Il est assez rare d’avoir le détail de l’infrastructure informatique d’une institution française. Au détour d’un appel d’offres, l’Agence nationale de sécurité du médicament détaille les systèmes d’exploitation et logiciels utilisés sur ses serveurs… certains ne sont plus à jour depuis de nombreuses années.
Au début de l’année, un appel d’offres pour un accord-cadre a été lancé pour l’hébergement des infrastructures informatiques et des prestations de services de l’ANSM, l’Agence Nationale de Sécurité du Médicament et des Produits de Santé. Cette agence se présente comme la « garante de la sécurité des patients ».
Via son appel d’offres consulté par Next, elle veut une « infrastructure évolutive et au plus près de « l’état de l’art », d’une richesse de niveaux de services (différentes classes de stockages, différentes classes de serveurs virtuels, …) payables à l’usage ». Le montant maximum de l’accord-cadre est de 3 millions d’euros sur quatre ans, en hausse par rapport aux 2,4 millions d’euros votés lors du conseil d’administration de l’été 2025.
Cette infrastructure doit avoir la capacité d’héberger des données de santé, et donc être certifiée HDS. Sur demande, l’hébergeur devra aussi être en mesure de proposer un hébergement qualifié SecNumCloud par l’ANSSI (et notamment d’assurer une étanchéité aux lois extraterritoriales). Le prestataire, s’il n’est pas lui-même HDS ou SecNumCloud, pourra passer par un partenaire.
5 points sur 100 pour « la démarche de souveraineté »
La qualification n’est pas immédiatement exigible, mais le prestataire « doit justifier, dès la présentation de son offre, de l’engagement formel de la démarche de qualification auprès de l’ANSSI, dite étape « J0 ANSSI » ». Ce jalon, rappelle l’Afnor, est « la validation par l’ANSSI d’un dossier de candidature. La phase d’évaluation avec audit sur site a lieu après la validation de ce jalon 0 ». Il y a ensuite J1, J2 et J3 à passer avant la qualification finale.
Il reste 87% de l'article à découvrir. Vous devez être abonné•e pour lire la suite de cet article. Déjà abonné•e ? Générez une clé RSS dans votre profil.
Nous avons passé à la moulinette du RAG le contenu de plus de 15 000 actus publiées sur Next ces dix dernières années. Le but ? En donner ensuite des morceaux à une IA générative pour qu’elle adapte ses réponses. Nous avons tout fait en local, sur un MacBook Pro avec Ollama et Mistral 7B.
Le Retrieval-Augmented Generation, ou génération augmentée par récupération en français, est une technique permettant à des IA génératives d’utiliser une base de connaissances pour répondre à des prompts. On utilise aussi très souvent son acronyme pour en parler : RAG.
Rag dans ma machine
Après les explications techniques et son principe de fonctionnement, nous vous proposons un exemple pratique. Nous avons récupéré le contenu de plus de 15 000 articles de Next sur une dizaine d’années pour l’associer à Mistral 7B, un LLM libre de 7,3 milliards de paramètres (sorti en 2023, désormais loin des ténors du moment qui ont au bas mot des centaines de milliards de paramètres, voire des milliers pour certains), sous licence Apache 2.0. Le RAG est agnostique du modèle d’IA générative, nous aurions évidemment pu en prendre un autre.
Dans notre cas, un traitement local était impératif. Nous avons utilisé un MacBook Pro avec un SoC M2 et 16 Go de mémoire partagée. Mistral 7B tourne dessus sans problème, avec de la marge pour exécuter d’autres applications en même temps. Côté logiciel, nous avons installé Ollama (open source, licence MIT). Nous l’avions déjà présenté dans un précédent tuto sur l’influence du GPU dans les performances des IA génératives.
Si les explications techniques ne vous intéressent pas, sautez directement à l’inter : « Concrètement, ça donne quoi d’utiliser le RAG ». Vous aurez des exemples de réponses à des prompts sur Mistral 7B avec et sans RAG (en local dans les deux cas).
Sous le capot pour la partie technique : Ollama, Mistral et Nomic
Passons rapidement (mais pas trop) sur les détails techniques, dont voici les grandes lignes : on télécharge le modèle d’IA générative avec la commande ollama pull mistral puis un autre modèle pour transformer le texte de nos actus en vecteurs (des nombres, qui sont ensuite utilisés par les algorithmes des IA génératives) avec ollama pull nomic-embed-text (on parle aussi d’embedding).
Un petit script permet de découper automatiquement le texte en plusieurs morceaux (chunks) qui sont ensuite transformés en tokens via nomic-embed-text. Cette indexation ne doit se faire qu’une seule fois. Dans notre cas, elle a pris environ trois heures (sur le MacBook Pro M2 avec plus de 15 000 articles). Pour ajouter de nouveaux articles par la suite, pas la peine de tout réindexer, il suffit de passer à la moulinette les nouveaux textes.
Passons aux choses sérieuses avec le déroulement d’un prompt. Le prompt est vectorisé, puis comparé à tous les vecteurs des morceaux des articles de notre base. Nous gardons les 10 meilleurs ; qui sont ensuite envoyés à Mistral en même temps que le prompt. Mistral va donc élaborer sa réponse en s’appuyant sur ses connaissances et les 10 morceaux des actus de Next.
On peut affiner le prompt pour lui demander de n’utiliser que les données de Next par exemple. Après, c’est un modèle statistique (comme toutes les IA génératives), donc statistiquement, il fait parfois n’importe quoi ; rien de neuf sous le Soleil.
Concrètement, ça donne quoi d’utiliser le RAG
Pour nos tests, nous utilisons donc Ollama sur notre MacBook Pro, sans aucune connexion à Internet, toutes les opérations se faisant en local.
Voici quelques prompts et les réponses de Mistral, avec ou sans RAG. Rappel important : nous n’avons pas spécialement cherché à optimiser les réponses (le prompt passé à Mistral avec le contenu des actualités jugé le plus intéressant pourrait être amélioré).
Nous vous proposons huit prompts, sur le logiciel, le droit, les réseaux sociaux, le hardware, l’informatique quantique… Les réponses sont, pour rappel, statistiques et peuvent donc par définition être totalement différentes pour un même prompt répété plusieurs fois. Nous livrons ici la première réponse proposée par l’IA générative.
Si vous avez des idées de prompts à tester, n’hésitez pas à les proposer en commentaire, suivant les cas je pourrai les lancer et donner les résultats dans une prochaine actualité
Passons aux choses sérieuses avec une première question soulevée par Vincent (il a la réponse, j’en suis certain ) ! Mais il est curieux de voir le résultat avec ou sans le contenu des actualités de Next… qu’il a pour la plupart rédigées.
Puis-je avoir une synthèse des défauts de Windows 11 ?
Réponse de Mistral avec RAG sur les actus Next :
Il reste 80% de l'article à découvrir. Vous devez être abonné•e pour lire la suite de cet article. Déjà abonné•e ? Générez une clé RSS dans votre profil.
Dans un communiqué publié le vendredi 26 juin dernier, l’Institut national de la statistique et des études économiques (Insee) annonce un incident de cybersécurité sur l’annuaire de ses agents, avec une fuite de données.
« Cette violation concerne l’identité d’environ 12 800 personnes travaillant, ayant travaillé à l’Insee ou issues des corps de l’Insee, ainsi que leurs coordonnées professionnelles ». L’institut affirme qu’aucun mot de passe, coordonnée personnelle ou bancaire, numéro de Sécurité sociale ou information de santé n’a été récupéré par les pirates.
Il ajoute n’avoir relevé aucune trace d’une « compromission des données collectées par l’Insee auprès des entreprises ou des personnes »… mais « l’institut recommande cependant aux entreprises comme aux particuliers la plus grande prudence en cas de réception d’un message qui semblerait provenir d’un agent de l’Insee ».
Comme la loi l’y oblige, l’incident a été signalé à la CNIL. L’Insee affirme aussi qu’une plainte a été déposée auprès du procureur de la République.
Illustration : Flock
L’Insee est le dernier d’une (trop) longue liste d’administrations et services de l’État piratés ces derniers mois. Il y a moins de deux semaines, c’était la plateforme JeVeuxAider.gouv.fr qui reconnaissait que « 550 000 comptes sont concernés par une extraction de données en lecture seule ». Cela concernait des noms, emails, numéros de téléphone, dates de naissance et historiques d’engagement des utilisateurs.
Dans un communiqué publié le vendredi 26 juin dernier, l’Institut national de la statistique et des études économiques (Insee) annonce un incident de cybersécurité sur l’annuaire de ses agents, avec une fuite de données.
« Cette violation concerne l’identité d’environ 12 800 personnes travaillant, ayant travaillé à l’Insee ou issues des corps de l’Insee, ainsi que leurs coordonnées professionnelles ». L’institut affirme qu’aucun mot de passe, coordonnée personnelle ou bancaire, numéro de Sécurité sociale ou information de santé n’a été récupéré par les pirates.
Il ajoute n’avoir relevé aucune trace d’une « compromission des données collectées par l’Insee auprès des entreprises ou des personnes »… mais « l’institut recommande cependant aux entreprises comme aux particuliers la plus grande prudence en cas de réception d’un message qui semblerait provenir d’un agent de l’Insee ».
Comme la loi l’y oblige, l’incident a été signalé à la CNIL. L’Insee affirme aussi qu’une plainte a été déposée auprès du procureur de la République.
Illustration : Flock
L’Insee est le dernier d’une (trop) longue liste d’administrations et services de l’État piratés ces derniers mois. Il y a moins de deux semaines, c’était la plateforme JeVeuxAider.gouv.fr qui reconnaissait que « 550 000 comptes sont concernés par une extraction de données en lecture seule ». Cela concernait des noms, emails, numéros de téléphone, dates de naissance et historiques d’engagement des utilisateurs.
