentent ». Une première erreur, surprenante de la part d’un spécialiste. Les émissions des pays riches, les plus numérisés, baissent depuis 18 ans. Il invoque également l’effet rebond, estimant que « l’on imprime moins de presse, mais [qu’]il y a beaucoup plus de carton pour la livraison ». C’est encore une fois faux, puisque la consommation de papier et de carton a baissé de 26 % en France depuis l’an 2000.
Avoir recours à l’IA permet déjà d’optimiser la consommation énergétique des bâtiments et des processus industriels et de développer de nouvelles solutions pour la transition écologique. Par essence, tous les processus effectués virtuellement, avec une électricité décarbonée, sont moins émetteurs que leurs équivalents physiques. Il faudrait au contraire le scander. La numérisation des usages est la suite logique de leur électrification !
Maxime Efoui-Hess reconnaît à mi-mot que mettre le numérique et l’IA au service de la décarbonation est possible, « à condition de regarder usage par usage si c’est bien pertinent ». On ne sait pas si l’on doit rire d’une telle prétention, ou trembler d’une volonté de contrôle aussi décontractée.
L’article Numériser les usages ! Notre contrepoint au Shift est apparu en premier sur Les Électrons Libres.