Excusez-moi l’expression, mais « Putain, 30 ans » ! Il y a trois décennies, je trainais dans cette rue du 12ᵉ arrondissement de Paris, avec d’autres passionnés (certains diront fous furieux) à la recherche du bon prix pour un disque dur, du rab de mémoire, un contrôleur exotique… Aujourd’hui, qu’est-elle devenue ? Il reste des vestiges et des symboles de l’époque d’antan, mais…
Je vous parle d’un temps que les moins de 30 ans ne peuvent pas connaitre… que le temps passe vite ! Oui, quelques années avant le passage à l’an 2000 (pendant des années de fac), je trainais dans les recoins des boutiques de la fameuse (ou fabuleuse) rue Montgallet. Vous aussi ? N’hésitez pas à parler de vos souvenirs dans les commentaires !
Je doute qu’elle parle aux jeunes, mais elle rappelle sans aucun doute des souvenirs aux anciens (désolé pour le coup de vieux). Elle s’est montée dans le sillage de Surcouf, la « foire permanente de l’informatique » qui s‘est ouverte (transférée serait plus juste) en 1995 dans une avenue voisine, celle de Daumesnil, toujours dans le 12ᵉ arrondissement de Paris.
Deux classiques : « garantie jusqu’à la porte », « on prend pas les chèques »
À l’époque, la rue Montgallet était le temple de la bidouille et des composants informatiques, du plus classique au plus rare. Un processeur, de la mémoire, un disque dur, un câble SCSI, une carte contrôleur introuvable, un accessoire farfelu pour brancher un disque dur qui vient d‘on ne sait où… Dans certaines boutiques, des cartons regorgeaient d’accessoires en tout genre dans lesquels on pouvait passer des heures à fouiller.
Les prix des principaux composants étaient très souvent affichés au feutre sur un tableau blanc, mais ils n’étaient pas définitifs. Il était possible de gratter quelques euros suivant la quantité, le moyen de paiement (qui a tenté de payer par chèque ?), la régularité des commandes… et de bien d’autres paramètres qu’il ne vaut mieux pas lister ici.
1996, 2026, il existe encore quelques boutiques à l’ancienne :
Ceux qui y sont passés se souviennent certainement des deux maximes bien connues dans le coin : « Oui, garantie jusqu’à la porte » et « Non, on ne rembourse pas ». Cette dernière a d’ailleurs inspiré un clip au début des années 2000. Entre ça et Michel l’ingénieur informaticien ; pas de doute : les geeks de l’époque savaient s’amuser.
Il n’était pas rare d’acheter un graveur de CD ou un composant et de se le faire livrer dans un sachet électrostatique, sans sa boite d’origine. Il arrivait aussi parfois que ce ne soit pas la bonne référence… et là commençait la galère.
J’ai le souvenir d’un graveur de CD qui n’avait pas la bonne vitesse (genre 2x au lieu de x4). Pour avoir gain de cause, il a fallu que j’en appelle à la DGCCRF. Après un courrier, les choses sont très rapidement entrées dans l’ordre, il faut dire que les boutiques évitaient au maximum tout ce qui pouvait attirer l’œil d’institutions officielles (on ne se demande pas pourquoi).
Le repère de geek hardeux, avec leurs feuilles à la main
Il reste 63% de l'article à découvrir. Vous devez être abonné•e pour lire la suite de cet article. Déjà abonné•e ? Générez une clé RSS dans votre profil.
OpenAI présente sa première puce dédiée à l’inférence, développée avec Broadcom. L’entreprise affirme que les premiers tests se passent bien, mais ne donne aucun chiffre précis sur les performances, la consommation, etc. La photo d’un wafer permet de se lancer dans quelques analyses.
En octobre, nous apprenions qu’OpenAI et Broadcom travaillaient main dans la main pour développer des puces dédiées à l’intelligence artificielle. Contrairement aux GPU généralistes, il est ici question d’ASIC spécialisées.
Des algos à la puce, OpenAI passe en mode « full stack »
Ce n’est pas la première société à venir jouer sur les plates-bandes de NVIDIA. Google est déjà à sa huitième génération de TPU, Amazon et Microsoft sont aussi sur les rangs. C’est donc au tour d’OpenAI de se lancer. L’entreprise connait bien le sujet des IA génératives et de leurs besoins en calculs puisqu’elle était la première à se lancer avec ChatGPT (désormais en version 5.5).
Elle s’appuie sur la connaissance des LLM et de leurs besoins (passés, actuels et à venir) pour développer les fonctionnalités matérielles nécessaires. OpenAI se présente ainsi comme « full stack ». Sur la partie matérielle, le responsable d’OpenAI (Richard Ho) est un ancien de Google qui a passé plus de huit ans sur les TPU, il connait donc bien le sujet. Pour OpenAI, l’enjeu est double : se détacher de NVIDIA et de ses GPU, mais aussi avoir des puces plus spécialisées et optimisées afin de réduire la consommation (et donc le coût énergétique).
OpenAI affirme que sa « première génération d’accélérateurs offrira des performances par watt nettement supérieures à celles des accélérateurs de pointe actuels ». Sa puce a été « conçue dès le départ pour répondre aux besoins actuels et futurs des LLM », ceux d’OpenAI mais aussi les autres. Attention, cela ne veut pas dire que tout le monde pourra en profiter ; selon Reuters, les puces d’OpenAI seraient utilisées uniquement par OpenAI. Est-ce que ce sera une exclusivité totale, ou bien des puces seront-elles mises à disposition dans ses datacenters (comme le fait Google avec ses TPU) ? À voir…
OpenAI affirme que de premiers échantillons (samples) de Jalapeño « exécutent des charges de travail en machine learning en laboratoire à la fréquence et à la puissance prévues pendant la phase de production, y compris GPT‑5.3‑Codex‑Spark ». Aucun détail toutefois sur les performances ni sur les caractéristiques techniques.
On ne parle pour le moment que d’inférence, c’est-à-dire quand le modèle répond ; pas de la phase d’entrainement qui précède.
Caractéristiques techniques et performances ? Circulez, il n’y a rien à voir…
Il faut se contenter de promesses floues : « Bien qu’OpenAI mesure encore la performance finale, les premiers tests montrent que Jalapeño offrira des performances par watt nettement supérieures à l’état de l’art actuel ». Un rapport technique sera publié dans les prochains mois.
Hock Tan, président et CEO (équivalent de PDG) de Broadcom affirme qu’en « co-développant directement avec OpenAI notre puce de pointe, nous permettons le déploiement de centres de données à l’échelle du GW avec Microsoft et d’autres partenaires dès 2026 ».
Niveau partenariat, OpenAI cite également Broadcom sur la partie réseau avec son Tomahawk, dont la version 6 (102,4 Tb/s de bande passante totale) peut atteindre 1,6 Tb/s en Ethernet, 128 x 800 GbE, 256 x 400 GbE ou 512 x 200 GbE. C’est le double de la version 5, mais toujours sans savoir quelle version est utilisée.
Celestica est aussi cité comme partenaire, afin de « contribuer à l’industrialisation de la plateforme grâce à l’intégration de puces, de cartes, de baies, de réseaux haute performance et de systèmes de production évolutifs », précise OpenAI.
Maintenant que les présentations officielles sont faites, passons à la partie technique. Peu de données sont indiquées, mais la photo du wafer et de la puce d’OpenAI permet de se lancer dans quelques déductions et prospections.
Ce que nous apprend la photo officielle du wafer
Il reste 43% de l'article à découvrir. Vous devez être abonné•e pour lire la suite de cet article. Déjà abonné•e ? Générez une clé RSS dans votre profil.
Et de quatre augmentations… Lancée à 23,99 euros par mois, B&You Pure fibre Plus est désormais à 27,99 euros par mois. Nous avons décidé de refaire un tour des offres sans TV ni engagement à moins de 30 euros par mois avec RED by SFR, Sosh (Orange) et Free aux côtés de Bouygues Telecom. De quoi trouver l’offre qui vous conviendrait le mieux.
En novembre 2024, Bouygues Telecom mettait un coup de pied dans la fourmilière des offres fibres d’entrée de gamme avec son forfait Pure fibre à 23,99 euros par mois, sans engagement. Pour ce prix, de la fibre jusqu’à 8 Gb/s, et rien que de la fibre (pas de box TV, d’appels…).
Pure Fibre Plus : 23,99, 24,99, 25,99 et maintenant 27,99 euros par mois
En février, Bouygues Telecom « scindait » son offre en deux avec Pure Fibre à 2 Gb/s maximum (900 Mb/s en upload) et Pure Fibre Plus jusqu’à 8 Gb/s (1 Gb/s en upload), pour respectivement 24,99 et 25,99 euros par mois.
Lors du lancement, le fournisseur d’accès expliquait que les 8 Gb/s étaient disponibles via l’option « Débit + gratuite sur demande, sous réserve d’éligibilité et d’équipement compatible ». Plus qu’une segmentation, c’était la fin de la gratuité pour cette option.
Depuis, l’offre a augmenté à plusieurs reprises pour désormais arriver aujourd’hui à 27,99 euros par mois pour Pure fibre Plus (avec un débit théorique jusqu’à 8 Gb/s). L’offre Pure fibre (jusqu’à 2 Gb/s) est toujours à 24,99 euros par mois. Toutes les deux sont toujours sans engagement.
Qu’en est-il de la concurrence ? Nous avons fait un rapide tour d’horizon avec RED by SFR, Sosh (Orange) et Free avec sa Freebox Pop S. Point commun : pas d’engagement, un tarif de moins de 30 euros par mois (y compris au-delà de la première année) et pas de box TV.
B&You, RED (SFR), Sosh (Orange) et Free : notre tableau comparatif
Il reste 75% de l'article à découvrir. Vous devez être abonné•e pour lire la suite de cet article. Déjà abonné•e ? Générez une clé RSS dans votre profil.
Le Top500 permet de classer les machines les plus puissantes au monde. Elles doivent lancer des benchmarks et les envoyer pour être prises en compte. Un nouvel entrant arrive directement en première place (sans que ce soit une surprise) : LineShine, un supercalculateur chinois, sans GPU.
Le classement du Top500 se met à jour deux fois par an, en juin et novembre. La 67ᵉ édition vient d’être mise en ligne et, « pour la première fois depuis 2017, un système chinois domine le Top500 ». C’est un peu plus complexe, car depuis des années la Chine était aux abonnés absents. Selon plusieurs spécialistes, le pays resterait discret pour éviter que les États-Unis n’en profitent pour durcir les restrictions.
La Chine n’a que 31 machines dans le Top 500, mais écrase la concurrence
Jack Dongarra, cofondateur de Top500, expliquait durant l’été 2024 que « les Chinois ont des machines plus rapides, mais ils n’ont pas communiqué leurs résultats ». En juin 2020, 226 supercalculateurs chinois étaient présents dans le classement, contre 80 en juin 2024. Cette année, seules 31 machines sont dans le Top500.
Le Top 3 des pays comprend les États-Unis avec 161 supercalculateurs, le Japon avec 44 et l’Allemagne avec 41. La France est cinquième avec 21 machines, juste derrière la Chine qui occupe la quatrième place. Avec seulement 31 machines référencées, la Chine est tout de même 2ᵉ en puissance cumulée. C’est grâce à son supercalculateur LineShine, qui dépasse à lui seul le total des autres pays, sauf les États-Unis.
LineShine, nous en avions parlé en avril, quand le supercalculateur était apparu dans une publication scientifique. Elle n’était pas axée sur la machine, mais elle était utilisée pour entrainer un MLIP (Machine Learning Interatomic Potentials), avec des détails sur ses performances.
La barrière des 2 ExaFLOPS dépassée pour la première fois
La Chine a depuis décidé de transmettre les résultats de ses benchmarks au Top500 et elle prend donc la première place, avec une solide avance. Sur la base des données partielles de l’époque, nous avions estimé la puissance de calcul à 2,47 ExaFLOPS, nous n’étions pas loin.
LineShine est, quoi qu’il en soit, le premier supercalculateur à dépasser les 2 ExaFLOPS avec 2,198 ExaFLOPS pour être précis. Les États-Unis se bousculent derrière avec El Capitan à 1,809 ExaFLOPS, Frontier à 1,353 ExaFLOPS et enfin Aurora à 1,012 ExaFLOPS. L’Europe dispose d’une des cinq machines exaflopiques de ce classement avec JUPITER au centre de supercalcul de Jülich en Allemagne. Elle affiche une puissance de calcul de 1 ExaFLOPS tout juste.
Pas de GPU, c’est confirmé par le Top500
LineShine dispose de plus de 13,7 millions de cœurs CPU, des LX2 304C à 1,55 GHz dont nous avons déjà parlé. Le Top500 confirme l’absence de GPU : « Sur le benchmark HPL-MxP en précision mixte, LineShine a atteint 7,92 ExaFLOPS et se classe 4ᵉ. Un rapport de 3,6x modeste par rapport à son score HPL, qui indique une architecture exclusivement CPU, dépourvue d’accélérateurs dédiés à la basse précision ».
Les autres utilisent les GPU pour augmenter les performances en précision mixte. Sur le benchmark HPL-MxP (précision mixte), la première place revient à El Capitan avec 16,7 ExaFLOPS, soit un ratio de 9,2x par rapport à son score HPL. Aurora est deuxième avec 11,6 ExaFLOPS (ratio de 11,5x) et Frontière troisième avec 11,4 ExaFLOPS (ratio de 8,4x). LineShine n’est que quatrième avec 7,92 ExaFLOPS et un ratio de 3,6x, bien inférieur aux autres.
Le Top 10 a un autre nouvel entrant : HPC6, un supercalculateur HPE Cray EX235a avec plus de 3,1 millions de cœurs AMD EPYC de 3ᵉ génération et des Instinct MI250X en GPU. Sa puissance est de 0,6 ExaFLOPS. Il appartient à la société italienne Eni.
Green500 : la France toujours en tête, LineShine 50e
Terminons avec un mot sur le classement Green500, qui mesure les performances (sur le benchmark HPL) par watt d’énergie électrique consommée. La France est encore sur les deux premières places du podium avec KAIROS (CALMIP / Université de Toulouse – CNRS) et ROMEO-2025 (Centre HPC Bull). Les machines sont respectivement 445e et 192e au Top 500, mais la « faible » puissance électrique leur permet d’être en tête du Green500.
La France est également à la 9ᵉ place avec AMD Ouranos, tandis que l’Europe occupe bien le terrain avec neuf machines sur dix (si on compte Isambard-AI phase 1 au Royaume-Uni). Les États-Unis sont 10e avec Portage.
LineShine est 50ᵉ du Green500 avec une efficacité de 52,1 GigaFLOPS/watt, contre plus de 73 GigaFLOPS/watt pour KAIROS en tête de classement. El Capitan fait mieux avec la 28ᵉ place (60,9 GigaFLOPS/watt), Aurora 102ᵉ avec 26,1 GigaFLOPS/watt et enfin JUPITER 17ᵉ avec 63,3 GigaFLOPS/watt.
Le Top500 permet de classer les machines les plus puissantes au monde. Elles doivent lancer des benchmarks et les envoyer pour être prises en compte. Un nouvel entrant arrive directement en première place (sans que ce soit une surprise) : LineShine, un supercalculateur chinois, sans GPU.
Le classement du Top500 se met à jour deux fois par an, en juin et novembre. La 67ᵉ édition vient d’être mise en ligne et, « pour la première fois depuis 2017, un système chinois domine le Top500 ». C’est un peu plus complexe, car depuis des années la Chine était aux abonnés absents. Selon plusieurs spécialistes, le pays resterait discret pour éviter que les États-Unis n’en profitent pour durcir les restrictions.
La Chine n’a que 31 machines dans le Top 500, mais écrase la concurrence
Jack Dongarra, cofondateur de Top500, expliquait durant l’été 2024 que « les Chinois ont des machines plus rapides, mais ils n’ont pas communiqué leurs résultats ». En juin 2020, 226 supercalculateurs chinois étaient présents dans le classement, contre 80 en juin 2024. Cette année, seules 31 machines sont dans le Top500.
Le Top 3 des pays comprend les États-Unis avec 161 supercalculateurs, le Japon avec 44 et l’Allemagne avec 41. La France est cinquième avec 21 machines, juste derrière la Chine qui occupe la quatrième place. Avec seulement 31 machines référencées, la Chine est tout de même 2ᵉ en puissance cumulée. C’est grâce à son supercalculateur LineShine, qui dépasse à lui seul le total des autres pays, sauf les États-Unis.
LineShine, nous en avions parlé en avril, quand le supercalculateur était apparu dans une publication scientifique. Elle n’était pas axée sur la machine, mais elle était utilisée pour entrainer un MLIP (Machine Learning Interatomic Potentials), avec des détails sur ses performances.
La barrière des 2 ExaFLOPS dépassée pour la première fois
La Chine a depuis décidé de transmettre les résultats de ses benchmarks au Top500 et elle prend donc la première place, avec une solide avance. Sur la base des données partielles de l’époque, nous avions estimé la puissance de calcul à 2,47 ExaFLOPS, nous n’étions pas loin.
LineShine est, quoi qu’il en soit, le premier supercalculateur à dépasser les 2 ExaFLOPS avec 2,198 ExaFLOPS pour être précis. Les États-Unis se bousculent derrière avec El Capitan à 1,809 ExaFLOPS, Frontier à 1,353 ExaFLOPS et enfin Aurora à 1,012 ExaFLOPS. L’Europe dispose d’une des cinq machines exaflopiques de ce classement avec JUPITER au centre de supercalcul de Jülich en Allemagne. Elle affiche une puissance de calcul de 1 ExaFLOPS tout juste.
Pas de GPU, c’est confirmé par le Top500
LineShine dispose de plus de 13,7 millions de cœurs CPU, des LX2 304C à 1,55 GHz dont nous avons déjà parlé. Le Top500 confirme l’absence de GPU : « Sur le benchmark HPL-MxP en précision mixte, LineShine a atteint 7,92 ExaFLOPS et se classe 4ᵉ. Un rapport de 3,6x modeste par rapport à son score HPL, qui indique une architecture exclusivement CPU, dépourvue d’accélérateurs dédiés à la basse précision ».
Les autres utilisent les GPU pour augmenter les performances en précision mixte. Sur le benchmark HPL-MxP (précision mixte), la première place revient à El Capitan avec 16,7 ExaFLOPS, soit un ratio de 9,2x par rapport à son score HPL. Aurora est deuxième avec 11,6 ExaFLOPS (ratio de 11,5x) et Frontière troisième avec 11,4 ExaFLOPS (ratio de 8,4x). LineShine n’est que quatrième avec 7,92 ExaFLOPS et un ratio de 3,6x, bien inférieur aux autres.
Le Top 10 a un autre nouvel entrant : HPC6, un supercalculateur HPE Cray EX235a avec plus de 3,1 millions de cœurs AMD EPYC de 3ᵉ génération et des Instinct MI250X en GPU. Sa puissance est de 0,6 ExaFLOPS. Il appartient à la société italienne Eni.
Green500 : la France toujours en tête, LineShine 50e
Terminons avec un mot sur le classement Green500, qui mesure les performances (sur le benchmark HPL) par watt d’énergie électrique consommée. La France est encore sur les deux premières places du podium avec KAIROS (CALMIP / Université de Toulouse – CNRS) et ROMEO-2025 (Centre HPC Bull). Les machines sont respectivement 445e et 192e au Top 500, mais la « faible » puissance électrique leur permet d’être en tête du Green500.
La France est également à la 9ᵉ place avec AMD Ouranos, tandis que l’Europe occupe bien le terrain avec neuf machines sur dix (si on compte Isambard-AI phase 1 au Royaume-Uni). Les États-Unis sont 10e avec Portage.
LineShine est 50ᵉ du Green500 avec une efficacité de 52,1 GigaFLOPS/watt, contre plus de 73 GigaFLOPS/watt pour KAIROS en tête de classement. El Capitan fait mieux avec la 28ᵉ place (60,9 GigaFLOPS/watt), Aurora 102ᵉ avec 26,1 GigaFLOPS/watt et enfin JUPITER 17ᵉ avec 63,3 GigaFLOPS/watt.
Le premier système quantique d’Alice & Bob s’appelle Helium, une première étape avant une machine « universelle » tolérante aux erreurs… en quelque sorte. Une machine sera installée au CEA et portera le petit nom de Kitty ; un hommage aux qubits de chats utilisés par la start-up.
Menace quantique : rendez-vous en 2030
Cette semaine, Station F accueillait une nouvelle fois France Quantum, le rendez-vous des start-ups françaises du quantique. Plusieurs conférences étaient organisées afin de proposer des retours d’expérience, mais aussi de rappeler, une fois encore, que la menace est déjà réelle.
L’ANSSI, par exemple, réaffirmait le calendrier présenté par Vincent Strubel en octobre dernier. À partir de 2027, l’ANSSI n’acceptera plus en entrée de qualification des produits de sécurité qui n’intègrent pas une cryptographie résistante à l’ordinateur quantique. En 2030, « on recommandera et on imposera le cas échéant de ne plus acquérir de telles solutions ». 2030 est cité par certains comme une possible année charnière étant donné la progression actuelle.
Alice & Bob profitait du salon pour présenter Helium, son premier système tout-en-un avec 18 qubits de chat. Le CEA se porte d’ailleurs acquéreur (la machine s’appellera Kitty, une manière de rendre hommage aux chats), il rejoindra Lucy de Quandela (avec des photons pour qubits) et Ruby de chez Pasqal (avec des atomes neutres comme qubits).
Le calculateur quantique d’Alice et Bob est particulier car, explique le CEA, c’est « le premier système dit « early FTQC » (ou eFTQC), autrement dit un système quantique « tolérant aux fautes » », encore très précoce.
Tolérant… à moitié pour être précis, comme l’explique l’entreprise sur son stand. Pour simplifier, un qubit vaut donc 0 et 1 en même temps, mais il peut subir des erreurs et changer de phase sans qu’on lui demande (tous les qubits y sont sensibles, c’est un vrai problème).
Erreurs, bit et phase flips : l’avantage des qubits de chat
Il reste 66% de l'article à découvrir. Vous devez être abonné•e pour lire la suite de cet article. Déjà abonné•e ? Générez une clé RSS dans votre profil.
Remplacer les multiplications par des additions, telle est l’approche de Tensordyne pour augmenter de manière importante les performances des processeurs pour l’intelligence artificielle. Le fabricant utilise une « sauce secrète » et promet jusqu’à 13 fois plus de tokens par seconde que NVIDIA. On vous explique cette astuce.
L’IA : des centaines de milliards de calculs
Comme nous l’avons déjà expliqué dans un #Nextquick, une simple requête à une IA générative (via un grand modèle de langage) entraine déjà des centaines de milliards de calculs… au bas mot. GPT-3, avec ses 175 milliards de paramètres, représente environ 350 milliards de calculs par token… avec des multiplications et des additions. On peut généralement multiplier par deux le nombre de paramètres pour avoir une approximation du nombre de calculs.
Les GPU avec la parallélisation massive des calculs sont largement devant les CPU pour ce genre d’opérations. NVIDIA domine dans ce domaine, surtout pour entrainer de gros modèles. Il existe certes des concurrents avec des ASIC (notamment les TPU de Google), mais encore faut-il réussir à embarquer l’écosystème face à la plateforme à tout faire CUDA de NVIDIA (là encore, nous avons un Nextquick sur le sujet) qui s’est installée comme une référence et un standard de facto.
Tensordyne transforme les multiplications en additions
Tensordyne propose une autre approche, comme l’indique notamment CNET. Au lieu d’effectuer des calculs sur des nombres à virgule flottante – c’est-à-dire des nombres décimaux classiques comme 1,32 ou encore 0,78 –, la start-up germano-américaine passe dans le monde des logarithmes.
Ces nombres ont un avantage intéressant : une multiplication devient une addition, une opération moins coûteuse et qui demande moins de place sur un circuit électronique. Toutefois, effectuer une addition dans le monde des logarithmes est bien plus compliqué.
Vous avez des nœuds dans le cerveau ? Reprenons, calmement. Dans le monde des mathématiques classiques, une multiplication entre a et b sur un GPU coûte « plus cher » qu’une addition ; c’est plus complexe dans la pratique, mais simplifions au maximum dans le cadre de cet article.
V’la la tête d’une addition dans le monde des logarithmes…
Il reste 84% de l'article à découvrir. Vous devez être abonné•e pour lire la suite de cet article. Déjà abonné•e ? Générez une clé RSS dans votre profil.
OVHcloud, qui se présente désormais comme le « leader européen du Cloud et de l’IA », passe la seconde sur l’intelligence artificielle et va lancer sa famille de modèles (LLM). En open source ? « c’est effectivement l’idée » affirme Octave Klaba.
Octave Klaba, qui a repris les rênes d’OVHcloud fin 2025, profite du salon VivaTech pour faire part de ses ambitions dans le monde de l’intelligence artificielle et des grand modèles de langage : « il nous est apparu très clairement que si nous ne maîtrisions pas cette technologie, nous ne pourrions pas garantir notre avenir », explique-t-il à Reuters. La maitrise passe par plusieurs étapes.
OVHcloud fait ses courses dans les start-ups françaises
Depuis des mois déjà, l’entreprise prépare le terrain. Au début de l’année, elle croquait Seald, une « entreprise française spécialisée dans les technologies de chiffrement de bout en bout ». La fonctionnalité mise en avant par l’hébergeur dans son communiqué : « Le SDK développé par Seald, bénéficiant d’un visa de sécurité CSPN délivré par l’ANSSI, permet d’intégrer rapidement le chiffrement de bout en bout dans des applications web et mobiles, sans expertise cryptographique avancée ».
En mars, c’était une autre société française qui tombait dans son giron : Dragon LLM, qui « conçoit des modèles spécialisés d’IA générative et souverains ». Selon OVHcloud, le but de cette société est de « bâtir une IA européenne utile, responsable et efficiente ». Le Roubaisien en profite pour renforcer ses équipes avec de nouveaux experts dans le fine-tuning, une technique consistant à « spécialiser un modèle d’IA pré-entraîné à l’accomplissement d’une tâche spécifique », explique la CNIL. On parle aussi d’ajustement.
Il y a quelques jours, OVHcloud est entrée en négociations exclusives pour racheter Gladia, une autre startup française spécialisée cette fois dans l’IA vocale. Depuis le mois de mai, OVHcloud a changé son discours dans ses communiqués de presse. Alors qu’il se présentait jusque là comme « leader européen du cloud », il ajoute désormais « et de l’IA » (ou de l’AI, il y a les deux).
OVHcloud prépare une famille de modèles
En plus de renforcer ses équipes, ce serait aussi le bon timing pour se lancer dans les modèles d’IA pour OVHcloud car « un projet qui aurait autrefois coûté environ un milliard d’euros pourrait désormais être entrepris pour un budget de 150 à 200 millions d’euros », comme le précisent nos confrères en se basant sur des déclarations d’Octave Klaba. OVHcloud représenterait la deuxième vague d’acteurs, après les historiques que sont OpenAI, Anthropic et Mistral pour ne citer que ces trois-là.
Le Roubaisien prévoit de lancer une famille de modèles afin de répondre à différents cas d’usage, une pratique courante. Chez Anthropic par exemple, il y a Opus, Sonnet et Haiku. OpenAI a ses modèles GPT et o, etc. Il existe aussi une approche intermédiaire avec les mixtures d’experts ou MoE.
OVHcloud va-t-elle aller vers de l’open source ? « Nous regarderons à quel moment nous serons suffisamment bons pour pouvoir les open sourcer. Mais c’est effectivement l’idée ».
Reste la question des GPU pour entrainer les modèles. En novembre dernier, Octave Klaba se montrait prudent : « La vraie question derrière les GPU, c’est le business model. La problématique aujourd’hui, c’est que tous ceux qui investissent ne savent pas encore s’ils vont les rentabiliser » ; en cause, le cycle de renouvellement très rapide avec NVIDIA qui double ou presque les performances à chaque génération. Récemment, il a comparé les GPU à des fraises : « vous les achetez vous devez les manger le jour même, le lendemain elles sont pourries ». Pour entraîner de gros modèles, pas le choix, il en faut des fraises, et pas qu’une barquette.
Fin 2025, lorsqu’Octave Klaba avait repris la direction d’OVHcloud, il expliquait que c’était pour aller plus vite : « le contexte géopolitique, l’essor du marché du cloud et de l’IA nous demandent de nous développer plus rapidement afin de garder un temps d’avance. C’est la raison pour laquelle, le conseil d’administration a décidé de rapprocher vision, stratégie et exécution ».
OVHai Workspace : de l’IA agentique à tous les étages
Lors de l’OVH Summit 2025, la couleur était donnée : « tous nos produits ont une teinte IA. On va introduire de l’agentique » avec des comptes rendus d’appel, la rédaction et la lecture d’emails. Il était question de mettre l’IA au centre des postes de travail.
C’est le sens de l’annonce d’OVHai Workspace, une plateforme AI agentique collaborative et ouverte lancée par OVH Labs. Elle « permet le développement et l’intégration d’applications afin de profiter de l’IA agentique et du chiffrement de bout en bout disponible nativement ». Les acquisitions des derniers mois et notamment celle de Seald prennent alors tout leur sens.
Freedom to Collaborate.
16 postes de démo et des experts OVHcloud pour vous montrer comment l'IA, les outils collaboratifs et la sécurité peuvent fonctionner ensemble dans une plateforme ouverte. Venez tester ! #VivaTechpic.twitter.com/Iw1N4Hs44O
« OVHai Workspace intègre un moteur de recherche couplé à des capacités d’IA agentique. Automatiser des actions complexes, rechercher des informations dans plusieurs applications distinctes ou simplifier les tâches répétitives sont ainsi possibles en un clic », explique l’entreprise.
Email, drive et visioconférences dans une « expérience unifiée », telle est la promesse d’OVHai. La plateforme est pour le moment en preview (accessible uniquement sur le stand OVHcloud à Vivatech), « avant une bêta dont le lancement est prévu lors de l’OVHcloud Summit en novembre », précise Octave Klaba.
OVHcloud, qui se présente désormais comme le « leader européen du Cloud et de l’IA », passe la seconde sur l’intelligence artificielle et va lancer sa famille de modèles (LLM). En open source ? « c’est effectivement l’idée » affirme Octave Klaba.
Octave Klaba, qui a repris les rênes d’OVHcloud fin 2025, profite du salon VivaTech pour faire part de ses ambitions dans le monde de l’intelligence artificielle et des grand modèles de langage : « il nous est apparu très clairement que si nous ne maîtrisions pas cette technologie, nous ne pourrions pas garantir notre avenir », explique-t-il à Reuters. La maitrise passe par plusieurs étapes.
OVHcloud fait ses courses dans les start-ups françaises
Depuis des mois déjà, l’entreprise prépare le terrain. Au début de l’année, elle croquait Seald, une « entreprise française spécialisée dans les technologies de chiffrement de bout en bout ». La fonctionnalité mise en avant par l’hébergeur dans son communiqué : « Le SDK développé par Seald, bénéficiant d’un visa de sécurité CSPN délivré par l’ANSSI, permet d’intégrer rapidement le chiffrement de bout en bout dans des applications web et mobiles, sans expertise cryptographique avancée ».
En mars, c’était une autre société française qui tombait dans son giron : Dragon LLM, qui « conçoit des modèles spécialisés d’IA générative et souverains ». Selon OVHcloud, le but de cette société est de « bâtir une IA européenne utile, responsable et efficiente ». Le Roubaisien en profite pour renforcer ses équipes avec de nouveaux experts dans le fine-tuning, une technique consistant à « spécialiser un modèle d’IA pré-entraîné à l’accomplissement d’une tâche spécifique », explique la CNIL. On parle aussi d’ajustement.
Il y a quelques jours, OVHcloud est entrée en négociations exclusives pour racheter Gladia, une autre startup française spécialisée cette fois dans l’IA vocale. Depuis le mois de mai, OVHcloud a changé son discours dans ses communiqués de presse. Alors qu’il se présentait jusque là comme « leader européen du cloud », il ajoute désormais « et de l’IA » (ou de l’AI, il y a les deux).
OVHcloud prépare une famille de modèles
En plus de renforcer ses équipes, ce serait aussi le bon timing pour se lancer dans les modèles d’IA pour OVHcloud car « un projet qui aurait autrefois coûté environ un milliard d’euros pourrait désormais être entrepris pour un budget de 150 à 200 millions d’euros », comme le précisent nos confrères en se basant sur des déclarations d’Octave Klaba. OVHcloud représenterait la deuxième vague d’acteurs, après les historiques que sont OpenAI, Anthropic et Mistral pour ne citer que ces trois-là.
Le Roubaisien prévoit de lancer une famille de modèles afin de répondre à différents cas d’usage, une pratique courante. Chez Anthropic par exemple, il y a Opus, Sonnet et Haiku. OpenAI a ses modèles GPT et o, etc. Il existe aussi une approche intermédiaire avec les mixtures d’experts ou MoE.
OVHcloud va-t-elle aller vers de l’open source ? « Nous regarderons à quel moment nous serons suffisamment bons pour pouvoir les open sourcer. Mais c’est effectivement l’idée ».
Reste la question des GPU pour entrainer les modèles. En novembre dernier, Octave Klaba se montrait prudent : « La vraie question derrière les GPU, c’est le business model. La problématique aujourd’hui, c’est que tous ceux qui investissent ne savent pas encore s’ils vont les rentabiliser » ; en cause, le cycle de renouvellement très rapide avec NVIDIA qui double ou presque les performances à chaque génération. Récemment, il a comparé les GPU à des fraises : « vous les achetez vous devez les manger le jour même, le lendemain elles sont pourries ». Pour entraîner de gros modèles, pas le choix, il en faut des fraises, et pas qu’une barquette.
Fin 2025, lorsqu’Octave Klaba avait repris la direction d’OVHcloud, il expliquait que c’était pour aller plus vite : « le contexte géopolitique, l’essor du marché du cloud et de l’IA nous demandent de nous développer plus rapidement afin de garder un temps d’avance. C’est la raison pour laquelle, le conseil d’administration a décidé de rapprocher vision, stratégie et exécution ».
OVHai Workspace : de l’IA agentique à tous les étages
Lors de l’OVH Summit 2025, la couleur était donnée : « tous nos produits ont une teinte IA. On va introduire de l’agentique » avec des comptes rendus d’appel, la rédaction et la lecture d’emails. Il était question de mettre l’IA au centre des postes de travail.
C’est le sens de l’annonce d’OVHai Workspace, une plateforme AI agentique collaborative et ouverte lancée par OVH Labs. Elle « permet le développement et l’intégration d’applications afin de profiter de l’IA agentique et du chiffrement de bout en bout disponible nativement ». Les acquisitions des derniers mois et notamment celle de Seald prennent alors tout leur sens.
Freedom to Collaborate.
16 postes de démo et des experts OVHcloud pour vous montrer comment l'IA, les outils collaboratifs et la sécurité peuvent fonctionner ensemble dans une plateforme ouverte. Venez tester ! #VivaTechpic.twitter.com/Iw1N4Hs44O
« OVHai Workspace intègre un moteur de recherche couplé à des capacités d’IA agentique. Automatiser des actions complexes, rechercher des informations dans plusieurs applications distinctes ou simplifier les tâches répétitives sont ainsi possibles en un clic », explique l’entreprise.
Email, drive et visioconférences dans une « expérience unifiée », telle est la promesse d’OVHai. La plateforme est pour le moment en preview (accessible uniquement sur le stand OVHcloud à Vivatech), « avant une bêta dont le lancement est prévu lors de l’OVHcloud Summit en novembre », précise Octave Klaba.
Nous non plus, on n’aime pas trop se comparer à Palantir…
L’actualité est chargée autour de ChapsVision, une société française spécialisée dans l’analyse et la surveillance. En plus de prendre la place de Palantir à la DGSI, elle vient de signer un partenariat avec Scaleway. Nous avons échangé avec plusieurs membres de l’équipe de ChapsVision (dont le directeur général Silvano Sansoni) sur les projets en cours, sa plateforme, ses ambitions.
ChapsVision migre chez Scaleway (en cours de qualification SecNumCloud)
Pour le premier jour du salon Vivatech à Paris, Scaleway et ChapsVision annoncent un partenariat. Dans les faits, il s’agit pour ChapsVision de migrer dans les datacenters de l’hébergeur français. Les détails financiers du contrat ne sont pas précisés, tout juste savons nous que Scaleway sera à terme le seul hébergeur de ChapsVision (serveurs, stockage, puissance de calcul…).
« C’est la situation que je considère comme idéale. C’est de la souveraineté avec deux acteurs français et sécurisés, notamment avec Scaleway qui est SecNumCloud »… mais ce n’est pas (encore) le cas, l’entreprise figurant toujours dans la liste des prestataires en cours de qualification selon le site de l’ANSSI.
Scaleway a, pour rappel, validé le jalon J0 en janvier 2025, mais n’a pas obtenu le sésame de l’ANSSI pour le moment, comme nous confirme Damien Lucas, le CEO de Scaleway. Une annonce « visionnaire » de la ministre ? Réponse dans les semaines ou mois à venir.
Palantir + ChapsVision à la DGSI ? Oui, le « temps de faire la transition »
Nous profitions d’avoir ChapsVision sous la main pour revenir sur le contrat remporté avec la DGSI, comme vient de l’annoncer Sébastien Lecornu, pour prendre la place de Palantir : « On a gagné le lot deux du projet Outil de traitement des données hétérogènes (OTDH). L’appel d’offres a commencé il y a cinq ans, on avait gagné le lot un l’année dernière ».
Il reste 69% de l'article à découvrir. Vous devez être abonné•e pour lire la suite de cet article. Déjà abonné•e ? Générez une clé RSS dans votre profil.
En plus de faire réagir toute la classe politique, la coupure des derniers modèles d’Anthropic remet en avant des questions de souveraineté et d’autonomie. Pour le Conseil de l’IA, « la menace sur l’autonomie numérique européenne n’est plus une hypothèse, elle est devenue une réalité tangible ».
Dans une note publiée quelques jours seulement après la coupure de Mythos 5 et de sa version pour le grand public Fable 5, le Conseil de l’IA et du Numérique évoque un « point de bascule ». Le terme est peut-être fort, mais cette coupure a été l’occasion d’éveiller les esprits sur les questions de souveraineté et de rappeler notre dépendance à des technologies américaines.
Pour le Conseil, cette suspension soudaine « révèle en réalité des tendances de fond sur l’intelligence artificielle (IA), qui s’amplifient depuis déjà un certain temps ». Il affirme que la maîtrise des dépendances technologiques doit devenir une priorité dans le numérique.
Les enjeux de souveraineté numérique, les membres du Conseil le connaissent bien, déjà par le biais de ses deux co-présidents : Anne Bouverot (ex-Orange, présidente du conseil d’administration de l’ENS) ainsi que Guillaume Poupard (ex-patron de l’ANSSI, CTO d’Orange). Sébastien Soriano et Patrick Chaize sont également membres du Conseil.
Kill switch : jour, nuit, jour, nuit…
Cette coupure des deux modèles est la matérialisation d’une menace régulièrement évoquée : un kill switch. La question se posait déjà lors de la mise en place de S3ns et Bleu, des clouds basés sur les technologies de Google et Microsoft, mais sous le contrôle et la maîtrise d’entreprises françaises. S3ns est d’ailleurs qualifié SecNumCloud par l’ANSSI, la plus haute certification.
La question était de savoir ce qu’il se passerait si Google ou Microsoft fermaient le robinet et arrêtaient d’envoyer des mises à jour. Les cloud continueraient de fonctionner, mais sans nouvelles fonctionnalités, ni correctifs de bugs ou de sécurité. C’est certainement le point le plus sensible.
Nous avions évoqué le sujet avec les deux entités. S3ns pense pouvoir tenir quelques mois, Bleu pousse à un an et pourrait proposer à ses clients des liaisons directes afin de « fonctionner en autarcie », totalement isolé d’Internet.
Les précédents : Adobe au Venezuela, le juge de la CPI Nicolas Guillou
Comme nous l’avons vu avec l’intelligence artificielle générative, le kill switch d’Anthropic a coupé les modèles à l’ensemble des clients, partout dans le monde. Ce n’est pas une première. En octobre 2019, « Adobe avait suspendu ses services – notamment l’ouverture de documents PDF – au Venezuela à la suite d’un Executive Order signé par l’administration Trump ».
Rappelons aussi le cas Nicolas Guillou, juge français de la Cour pénale internationale qui « n’a plus accès aux services numériques développés outre-Atlantique ». Le principal intéressé avait expliqué que l’Europe était (est encore) en situation de « vassalisation, dans un contexte de déclin de l’ordre mondial ».
Pour le Conseil de l’IA, « les restrictions imposées sur les deux modèles les plus avancés d’Anthropic marquent une étape supplémentaire, significative et inédite vers la généralisation pratique de ce risque ». Si le numérique est depuis toujours un enjeu de pouvoir, les LLM deviennent des actifs stratégiques.
Washington veut s’éviter un nouveau « moment DeepSeek »
Il ajoute que cette mesure « prolonge la stratégie de containment (endiguement) technologique, jusqu’ici principalement incarnée par les restrictions à l’exportation des puces NVIDIA les plus performantes » sur le marché chinois.
Le but est évident pour les États-Unis : tenter de garder cette avance pour eux afin que ses entreprises technologiques en profitent en premier, voire en exclusivité. Le gouvernement américain veut ainsi s’« éviter un nouveau « moment DeepSeek », qui avait fortement marqué les esprits à Washington ».
En bloquant les puces, les États-Unis entendent limiter les capacités d’entraînement des plus gros modèles ; avec des restrictions sur des modèles, ils veulent « limiter les risques de distillation hostile ». Selon la note, c’est grâce à la distillation que « des laboratoires chinois, comme DeepSeek, ont très certainement pu combler une grande partie de leur retard sur les modèles américains par le passé ».
Cette histoire entre en collision avec la « promesse d’une « IA pour tous » au service du bien commun », sans oublier les questions de coûts : « l’accès aux IA performantes est jusqu’à présent très largement subventionné », avec des forfaits qui seraient bien en deçà du coût réel.
Des sociétés comme OpenAI et Anthropic n’ont de cesse de vanter les performances de leurs modèles, rappelant à qui veut l‘entendre qu’ils ne doivent pas être mis entre toutes les mains (l‘Executive Order de Donald Trump va dans ce sens).
Pour le Conseil, c’est le « retour en force de la doctrine du risque catastrophique, voire existentiel, associé à l’IA »… qui va de pair avec une « mécanique bien connue, initiée par les GAFAM, selon lesquels seule une poignée d’acteurs devraient disposer des technologies les plus avancées en raison de leur dangerosité supposée – affirmation loin de faire consensus sur le plan scientifique. En revanche, une telle posture permet à ces mêmes acteurs de justifier un contrôle accru sur ces technologies et les revenus qui en découlent, en limitant ainsi la concurrence et l’innovation ouverte ».
Vers un Independance Day ?
Pour le Conseil de l’IA, il faut donc agir, et vite. Il met en avant une approche dont nous parlons depuis des années (dans le spatial comme le numérique) : « buy european first », c’est-à-dire une préférence européenne dans la commande publique.
Autre point d’attention : les AI factories en France. Si la volonté de rééquilibrer les infrastructures critiques sur le territoire national est claire, « une vigilance particulière devra être portée sur l’allocation effective de la puissance de calcul qui, si elle s’avérait principalement fléchée vers les géants américains, ne résoudrait aucunement l’enjeu de souveraineté numérique et de la captation de la valeur produite ».
Le dernier point concerne les chercheurs. Si la France dispose d’écoles et de centres de recherche parmi les meilleurs au monde, le pays « accuse un retard croissant dans la course aux talents de l’IA, en particulier lorsqu’il s’agit de retenir ses talents ou d’en attirer d’autres ». Alors que nous étions 3e sur le nombre de « top chercheurs en IA » en 2016, nous avons glissé à la 9e place l’année dernière.
En plus de faire réagir toute la classe politique, la coupure des derniers modèles d’Anthropic remet en avant des questions de souveraineté et d’autonomie. Pour le Conseil de l’IA, « la menace sur l’autonomie numérique européenne n’est plus une hypothèse, elle est devenue une réalité tangible ».
Dans une note publiée quelques jours seulement après la coupure de Mythos 5 et de sa version pour le grand public Fable 5, le Conseil de l’IA et du Numérique évoque un « point de bascule ». Le terme est peut-être fort, mais cette coupure a été l’occasion d’éveiller les esprits sur les questions de souveraineté et de rappeler notre dépendance à des technologies américaines.
Pour le Conseil, cette suspension soudaine « révèle en réalité des tendances de fond sur l’intelligence artificielle (IA), qui s’amplifient depuis déjà un certain temps ». Il affirme que la maîtrise des dépendances technologiques doit devenir une priorité dans le numérique.
Les enjeux de souveraineté numérique, les membres du Conseil le connaissent bien, déjà par le biais de ses deux co-présidents : Anne Bouverot (ex-Orange, présidente du conseil d’administration de l’ENS) ainsi que Guillaume Poupard (ex-patron de l’ANSSI, CTO d’Orange). Sébastien Soriano et Patrick Chaize sont également membres du Conseil.
Kill switch : jour, nuit, jour, nuit…
Cette coupure des deux modèles est la matérialisation d’une menace régulièrement évoquée : un kill switch. La question se posait déjà lors de la mise en place de S3ns et Bleu, des clouds basés sur les technologies de Google et Microsoft, mais sous le contrôle et la maîtrise d’entreprises françaises. S3ns est d’ailleurs qualifié SecNumCloud par l’ANSSI, la plus haute certification.
La question était de savoir ce qu’il se passerait si Google ou Microsoft fermaient le robinet et arrêtaient d’envoyer des mises à jour. Les cloud continueraient de fonctionner, mais sans nouvelles fonctionnalités, ni correctifs de bugs ou de sécurité. C’est certainement le point le plus sensible.
Nous avions évoqué le sujet avec les deux entités. S3ns pense pouvoir tenir quelques mois, Bleu pousse à un an et pourrait proposer à ses clients des liaisons directes afin de « fonctionner en autarcie », totalement isolé d’Internet.
Les précédents : Adobe au Venezuela, le juge de la CPI Nicolas Guillou
Comme nous l’avons vu avec l’intelligence artificielle générative, le kill switch d’Anthropic a coupé les modèles à l’ensemble des clients, partout dans le monde. Ce n’est pas une première. En octobre 2019, « Adobe avait suspendu ses services – notamment l’ouverture de documents PDF – au Venezuela à la suite d’un Executive Order signé par l’administration Trump ».
Rappelons aussi le cas Nicolas Guillou, juge français de la Cour pénale internationale qui « n’a plus accès aux services numériques développés outre-Atlantique ». Le principal intéressé avait expliqué que l’Europe était (est encore) en situation de « vassalisation, dans un contexte de déclin de l’ordre mondial ».
Pour le Conseil de l’IA, « les restrictions imposées sur les deux modèles les plus avancés d’Anthropic marquent une étape supplémentaire, significative et inédite vers la généralisation pratique de ce risque ». Si le numérique est depuis toujours un enjeu de pouvoir, les LLM deviennent des actifs stratégiques.
Washington veut s’éviter un nouveau « moment DeepSeek »
Il ajoute que cette mesure « prolonge la stratégie de containment (endiguement) technologique, jusqu’ici principalement incarnée par les restrictions à l’exportation des puces NVIDIA les plus performantes » sur le marché chinois.
Le but est évident pour les États-Unis : tenter de garder cette avance pour eux afin que ses entreprises technologiques en profitent en premier, voire en exclusivité. Le gouvernement américain veut ainsi s’« éviter un nouveau « moment DeepSeek », qui avait fortement marqué les esprits à Washington ».
En bloquant les puces, les États-Unis entendent limiter les capacités d’entraînement des plus gros modèles ; avec des restrictions sur des modèles, ils veulent « limiter les risques de distillation hostile ». Selon la note, c’est grâce à la distillation que « des laboratoires chinois, comme DeepSeek, ont très certainement pu combler une grande partie de leur retard sur les modèles américains par le passé ».
Cette histoire entre en collision avec la « promesse d’une « IA pour tous » au service du bien commun », sans oublier les questions de coûts : « l’accès aux IA performantes est jusqu’à présent très largement subventionné », avec des forfaits qui seraient bien en deçà du coût réel.
Des sociétés comme OpenAI et Anthropic n’ont de cesse de vanter les performances de leurs modèles, rappelant à qui veut l‘entendre qu’ils ne doivent pas être mis entre toutes les mains (l‘Executive Order de Donald Trump va dans ce sens).
Pour le Conseil, c’est le « retour en force de la doctrine du risque catastrophique, voire existentiel, associé à l’IA »… qui va de pair avec une « mécanique bien connue, initiée par les GAFAM, selon lesquels seule une poignée d’acteurs devraient disposer des technologies les plus avancées en raison de leur dangerosité supposée – affirmation loin de faire consensus sur le plan scientifique. En revanche, une telle posture permet à ces mêmes acteurs de justifier un contrôle accru sur ces technologies et les revenus qui en découlent, en limitant ainsi la concurrence et l’innovation ouverte ».
Vers un Independance Day ?
Pour le Conseil de l’IA, il faut donc agir, et vite. Il met en avant une approche dont nous parlons depuis des années (dans le spatial comme le numérique) : « buy european first », c’est-à-dire une préférence européenne dans la commande publique.
Autre point d’attention : les AI factories en France. Si la volonté de rééquilibrer les infrastructures critiques sur le territoire national est claire, « une vigilance particulière devra être portée sur l’allocation effective de la puissance de calcul qui, si elle s’avérait principalement fléchée vers les géants américains, ne résoudrait aucunement l’enjeu de souveraineté numérique et de la captation de la valeur produite ».
Le dernier point concerne les chercheurs. Si la France dispose d’écoles et de centres de recherche parmi les meilleurs au monde, le pays « accuse un retard croissant dans la course aux talents de l’IA, en particulier lorsqu’il s’agit de retenir ses talents ou d’en attirer d’autres ». Alors que nous étions 3e sur le nombre de « top chercheurs en IA » en 2016, nous avons glissé à la 9e place l’année dernière.
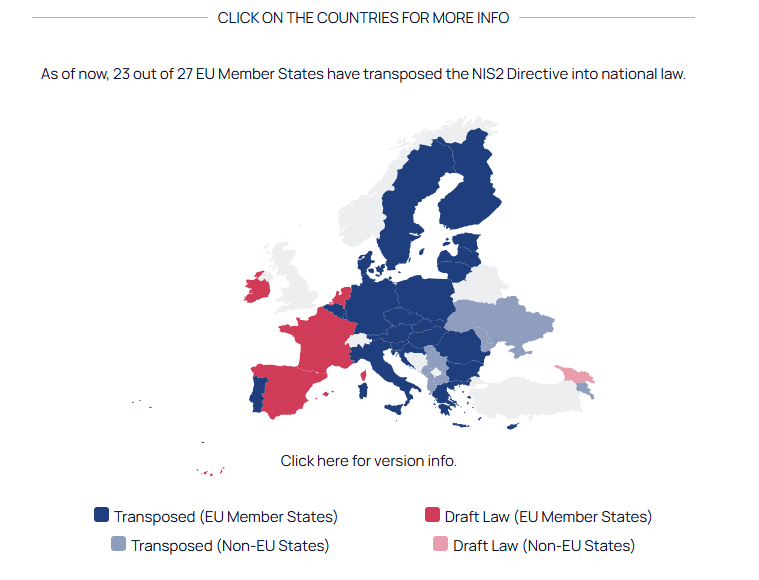
Alors que la transposition de NIS2 était prévue avant la fin de l’été, ce ne sera finalement pas le cas. Les députés sont certes convoqués pour une session extraordinaire, mais NIS2 n’est pas au programme de la trentaine de projets de loi qui va être examinée.
Date limite : octobre 2024
17 octobre 2024 : c’était la date limite pour transposer le projet de loi relatif à la résilience des infrastructures critiques et au renforcement de la cybersécurité, plus connu sous le nom NIS2. Vincent Strubel (patron de l’ANSSI) avait déjà prévenu début 2024 : « le 17 octobre, il ne va pas se passer grand-chose de spécial, en tout cas dans le domaine de NIS2 ». Effectivement, rien le 17 octobre et toujours en attente d’un vote final mi-2026.
Quelques semaines auparavant, le 9 juin, Emmanuel Macron décidait de dissoudre l’Assemblée nationale. Le gouvernement démissionnaire s’occupait alors simplement d’expédier « les affaires courantes ». Les gouvernements se sont ensuite enchaînés : Attal, Barnier et Bayrou sur les derniers mois de 2024. NIS2 n’était pas la priorité des équipes respectives.
Passage au Sénat début 2025
Début 2025, les transpositions des directives européennes NIS2, DORA et REC passaient l’étape du Sénat. Avant d’être applicable, le texte doit aussi être examiné par l’Assemblée nationale. Nous avions contacté la Commission des lois à l’époque, qui nous répondait que le gouvernement avait évoqué la fin mai (spoiler : c’est loin d’être le cas), mais que la date précise ne serait connue qu’un mois avant environ.
En juin, la Cour des comptes publiait un long rapport sur la cybersécurité et y parlait évidemment de NIS2. Elle souhaitait à ce sujet que l’ANSSI évolue davantage vers une logique de contrôle et de sanction. Vincent Strubel a déjà fait part de son opposition à plusieurs reprises, affirmant son rôle de cyber-pompier et pas cyber-gendarme: « Un cyber pompier, ça ne remplit pas un PV en même temps que ça a éteint le feu ».
En commission spéciale de l’Assemblée nationale en septembre 2025
En septembre 2025, le projet de loi était adopté par une commission spéciale de l’Assemblée nationale. Philippe Latombe, président de cette commission, ajoutait au passage un amendement afin de sanctuariser le chiffrement de bout en bout (dans l’article 16 bis). Ne restait donc que l’examen final du texte et son vote en séance publique.
Quelques semaines plus tard, toujours sans passage à l’Assemblée nationale (ni calendrier prévisionnel), l’ANSSI ouvrait son bureau de pré-enregistrement. C’était « la première brique de l’entrée en vigueur de NIS 2 et un premier pas pour les entités dans le respect de leurs obligations ».
Blocage début 2025 : il faut choisir entre « plusieurs mauvaises solutions »
En février, retournement de situation : la DGSI était accusée par deux députés (les présidents de la commission spéciale) de bloquer l’adoption de la loi. « Je le dis de façon claire et je ne vais pas me faire de copains en disant ça mais c’est pas grave, la DGSI et les services veulent la fin de l’article 16 bis », expliquait Philippe Latombe en conférence de presse.
En mars, l’ANSSI publiait son REférentiel CYber France (ReCyF), en version bêta. Il « liste les mesures recommandées par l’ANSSI pour atteindre les objectifs de sécurité fixés par NIS2 ». Vincent Strubel expliquait qu’il « restera un document de travail jusqu’à la transposition de NIS2 en droit français, mais il ne faut surtout pas attendre pour le mettre en œuvre ».
En avril, Vincent Strubel revenait une nouvelle fois sur ce sujet et expliquait l’impasse actuelle : « On est face à deux impératifs de même valeur : celui de la protection de la vie privée et de la sécurité nationale […]. S’il y avait une solution magique qui permette de les préserver ensemble sans impact sur l’un ou sur l’autre, elle aurait déjà été trouvée… In fine, cela relèvera d’une décision politique du législateur, qui sera un choix entre plusieurs mauvaises solutions ».
Dix-huit mois après la date butoir de transposition, la Commission supérieure du numérique et des postes (CSNP) venait mettre son grain de sel. Elle expliquait que ce retard venait « d’un point de clivage politique : l’article 16 bis, introduit au Sénat afin de consacrer dans la loi la protection du chiffrement et d’interdire l’imposition de dispositifs de portes dérobées (« backdoors ») aux messageries instantanées, fait l’objet d’une opposition du gouvernement ».
Toujours selon la Commission, le programme législatif du gouvernement « prévoit désormais un examen du texte en juillet 2026, et ce sous réserve de la convocation d’une session extraordinaire ». Caramba, encore raté.
NIS2 aux abonnés absents de la session extraordinaire de juillet
Comme le rapporte Éric Bothorel sur X, un décret a bien été publié au Journal officiel pour une convocation du Parlement en session extraordinaire à partir du mercredi 1ᵉʳ juillet 2026. Les députés devraient siéger jusqu’à la semaine du 20 juillet incluse pour examiner plusieurs textes.
L’ordre du jour comprend une trentaine d’examens sur des projets et propositions de loi. Mais, on a beau chercher, rien sur NIS2 ou le projet de loi relatif à la résilience des infrastructures critiques et au renforcement de la cybersécurité (le mot cyber n’apparait pas dans le décret).
On se souviendra d’une phrase de Vincent Strubel aux Assises de la cybersécurité de Monaco en octobre 2025 à propos de l’ultime vote de la transposition de NIS2 en droit français : c’est « une étape indispensable et essentielle, mais ce n’est qu’une étape et pas la plus difficile ». Pas si sûr.
Alors que la transposition de NIS2 était prévue avant la fin de l’été, ce ne sera finalement pas le cas. Les députés sont certes convoqués pour une session extraordinaire, mais NIS2 n’est pas au programme de la trentaine de projets de loi qui va être examinée.
Date limite : octobre 2024
17 octobre 2024 : c’était la date limite pour transposer le projet de loi relatif à la résilience des infrastructures critiques et au renforcement de la cybersécurité, plus connu sous le nom NIS2. Vincent Strubel (patron de l’ANSSI) avait déjà prévenu début 2024 : « le 17 octobre, il ne va pas se passer grand-chose de spécial, en tout cas dans le domaine de NIS2 ». Effectivement, rien le 17 octobre et toujours en attente d’un vote final mi-2026.
Quelques semaines auparavant, le 9 juin, Emmanuel Macron décidait de dissoudre l’Assemblée nationale. Le gouvernement démissionnaire s’occupait alors simplement d’expédier « les affaires courantes ». Les gouvernements se sont ensuite enchaînés : Attal, Barnier et Bayrou sur les derniers mois de 2024. NIS2 n’était pas la priorité des équipes respectives.
Passage au Sénat début 2025
Début 2025, les transpositions des directives européennes NIS2, DORA et REC passaient l’étape du Sénat. Avant d’être applicable, le texte doit aussi être examiné par l’Assemblée nationale. Nous avions contacté la Commission des lois à l’époque, qui nous répondait que le gouvernement avait évoqué la fin mai (spoiler : c’est loin d’être le cas), mais que la date précise ne serait connue qu’un mois avant environ.
En juin, la Cour des comptes publiait un long rapport sur la cybersécurité et y parlait évidemment de NIS2. Elle souhaitait à ce sujet que l’ANSSI évolue davantage vers une logique de contrôle et de sanction. Vincent Strubel a déjà fait part de son opposition à plusieurs reprises, affirmant son rôle de cyber-pompier et pas cyber-gendarme: « Un cyber pompier, ça ne remplit pas un PV en même temps que ça a éteint le feu ».
En commission spéciale de l’Assemblée nationale en septembre 2025
En septembre 2025, le projet de loi était adopté par une commission spéciale de l’Assemblée nationale. Philippe Latombe, président de cette commission, ajoutait au passage un amendement afin de sanctuariser le chiffrement de bout en bout (dans l’article 16 bis). Ne restait donc que l’examen final du texte et son vote en séance publique.
Quelques semaines plus tard, toujours sans passage à l’Assemblée nationale (ni calendrier prévisionnel), l’ANSSI ouvrait son bureau de pré-enregistrement. C’était « la première brique de l’entrée en vigueur de NIS 2 et un premier pas pour les entités dans le respect de leurs obligations ».
Blocage début 2025 : il faut choisir entre « plusieurs mauvaises solutions »
En février, retournement de situation : la DGSI était accusée par deux députés (les présidents de la commission spéciale) de bloquer l’adoption de la loi. « Je le dis de façon claire et je ne vais pas me faire de copains en disant ça mais c’est pas grave, la DGSI et les services veulent la fin de l’article 16 bis », expliquait Philippe Latombe en conférence de presse.
En mars, l’ANSSI publiait son REférentiel CYber France (ReCyF), en version bêta. Il « liste les mesures recommandées par l’ANSSI pour atteindre les objectifs de sécurité fixés par NIS2 ». Vincent Strubel expliquait qu’il « restera un document de travail jusqu’à la transposition de NIS2 en droit français, mais il ne faut surtout pas attendre pour le mettre en œuvre ».
En avril, Vincent Strubel revenait une nouvelle fois sur ce sujet et expliquait l’impasse actuelle : « On est face à deux impératifs de même valeur : celui de la protection de la vie privée et de la sécurité nationale […]. S’il y avait une solution magique qui permette de les préserver ensemble sans impact sur l’un ou sur l’autre, elle aurait déjà été trouvée… In fine, cela relèvera d’une décision politique du législateur, qui sera un choix entre plusieurs mauvaises solutions ».
Dix-huit mois après la date butoir de transposition, la Commission supérieure du numérique et des postes (CSNP) venait mettre son grain de sel. Elle expliquait que ce retard venait « d’un point de clivage politique : l’article 16 bis, introduit au Sénat afin de consacrer dans la loi la protection du chiffrement et d’interdire l’imposition de dispositifs de portes dérobées (« backdoors ») aux messageries instantanées, fait l’objet d’une opposition du gouvernement ».
Toujours selon la Commission, le programme législatif du gouvernement « prévoit désormais un examen du texte en juillet 2026, et ce sous réserve de la convocation d’une session extraordinaire ». Caramba, encore raté.
NIS2 aux abonnés absents de la session extraordinaire de juillet
Comme le rapporte Éric Bothorel sur X, un décret a bien été publié au Journal officiel pour une convocation du Parlement en session extraordinaire à partir du mercredi 1ᵉʳ juillet 2026. Les députés devraient siéger jusqu’à la semaine du 20 juillet incluse pour examiner plusieurs textes.
L’ordre du jour comprend une trentaine d’examens sur des projets et propositions de loi. Mais, on a beau chercher, rien sur NIS2 ou le projet de loi relatif à la résilience des infrastructures critiques et au renforcement de la cybersécurité (le mot cyber n’apparait pas dans le décret).
On se souviendra d’une phrase de Vincent Strubel aux Assises de la cybersécurité de Monaco en octobre 2025 à propos de l’ultime vote de la transposition de NIS2 en droit français : c’est « une étape indispensable et essentielle, mais ce n’est qu’une étape et pas la plus difficile ». Pas si sûr.
Oracle et Google proposent des VM gratuites, sans limite de durée. Attention, cela ne veut pas dire qu’elles seront toujours gratuites (ce brief en est le parfait exemple), juste qu’il n’y a pas de date de fin de validité pour le moment, ni de limite de crédits.
Nous avons expliqué comment installer Vaultwarden sur une VM gratuite de Google et ainsi profiter d’un gestionnaire de mots de passe sur l’ensemble de vos terminaux, sans frais. Dans notre cas, après plusieurs mois d’une utilisation classique (trois ordinateurs, deux smartphones), la facture reste bien à 0 euro.
Nous évoquions aussi le cas d’Oracle avec son plan « Always Free », comprenant deux offres gratuites. La première, une micro instance (AMD) avec jusqu’à deux VM.Standard.E2.1.Micro, chacune avec 1/8e d’OCPU et 1 Go de mémoire.
La seconde, baptisée OCI Ampere A1 Compute instances (Arm), donnait accès (lors de notre test en avril) à 3 000 heures OCPU et 18 000 heures de Go de mémoire par mois. On vous épargne les calculs, mais cela était équivalent à un maximum de 4 OCPU et 24 Go de mémoire par mois.
Rien ne change pour l’instance Always Free AMD, mais Oracle divise par deux le CPU et la mémoire d’OCI Ampere 1 : « toutes les locations reçoivent gratuitement les 1 500 premières heures d’OCPU et les 9 000 Go par mois […] Pour les locations Toujours gratuit, cela équivaut à 2 OCPU et 12 Go de mémoire ». Pas de changement sur les transferts avec 10 To de données sortantes par mois.
Sur Reddit, plusieurs utilisateurs indiquent ne pas avoir eu d’email d’Oracle pour prévenir du changement, alors que la nouvelle politique est entrée en vigueur hier, avec donc une facturation si vous dépassez les nouvelles limites.
Oracle et Google proposent des VM gratuites, sans limite de durée. Attention, cela ne veut pas dire qu’elles seront toujours gratuites (ce brief en est le parfait exemple), juste qu’il n’y a pas de date de fin de validité pour le moment, ni de limite de crédits.
Nous avons expliqué comment installer Vaultwarden sur une VM gratuite de Google et ainsi profiter d’un gestionnaire de mots de passe sur l’ensemble de vos terminaux, sans frais. Dans notre cas, après plusieurs mois d’une utilisation classique (trois ordinateurs, deux smartphones), la facture reste bien à 0 euro.
Nous évoquions aussi le cas d’Oracle avec son plan « Always Free », comprenant deux offres gratuites. La première, une micro instance (AMD) avec jusqu’à deux VM.Standard.E2.1.Micro, chacune avec 1/8e d’OCPU et 1 Go de mémoire.
La seconde, baptisée OCI Ampere A1 Compute instances (Arm), donnait accès (lors de notre test en avril) à 3 000 heures OCPU et 18 000 heures de Go de mémoire par mois. On vous épargne les calculs, mais cela était équivalent à un maximum de 4 OCPU et 24 Go de mémoire par mois.
Rien ne change pour l’instance Always Free AMD, mais Oracle divise par deux le CPU et la mémoire d’OCI Ampere 1 : « toutes les locations reçoivent gratuitement les 1 500 premières heures d’OCPU et les 9 000 Go par mois […] Pour les locations Toujours gratuit, cela équivaut à 2 OCPU et 12 Go de mémoire ». Pas de changement sur les transferts avec 10 To de données sortantes par mois.
Sur Reddit, plusieurs utilisateurs indiquent ne pas avoir eu d’email d’Oracle pour prévenir du changement, alors que la nouvelle politique est entrée en vigueur hier, avec donc une facturation si vous dépassez les nouvelles limites.




















 Freedom to Collaborate.
Freedom to Collaborate.